 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Training for Text-to-Image Synthesis using Dual-Text Embeddings
Feb 03, 2025Text-to-Image (T2I) synthesis is a challenging task that requires modeling complex interactions between two modalities ( i.e., text and image). A common framework adopted in recent state-of-the-art approaches to achieving such multimodal interactions is to bootstrap the learning process with pre-trained image-aligned text embeddings trained using contrastive loss. Furthermore, these embeddings are typically trained generically and reused across various synthesis models. In contrast, we explore an approach to learning text embeddings specifically tailored to the T2I synthesis network, trained in an end-to-end fashion. Further, we combine generative and contrastive training and use two embeddings, one optimized to enhance the photo-realism of the generated images, and the other seeking to capture text-to-image alignment. A comprehensive set of experiments on three text-to-image benchmark datasets (Oxford-102, Caltech-UCSD, and MS-COCO) reveal that having two separate embeddings gives better results than using a shared one and that such an approach performs favourably in comparison with methods that use text representations from a pre-trained text encoder trained using a discriminative approach. Finally, we demonstrate that such learned embeddings can be used in other contexts as well, such as text-to-image manipulation.
MOVESe: MOVablE and Moving LiDAR Scene Segmentation with Improved Navigation in Seg-label free settings
Jun 26, 2023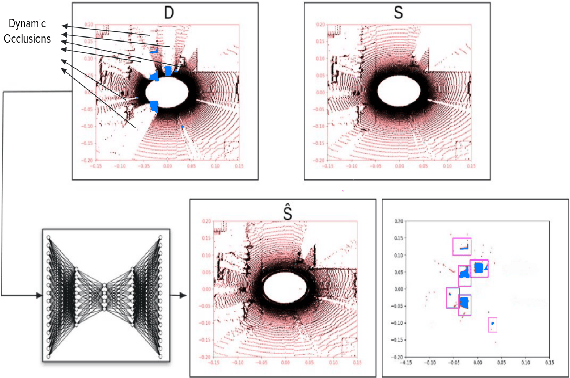

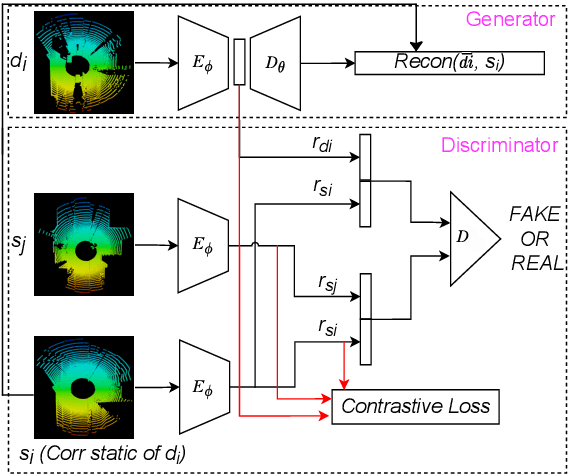

Accurate detection of movable and moving objects in LiDAR is of vital importance for navigation. Most existing works focus on extracting and removing moving objects during navigation. Movable objects like pedestrians, parked vehicles, etc. although static may move in the future. This leads to erroneous navigation and accidents. In such cases, it becomes necessary to detect potentially movable objects. To this end, we present a learning-based approach that segments movable and moving objects by generating static parts of scenes that are otherwise occluded. Our model performs superior to existing baselines on static LiDAR reconstructions using 3 datasets including a challenging sparse industrial dataset. We achieve this without the assistance of any segmentation labels because such labels might not always be available for less popular yet important settings like industrial environments. The non-movable static parts of the scene generated by our model are of vital importance for downstream navigation for SLAM. The movable objects detected by our model can be fed to a downstream 3D detector for aiding navigation. Though we do not use segmentation, we evaluate our method against navigation baselines that use it to remove dynamic objects for SLAM. Through extensive experiments on several datasets, we showcase that our model surpasses these baselines on navigation.
Non-linear Motion Estimation for Video Frame Interpolation using Space-time Convolutions
Jan 27, 2022Video frame interpolation aims to synthesize one or multiple frames between two consecutive frames in a video. It has a wide range of applications including slow-motion video generation, frame-rate up-scaling and developing video codecs. Some older works tackled this problem by assuming per-pixel linear motion between video frames. However, objects often follow a non-linear motion pattern in the real domain and some recent methods attempt to model per-pixel motion by non-linear models (e.g., quadratic). A quadratic model can also be inaccurate, especially in the case of motion discontinuities over time (i.e. sudden jerks) and occlusions, where some of the flow information may be invalid or inaccurate. In our paper, we propose to approximate the per-pixel motion using a space-time convolution network that is able to adaptively select the motion model to be used. Specifically, we are able to softly switch between a linear and a quadratic model. Towards this end, we use an end-to-end 3D CNN encoder-decoder architecture over bidirectional optical flows and occlusion maps to estimate the non-linear motion model of each pixel. Further, a motion refinement module is employed to refine the non-linear motion and the interpolated frames are estimated by a simple warping of the neighboring frames with the estimated per-pixel motion. Through a set of comprehensive experiments, we validate the effectiveness of our model and show that our method outperforms state-of-the-art algorithms on four datasets (Vimeo, DAVIS, HD and GoPro).
Co-segmentation Inspired Attention Module for Video-based Computer Vision Tasks
Nov 25, 2021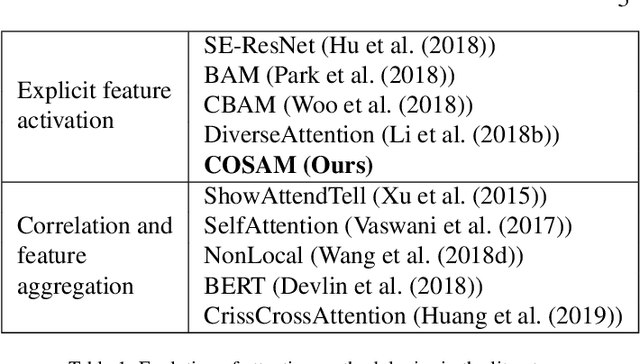
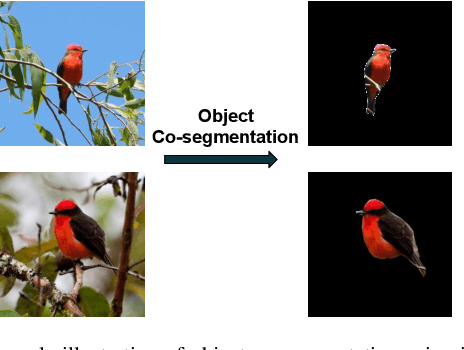

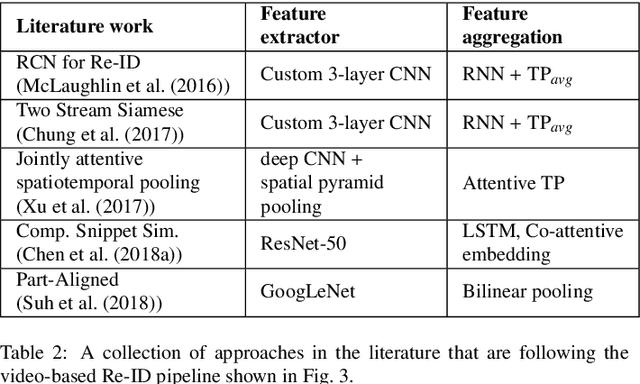
Video-based computer vision tasks can benefit from the estimation of the salient regions and interactions between those regions. Traditionally, this has been done by identifying the object regions in the images by utilizing pre-trained models to perform object detection, object segmentation, and/or object pose estimation. Though using pre-trained models seems to be a viable approach, it is infeasible in practice due to the need for exhaustive annotation of object categories, domain gap between datasets, and bias present in pre-trained models. To overcome these downsides, we propose to utilize the common rationale that a sequence of video frames capture a set of common objects and interactions between them, thus a notion of co-segmentation between the video frame features may equip the model with the ability to automatically focus on salient regions and improve underlying task's performance in an end-to-end manner. In this regard, we propose a generic module called "Co-Segmentation Activation Module" (COSAM) that can be plugged into any CNN to promote the notion of co-segmentation based attention among a sequence of video frame features. We show the application of COSAM in three video-based tasks namely: 1) Video-based person re-ID, 2) Video captioning, & 3) Video action classification, and demonstrate that COSAM is able to capture salient regions in the video frames, thus leading to notable performance improvements along with interpretable attention maps.
On the Significance of Question Encoder Sequence Model in the Out-of-Distribution Performance in Visual Question Answering
Aug 28, 2021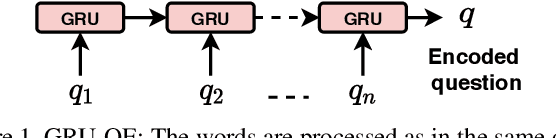
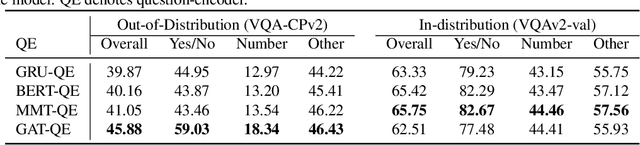

Generalizing beyond the experiences has a significant role in developing practical AI systems. It has been shown that current Visual Question Answering (VQA) models are over-dependent on the language-priors (spurious correlations between question-types and their most frequent answers) from the train set and pose poor performance on Out-of-Distribution (OOD) test sets. This conduct limits their generalizability and restricts them from being utilized in real-world situations. This paper shows that the sequence model architecture used in the question-encoder has a significant role in the generalizability of VQA models. To demonstrate this, we performed a detailed analysis of various existing RNN-based and Transformer-based question-encoders, and along, we proposed a novel Graph attention network (GAT)-based question-encoder. Our study found that a better choice of sequence model in the question-encoder improves the generalizability of VQA models even without using any additional relatively complex bias-mitigation approaches.
Face Age Progression With Attribute Manipulation
Jun 14, 2021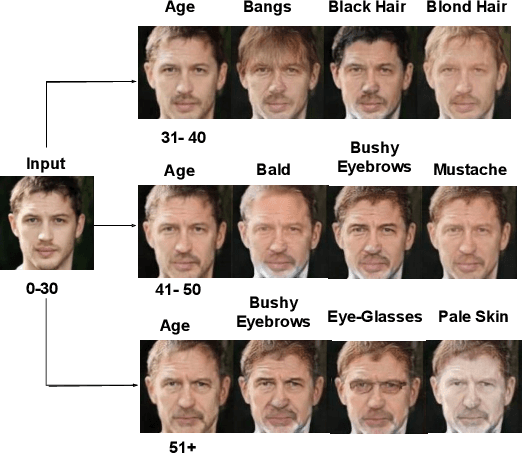
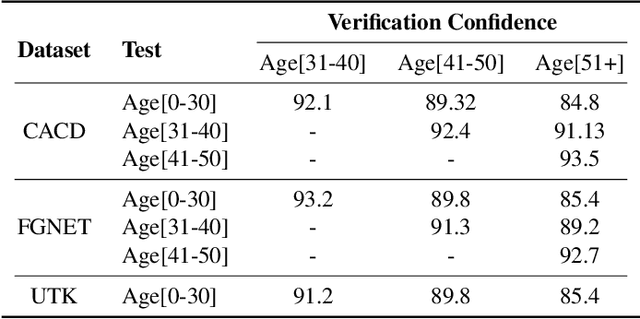
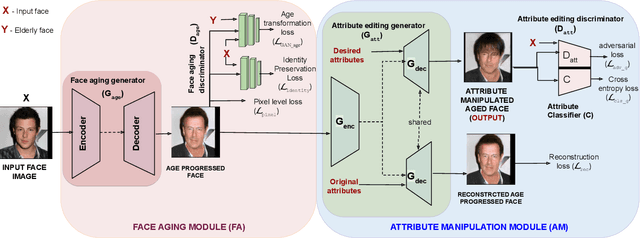
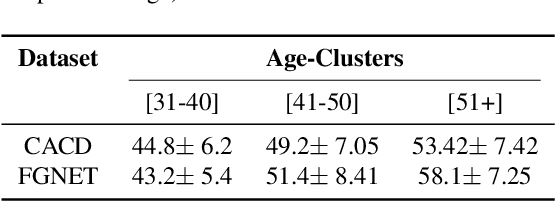
Face is one of the predominant means of person recognition. In the process of ageing, human face is prone to many factors such as time, attributes, weather and other subject specific variations. The impact of these factors were not well studied in the literature of face aging. In this paper, we propose a novel holistic model in this regard viz., ``Face Age progression With Attribute Manipulation (FAWAM)", i.e. generating face images at different ages while simultaneously varying attributes and other subject specific characteristics. We address the task in a bottom-up manner, as two submodules i.e. face age progression and face attribute manipulation. For face aging, we use an attribute-conscious face aging model with a pyramidal generative adversarial network that can model age-specific facial changes while maintaining intrinsic subject specific characteristics. For facial attribute manipulation, the age processed facial image is manipulated with desired attributes while preserving other details unchanged, leveraging an attribute generative adversarial network architecture. We conduct extensive analysis in standard large scale datasets and our model achieves significant performance both quantitatively and qualitatively.
Efficient Space-time Video Super Resolution using Low-Resolution Flow and Mask Upsampling
May 03, 2021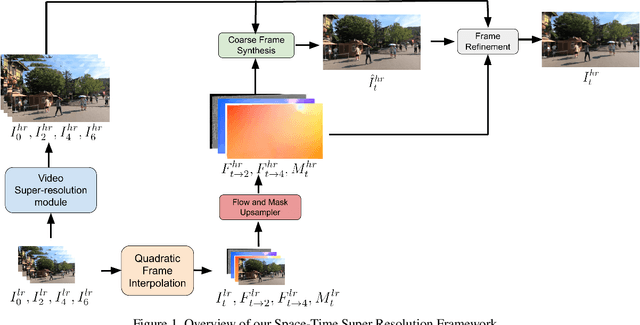
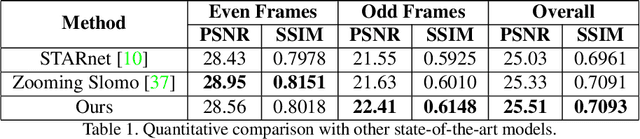

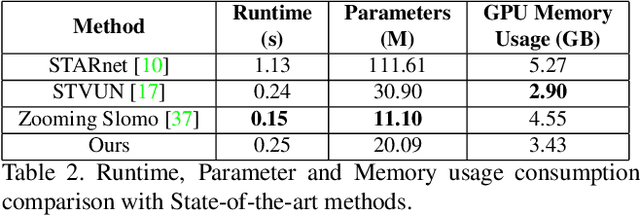
This paper explores an efficient solution for Space-time Super-Resolution, aiming to generate High-resolution Slow-motion videos from Low Resolution and Low Frame rate videos. A simplistic solution is the sequential running of Video Super Resolution and Video Frame interpolation models. However, this type of solutions are memory inefficient, have high inference time, and could not make the proper use of space-time relation property. To this extent, we first interpolate in LR space using quadratic modeling. Input LR frames are super-resolved using a state-of-the-art Video Super-Resolution method. Flowmaps and blending mask which are used to synthesize LR interpolated frame is reused in HR space using bilinear upsampling. This leads to a coarse estimate of HR intermediate frame which often contains artifacts along motion boundaries. We use a refinement network to improve the quality of HR intermediate frame via residual learning. Our model is lightweight and performs better than current state-of-the-art models in REDS STSR Validation set.
Unsupervised Domain Adaptive Knowledge Distillation for Semantic Segmentation
Nov 03, 2020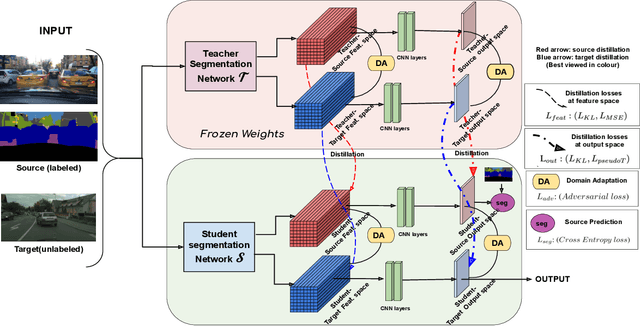

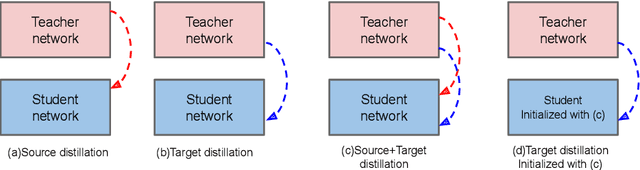

Practical autonomous driving systems face two crucial challenges: memory constraints and domain gap issues. We present an approach to learn domain adaptive knowledge in models with limited memory, thus bestowing the model with the ability to deal with these issues in a comprehensive manner. We delve into this in the context of unsupervised domain-adaptive semantic segmentation and propose a multi-level distillation strategy to effectively distil knowledge at different levels. Further, we introduce a cross entropy loss that leverages pseudo labels from the teacher. These pseudo teacher labels play a multifaceted role towards: (i) knowledge distillation from the teacher network to the student network & (ii) serving as a proxy for the ground truth for target domain images, where the problem is completely unsupervised. We introduce four paradigms for distilling domain adaptive knowledge and carry out extensive experiments and ablation studies on real-to-real and synthetic-to-real scenarios. Our experiments demonstrate the profound success of our proposed method.
MARNet: Multi-Abstraction Refinement Network for 3D Point Cloud Analysis
Nov 02, 2020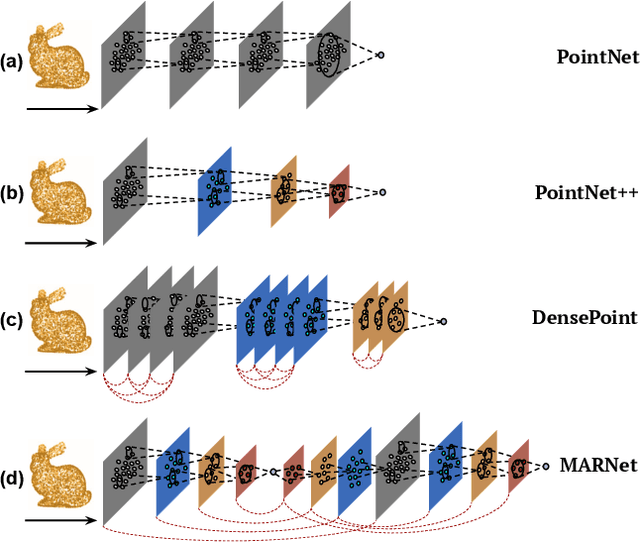
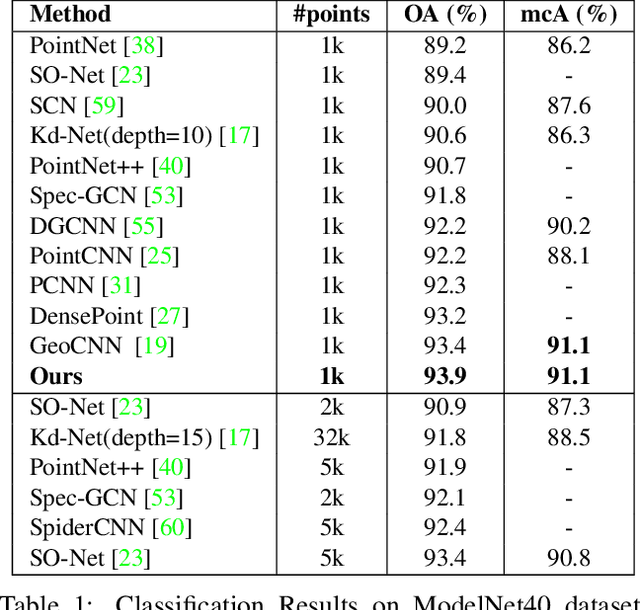
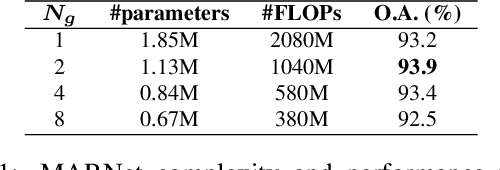
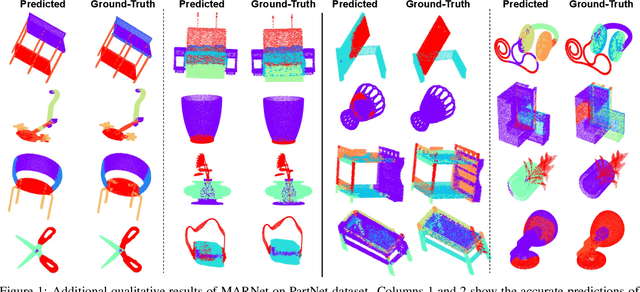
Representation learning from 3D point clouds is challenging due to their inherent nature of permutation invariance and irregular distribution in space. Existing deep learning methods follow a hierarchical feature extraction paradigm in which high-level abstract features are derived from low-level features. However, they fail to exploit different granularity of information due to the limited interaction between these features. To this end, we propose Multi-Abstraction Refinement Network (MARNet) that ensures an effective exchange of information between multi-level features to gain local and global contextual cues while effectively preserving them till the final layer. We empirically show the effectiveness of MARNet in terms of state-of-the-art results on two challenging tasks: Shape classification and Coarse-to-fine grained semantic segmentation. MARNet significantly improves the classification performance by 2% over the baseline and outperforms the state-of-the-art methods on semantic segmentation task.
WDN: A Wide and Deep Network to Divide-and-Conquer Image Super-resolution
Oct 07, 2020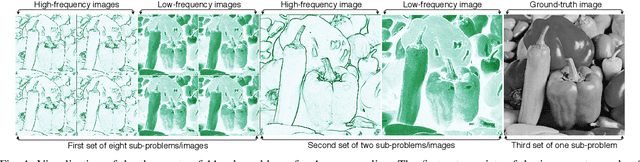
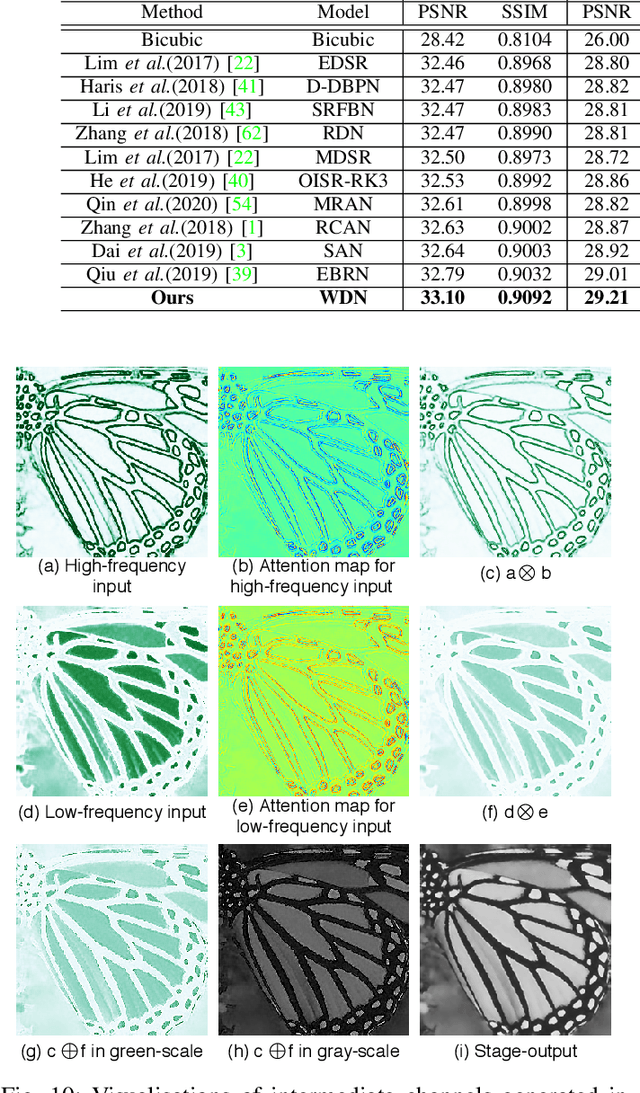

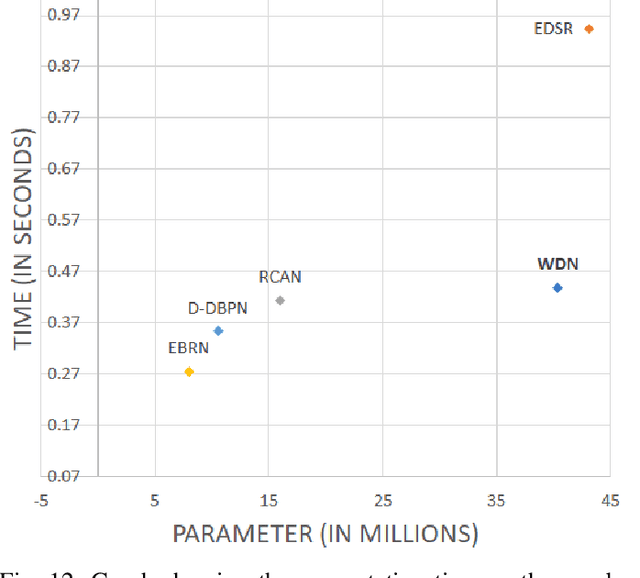
Divide and conquer is an established algorithm design paradigm that has proven itself to solve a variety of problems efficiently. However, it is yet to be fully explored in solving problems with a neural network, particularly the problem of image super-resolution. In this work, we propose an approach to divide the problem of image super-resolution into multiple sub-problems and then solve/conquer them with the help of a neural network. Unlike a typical deep neural network, we design an alternate network architecture that is much wider (along with being deeper) than existing networks and is specially designed to implement the divide-and-conquer design paradigm with a neural network. Additionally, a technique to calibrate the intensities of feature map pixels is being introduced. Extensive experimentation on five datasets reveals that our approach towards the problem and the proposed architecture generate better and sharper results than current state-of-the-art methods.