 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Significance of Question Encoder Sequence Model in the Out-of-Distribution Performance in Visual Question Answering
Paper and Code
Aug 28, 2021
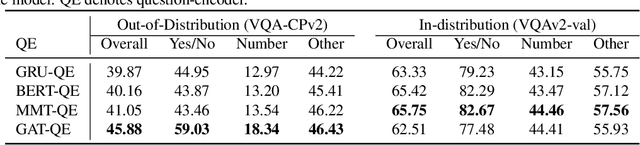
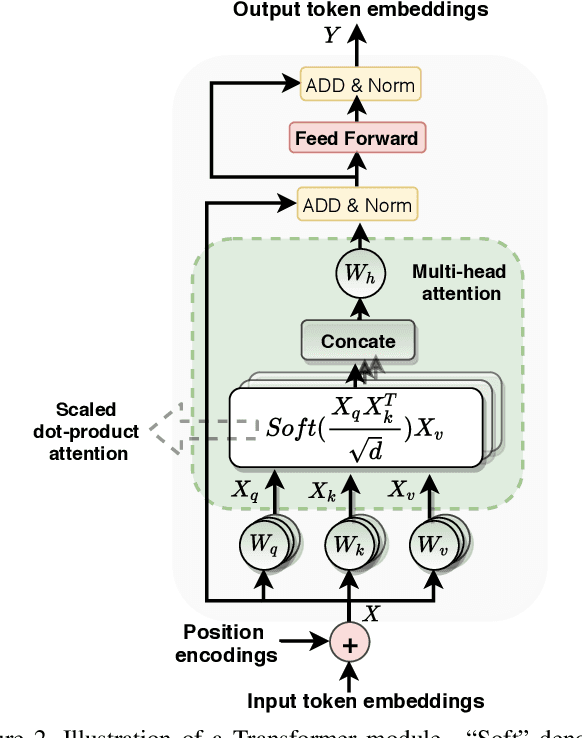

Generalizing beyond the experiences has a significant role in developing practical AI systems. It has been shown that current Visual Question Answering (VQA) models are over-dependent on the language-priors (spurious correlations between question-types and their most frequent answers) from the train set and pose poor performance on Out-of-Distribution (OOD) test sets. This conduct limits their generalizability and restricts them from being utilized in real-world situations. This paper shows that the sequence model architecture used in the question-encoder has a significant role in the generalizability of VQA models. To demonstrate this, we performed a detailed analysis of various existing RNN-based and Transformer-based question-encoders, and along, we proposed a novel Graph attention network (GAT)-based question-encoder. Our study found that a better choice of sequence model in the question-encoder improves the generalizability of VQA models even without using any additional relatively complex bias-mitigation approaches.