 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Referring Expressions: Scenario Comprehension Visual Grounding
Apr 02, 2026Existing visual grounding benchmarks primarily evaluate alignment between image regions and literal referring expressions, where models can often succeed by matching a prominent named category. We explore a complementary and more challenging setting of scenario-based visual grounding, where the target must be inferred from roles, intentions, and relational context rather than explicit naming. We introduce Referring Scenario Comprehension (RSC), a benchmark designed for this setting. The queries in this benchmark are paragraph-length texts that describe object roles, user goals, and contextual cues, including deliberate references to distractor objects that often require deep understanding to resolve. Each instance is annotated with interpretable difficulty tags for uniqueness, clutter, size, overlap, and position which expose distinct failure modes and support fine-grained analysis. RSC contains approximately 31k training examples, 4k in-domain test examples, and a 3k out-of-distribution split with unseen object categories. We further propose ScenGround, a curriculum reasoning method serving as a reference point for this setting, combining supervised warm-starting with difficulty-aware reinforcement learning. Experiments show that scenario-based queries expose systematic failures in current models that standard benchmarks do not reveal, and that curriculum training improves performance on challenging slices and transfers to standard benchmarks.
Cinéaste: A Fine-grained Contextual Movie Question Answering Benchmark
Sep 17, 2025While recent advancements in vision-language models have improved video understanding, diagnosing their capacity for deep, narrative comprehension remains a challenge. Existing benchmarks often test short-clip recognition or use template-based questions, leaving a critical gap in evaluating fine-grained reasoning over long-form narrative content. To address these gaps, we introduce $\mathsf{Cin\acute{e}aste}$, a comprehensive benchmark for long-form movie understanding. Our dataset comprises 3,119 multiple-choice question-answer pairs derived from 1,805 scenes across 200 diverse movies, spanning five novel fine-grained contextual reasoning categories. We use GPT-4o to generate diverse, context-rich questions by integrating visual descriptions, captions, scene titles, and summaries, which require deep narrative understanding. To ensure high-quality evaluation, our pipeline incorporates a two-stage filtering process: Context-Independence filtering ensures questions require video context, while Contextual Veracity filtering validates factual consistency against the movie content, mitigating hallucinations. Experiments show that existing MLLMs struggle on $\mathsf{Cin\acute{e}aste}$; our analysis reveals that long-range temporal reasoning is a primary bottleneck, with the top open-source model achieving only 63.15\% accuracy. This underscores significant challenges in fine-grained contextual understanding and the need for advancements in long-form movie comprehension.
StepAL: Step-aware Active Learning for Cataract Surgical Videos
Jul 29, 2025Active learning (AL) can reduce annotation costs in surgical video analysis while maintaining model performance. However, traditional AL methods, developed for images or short video clips, are suboptimal for surgical step recognition due to inter-step dependencies within long, untrimmed surgical videos. These methods typically select individual frames or clips for labeling, which is ineffective for surgical videos where annotators require the context of the entire video for annotation. To address this, we propose StepAL, an active learning framework designed for full video selection in surgical step recognition. StepAL integrates a step-aware feature representation, which leverages pseudo-labels to capture the distribution of predicted steps within each video, with an entropy-weighted clustering strategy. This combination prioritizes videos that are both uncertain and exhibit diverse step compositions for annotation. Experiments on two cataract surgery datasets (Cataract-1k and Cataract-101) demonstrate that StepAL consistently outperforms existing active learning approaches, achieving higher accuracy in step recognition with fewer labeled videos. StepAL offers an effective approach for efficient surgical video analysis, reducing the annotation burden in developing computer-assisted surgical systems.
$\mathsf{CSMAE~}$:~Cataract Surgical Masked Autoencoder (MAE) based Pre-training
Feb 12, 2025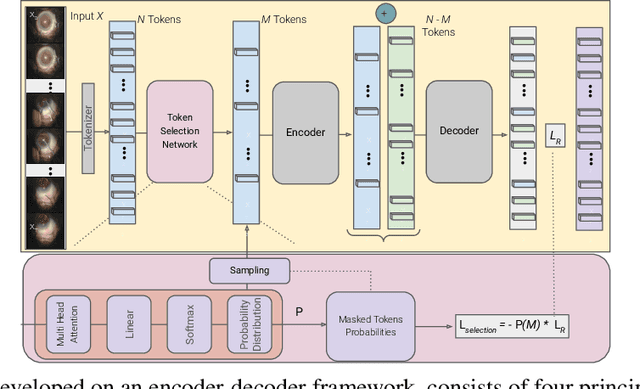
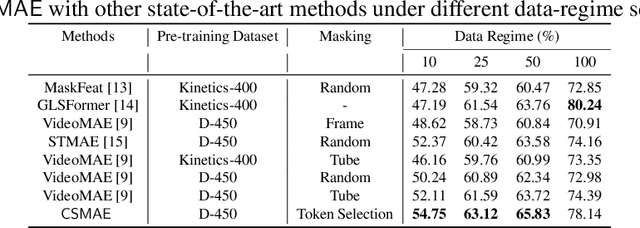


Automated analysis of surgical videos is crucial for improving surgical training, workflow optimization, and postoperative assessment. We introduce a CSMAE, Masked Autoencoder (MAE)-based pretraining approach, specifically developed for Cataract Surgery video analysis, where instead of randomly selecting tokens for masking, they are selected based on the spatiotemporal importance of the token. We created a large dataset of cataract surgery videos to improve the model's learning efficiency and expand its robustness in low-data regimes. Our pre-trained model can be easily adapted for specific downstream tasks via fine-tuning, serving as a robust backbone for further analysis. Through rigorous testing on a downstream step-recognition task on two Cataract Surgery video datasets, D99 and Cataract-101, our approach surpasses current state-of-the-art self-supervised pretraining and adapter-based transfer learning methods by a significant margin. This advancement not only demonstrates the potential of our MAE-based pretraining in the field of surgical video analysis but also sets a new benchmark for future research.
GLSFormer: Gated - Long, Short Sequence Transformer for Step Recognition in Surgical Videos
Jul 20, 2023Automated surgical step recognition is an important task that can significantly improve patient safety and decision-making during surgeries. Existing state-of-the-art methods for surgical step recognition either rely on separate, multi-stage modeling of spatial and temporal information or operate on short-range temporal resolution when learned jointly. However, the benefits of joint modeling of spatio-temporal features and long-range information are not taken in account. In this paper, we propose a vision transformer-based approach to jointly learn spatio-temporal features directly from sequence of frame-level patches. Our method incorporates a gated-temporal attention mechanism that intelligently combines short-term and long-term spatio-temporal feature representations. We extensively evaluate our approach on two cataract surgery video datasets, namely Cataract-101 and D99, and demonstrate superior performance compared to various state-of-the-art methods. These results validate the suitability of our proposed approach for automated surgical step recognition. Our code is released at: https://github.com/nisargshah1999/GLSFormer
ALAP-AE: As-Lite-as-Possible Auto-Encoder
Mar 19, 2022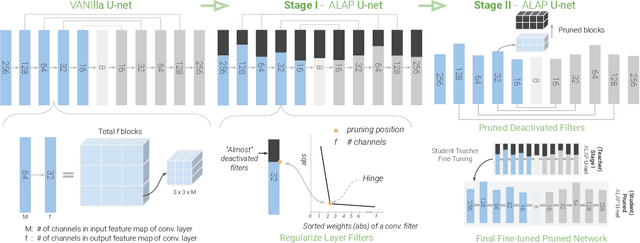
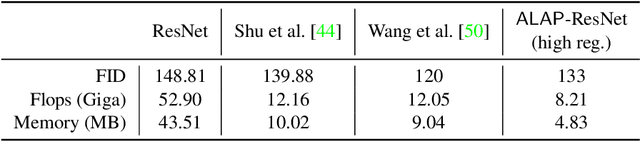
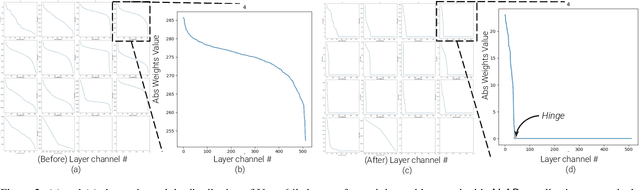
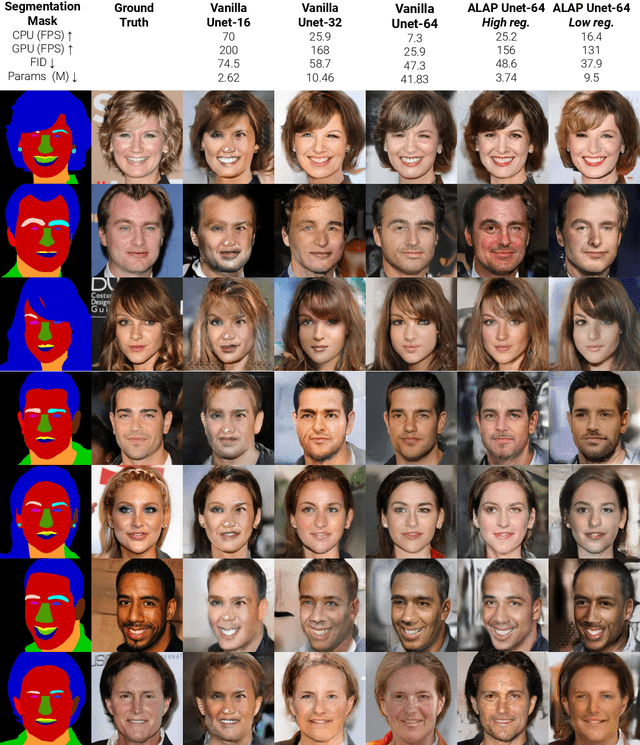
We present a novel algorithm to reduce tensor compute required by a conditional image generation autoencoder and make it as-lite-as-possible, without sacrificing quality of photo-realistic image generation. Our method is device agnostic, and can optimize an autoencoder for a given CPU-only, GPU compute device(s) in about normal time it takes to train an autoencoder on a generic workstation. We achieve this via a two-stage novel strategy where, first, we condense the channel weights, such that, as few as possible channels are used. Then, we prune the nearly zeroed out weight activations, and fine-tune this lite autoencoder. To maintain image quality, fine-tuning is done via student-teacher training, where we reuse the condensed autoencoder as the teacher. We show performance gains for various conditional image generation tasks: segmentation mask to face images, face images to cartoonization, and finally CycleGAN-based model on horse to zebra dataset over multiple compute devices. We perform various ablation studies to justify the claims and design choices, and achieve real-time versions of various autoencoders on CPU-only devices while maintaining image quality, thus enabling at-scale deployment of such autoencoders.
Can No-reference features help in Full-reference image quality estimation?
Mar 02, 2022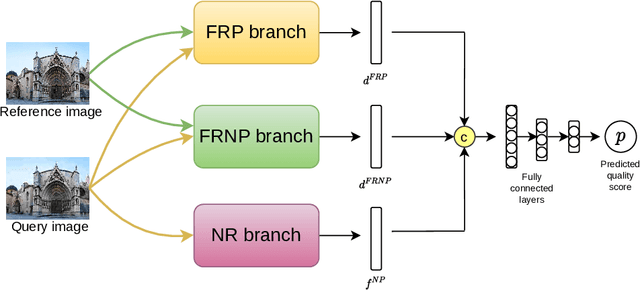
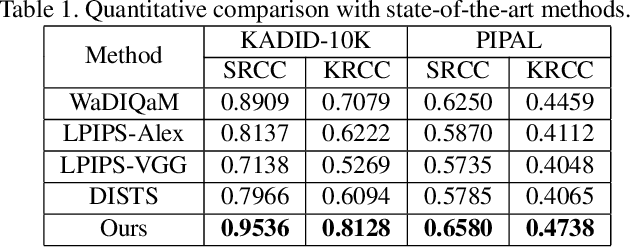

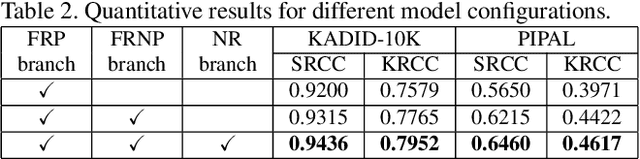
Development of perceptual image quality assessment (IQA) metrics has been of significant interest to computer vision community. The aim of these metrics is to model quality of an image as perceived by humans. Recent works in Full-reference IQA research perform pixelwise comparison between deep features corresponding to query and reference images for quality prediction. However, pixelwise feature comparison may not be meaningful if distortion present in query image is severe. In this context, we explore utilization of no-reference features in Full-reference IQA task. Our model consists of both full-reference and no-reference branches. Full-reference branches use both distorted and reference images, whereas No-reference branch only uses distorted image. Our experiments show that use of no-reference features boosts performance of image quality assessment. Our model achieves higher SRCC and KRCC scores than a number of state-of-the-art algorithms on KADID-10K and PIPAL datasets.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022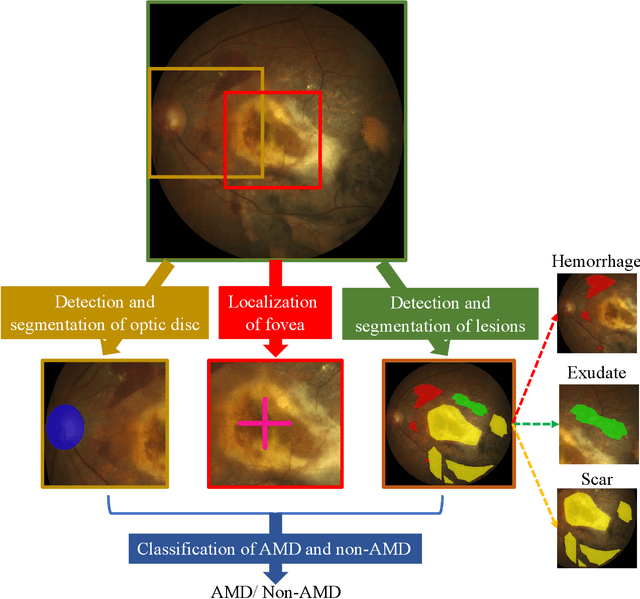

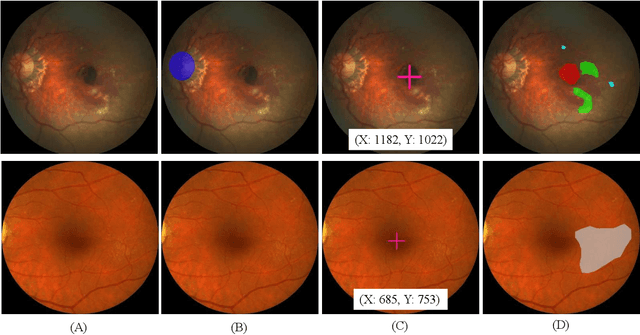
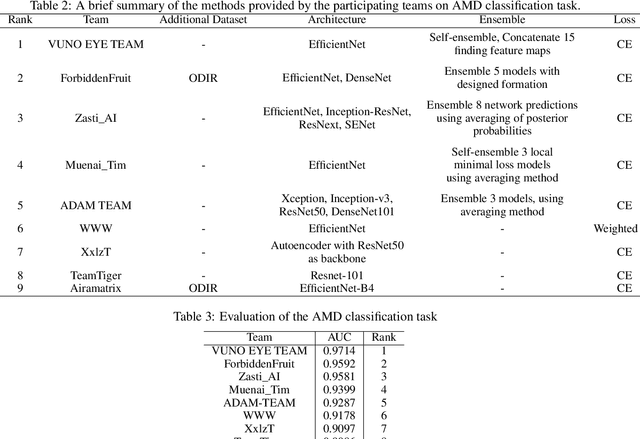
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
Anomaly Detection in Retinal Images using Multi-Scale Deep Feature Sparse Coding
Jan 27, 2022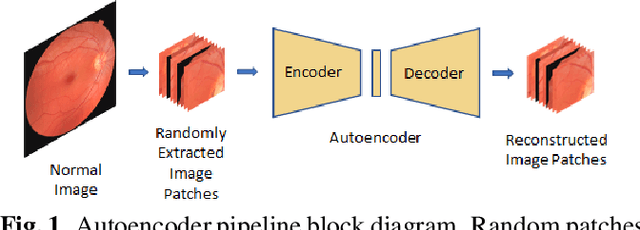
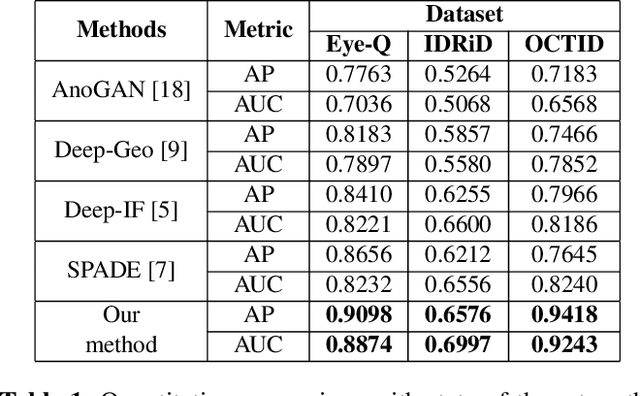
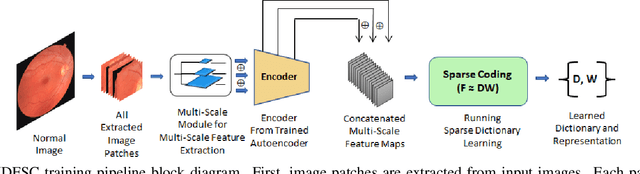
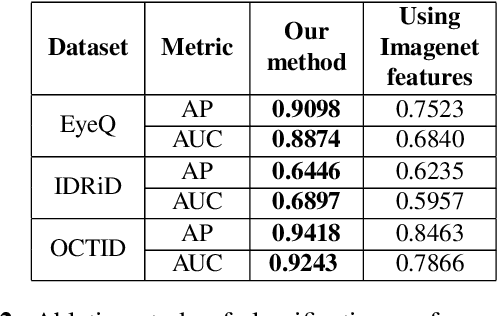
Convolutional Neural Network models have successfully detected retinal illness from optical coherence tomography (OCT) and fundus images. These CNN models frequently rely on vast amounts of labeled data for training, difficult to obtain, especially for rare diseases. Furthermore, a deep learning system trained on a data set with only one or a few diseases cannot detect other diseases, limiting the system's practical use in disease identification. We have introduced an unsupervised approach for detecting anomalies in retinal images to overcome this issue. We have proposed a simple, memory efficient, easy to train method which followed a multi-step training technique that incorporated autoencoder training and Multi-Scale Deep Feature Sparse Coding (MDFSC), an extended version of normal sparse coding, to accommodate diverse types of retinal datasets. We achieve relative AUC score improvement of 7.8\%, 6.7\% and 12.1\% over state-of-the-art SPADE on Eye-Q, IDRiD and OCTID datasets respectively.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021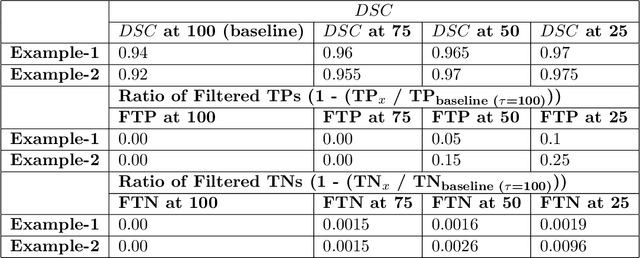
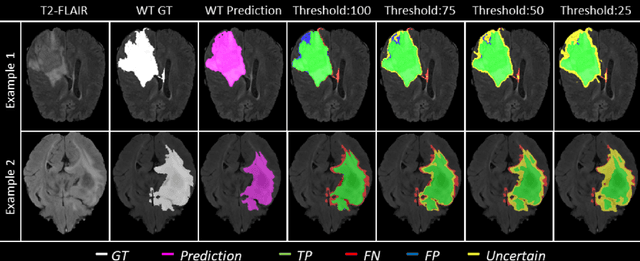
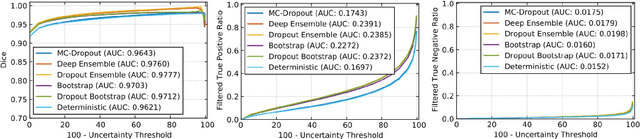
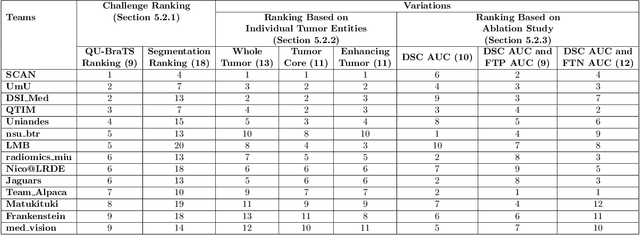
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.