 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALAP-AE: As-Lite-as-Possible Auto-Encoder
Paper and Code
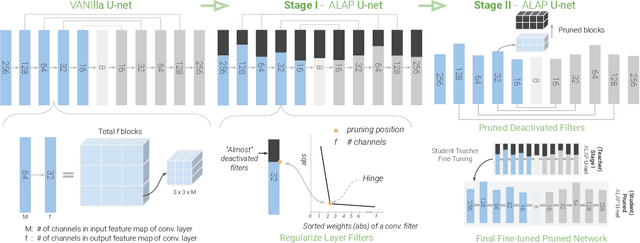
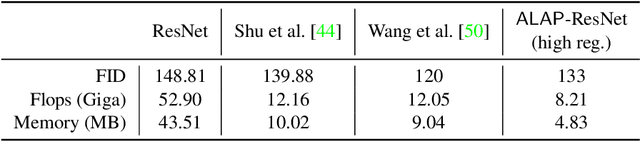
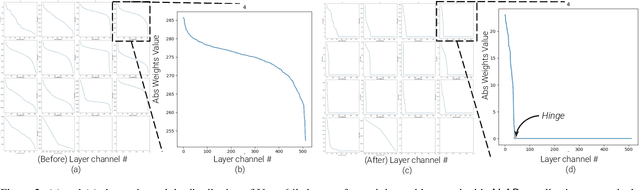
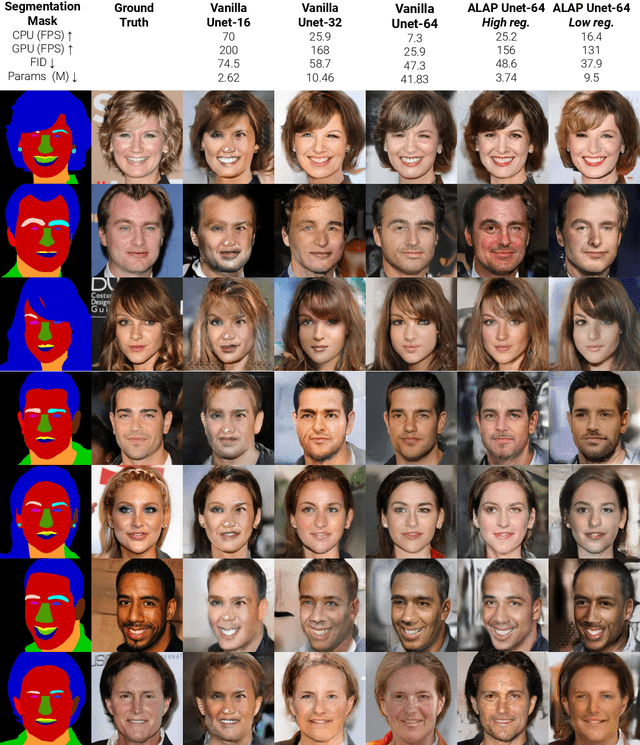
We present a novel algorithm to reduce tensor compute required by a conditional image generation autoencoder and make it as-lite-as-possible, without sacrificing quality of photo-realistic image generation. Our method is device agnostic, and can optimize an autoencoder for a given CPU-only, GPU compute device(s) in about normal time it takes to train an autoencoder on a generic workstation. We achieve this via a two-stage novel strategy where, first, we condense the channel weights, such that, as few as possible channels are used. Then, we prune the nearly zeroed out weight activations, and fine-tune this lite autoencoder. To maintain image quality, fine-tuning is done via student-teacher training, where we reuse the condensed autoencoder as the teacher. We show performance gains for various conditional image generation tasks: segmentation mask to face images, face images to cartoonization, and finally CycleGAN-based model on horse to zebra dataset over multiple compute devices. We perform various ablation studies to justify the claims and design choices, and achieve real-time versions of various autoencoders on CPU-only devices while maintaining image quality, thus enabling at-scale deployment of such autoencoders.