 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbourhood Transformer: Switchable Attention for Monophily-Aware Graph Learning
Apr 10, 2026Graph neural networks (GNNs) have been widely adopted in engineering applications such as social network analysis, chemical research and computer vision. However, their efficacy is severely compromised by the inherent homophily assumption, which fails to hold for heterophilic graphs where dissimilar nodes are frequently connected. To address this fundamental limitation in graph learning, we first draw inspiration from the recently discovered monophily property of real-world graphs, and propose Neighbourhood Transformers (NT), a novel paradigm that applies self-attention within every local neighbourhood instead of aggregating messages to the central node as in conventional message-passing GNNs. This design makes NT inherently monophily-aware and theoretically guarantees its expressiveness is no weaker than traditional message-passing frameworks. For practical engineering deployment, we further develop a neighbourhood partitioning strategy equipped with switchable attentions, which reduces the space consumption of NT by over 95% and time consumption by up to 92.67%, significantly expanding its applicability to larger graphs. Extensive experiments on 10 real-world datasets (5 heterophilic and 5 homophilic graphs) show that NT outperforms all current state-of-the-art methods on node classification tasks, demonstrating its superior performance and cross-domain adaptability. The full implementation code of this work is publicly available at https://github.com/cf020031308/MoNT to facilitate reproducibility and industrial adoption.
TimeChat-Captioner: Scripting Multi-Scene Videos with Time-Aware and Structural Audio-Visual Captions
Feb 09, 2026This paper proposes Omni Dense Captioning, a novel task designed to generate continuous, fine-grained, and structured audio-visual narratives with explicit timestamps. To ensure dense semantic coverage, we introduce a six-dimensional structural schema to create "script-like" captions, enabling readers to vividly imagine the video content scene by scene, akin to a cinematographic screenplay. To facilitate research, we construct OmniDCBench, a high-quality, human-annotated benchmark, and propose SodaM, a unified metric that evaluates time-aware detailed descriptions while mitigating scene boundary ambiguity. Furthermore, we construct a training dataset, TimeChatCap-42K, and present TimeChat-Captioner-7B, a strong baseline trained via SFT and GRPO with task-specific rewards. Extensive experiments demonstrate that TimeChat-Captioner-7B achieves state-of-the-art performance, surpassing Gemini-2.5-Pro, while its generated dense descriptions significantly boost downstream capabilities in audio-visual reasoning (DailyOmni and WorldSense) and temporal grounding (Charades-STA). All datasets, models, and code will be made publicly available at https://github.com/yaolinli/TimeChat-Captioner.
PosIR: Position-Aware Heterogeneous Information Retrieval Benchmark
Jan 13, 2026While dense retrieval models have achieved remarkable success, rigorous evaluation of their sensitivity to the position of relevant information (i.e., position bias) remains largely unexplored. Existing benchmarks typically employ position-agnostic relevance labels, conflating the challenge of processing long contexts with the bias against specific evidence locations. To address this challenge, we introduce PosIR (Position-Aware Information Retrieval), a comprehensive benchmark designed to diagnose position bias in diverse retrieval scenarios. PosIR comprises 310 datasets spanning 10 languages and 31 domains, constructed through a rigorous pipeline that ties relevance to precise reference spans, enabling the strict disentanglement of document length from information position. Extensive experiments with 10 state-of-the-art embedding models reveal that: (1) Performance on PosIR in long-context settings correlates poorly with the MMTEB benchmark, exposing limitations in current short-text benchmarks; (2) Position bias is pervasive and intensifies with document length, with most models exhibiting primacy bias while certain models show unexpected recency bias; (3) Gradient-based saliency analysis further uncovers the distinct internal attention mechanisms driving these positional preferences. In summary, PosIR serves as a valuable diagnostic framework to foster the development of position-robust retrieval systems.
Conan: Progressive Learning to Reason Like a Detective over Multi-Scale Visual Evidence
Oct 23, 2025Video reasoning, which requires multi-step deduction across frames, remains a major challenge for multimodal large language models (MLLMs). While reinforcement learning (RL)-based methods enhance reasoning capabilities, they often rely on text-only chains that yield ungrounded or hallucinated conclusions. Conversely, frame-retrieval approaches introduce visual grounding but still struggle with inaccurate evidence localization. To address these challenges, we present Conan, a framework for evidence-grounded multi-step video reasoning. Conan identifies contextual and evidence frames, reasons over cross-frame clues, and adaptively decides when to conclude or explore further. To achieve this, we (1) construct Conan-91K, a large-scale dataset of automatically generated reasoning traces that includes frame identification, evidence reasoning, and action decision, and (2) design a multi-stage progressive cold-start strategy combined with an Identification-Reasoning-Action (AIR) RLVR training framework to jointly enhance multi-step visual reasoning. Extensive experiments on six multi-step reasoning benchmarks demonstrate that Conan surpasses the baseline Qwen2.5-VL-7B-Instruct by an average of over 10% in accuracy, achieving state-of-the-art performance. Furthermore, Conan generalizes effectively to long-video understanding tasks, validating its strong scalability and robustness.
Spatial-Temporal Human-Object Interaction Detection
Aug 24, 2025In this paper, we propose a new instance-level human-object interaction detection task on videos called ST-HOID, which aims to distinguish fine-grained human-object interactions (HOIs) and the trajectories of subjects and objects. It is motivated by the fact that HOI is crucial for human-centric video content understanding. To solve ST-HOID, we propose a novel method consisting of an object trajectory detection module and an interaction reasoning module. Furthermore, we construct the first dataset named VidOR-HOID for ST-HOID evaluation, which contains 10,831 spatial-temporal HOI instances. We conduct extensive experiments to evaluate the effectiveness of our method. The experimental results demonstrate that our method outperforms the baselines generated by the state-of-the-art methods of image human-object interaction detection, video visual relation detection and video human-object interaction recognition.
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
May 29, 2025Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on "test-time scaling" further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
RICO: Improving Accuracy and Completeness in Image Recaptioning via Visual Reconstruction
May 28, 2025Image recaptioning is widely used to generate training datasets with enhanced quality for various multimodal tasks. Existing recaptioning methods typically rely on powerful multimodal large language models (MLLMs) to enhance textual descriptions, but often suffer from inaccuracies due to hallucinations and incompleteness caused by missing fine-grained details. To address these limitations, we propose RICO, a novel framework that refines captions through visual reconstruction. Specifically, we leverage a text-to-image model to reconstruct a caption into a reference image, and prompt an MLLM to identify discrepancies between the original and reconstructed images to refine the caption. This process is performed iteratively, further progressively promoting the generation of more faithful and comprehensive descriptions. To mitigate the additional computational cost induced by the iterative process, we introduce RICO-Flash, which learns to generate captions like RICO using DPO. Extensive experiments demonstrate that our approach significantly improves caption accuracy and completeness, outperforms most baselines by approximately 10% on both CapsBench and CompreCap. Code released at https://github.com/wangyuchi369/RICO.
TimeChat-Online: 80% Visual Tokens are Naturally Redundant in Streaming Videos
Apr 24, 2025The rapid growth of online video platforms, particularly live streaming services, has created an urgent need for real-time video understanding systems. These systems must process continuous video streams and respond to user queries instantaneously, presenting unique challenges for current Video Large Language Models (VideoLLMs). While existing VideoLLMs excel at processing complete videos, they face significant limitations in streaming scenarios due to their inability to handle dense, redundant frames efficiently. We introduce TimeChat-Online, a novel online VideoLLM that revolutionizes real-time video interaction. At its core lies our innovative Differential Token Drop (DTD) module, which addresses the fundamental challenge of visual redundancy in streaming videos. Drawing inspiration from human visual perception's Change Blindness phenomenon, DTD preserves meaningful temporal changes while filtering out static, redundant content between frames. Remarkably, our experiments demonstrate that DTD achieves an 82.8% reduction in video tokens while maintaining 98% performance on StreamingBench, revealing that over 80% of visual content in streaming videos is naturally redundant without requiring language guidance. To enable seamless real-time interaction, we present TimeChat-Online-139K, a comprehensive streaming video dataset featuring diverse interaction patterns including backward-tracing, current-perception, and future-responding scenarios. TimeChat-Online's unique Proactive Response capability, naturally achieved through continuous monitoring of video scene transitions via DTD, sets it apart from conventional approaches. Our extensive evaluation demonstrates TimeChat-Online's superior performance on streaming benchmarks (StreamingBench and OvOBench) and maintaining competitive results on long-form video tasks such as Video-MME and MLVU.
UVE: Are MLLMs Unified Evaluators for AI-Generated Videos?
Mar 13, 2025With the rapid growth of video generative models (VGMs), it is essential to develop reliable and comprehensive automatic metrics for AI-generated videos (AIGVs). Existing methods either use off-the-shelf models optimized for other tasks or rely on human assessment data to train specialized evaluators. These approaches are constrained to specific evaluation aspects and are difficult to scale with the increasing demands for finer-grained and more comprehensive evaluations. To address this issue, this work investigates the feasibility of using multimodal large language models (MLLMs) as a unified evaluator for AIGVs, leveraging their strong visual perception and language understanding capabilities. To evaluate the performance of automatic metrics in unified AIGV evaluation, we introduce a benchmark called UVE-Bench. UVE-Bench collects videos generated by state-of-the-art VGMs and provides pairwise human preference annotations across 15 evaluation aspects. Using UVE-Bench, we extensively evaluate 16 MLLMs. Our empirical results suggest that while advanced MLLMs (e.g., Qwen2VL-72B and InternVL2.5-78B) still lag behind human evaluators, they demonstrate promising ability in unified AIGV evaluation, significantly surpassing existing specialized evaluation methods. Additionally, we conduct an in-depth analysis of key design choices that impact the performance of MLLM-driven evaluators, offering valuable insights for future research on AIGV evaluation. The code is available at https://github.com/bytedance/UVE.
Generative Frame Sampler for Long Video Understanding
Mar 12, 2025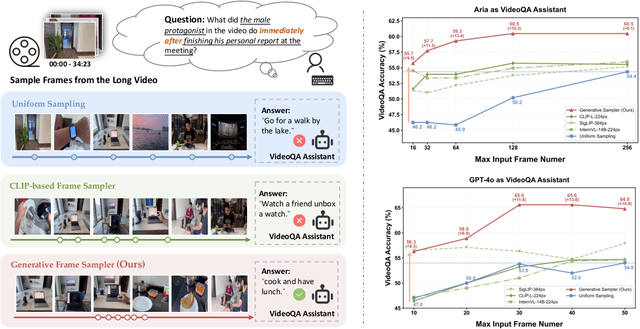
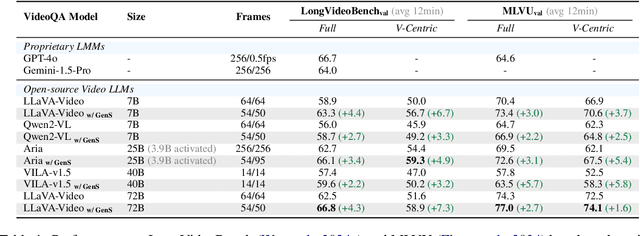
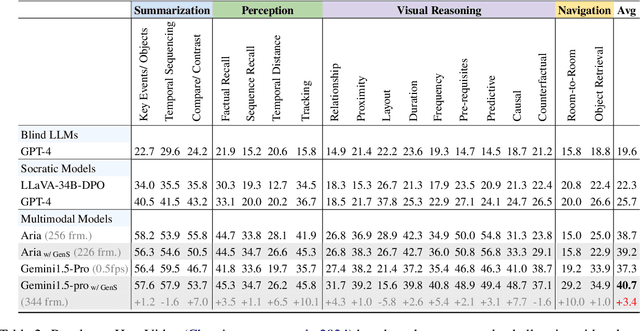

Despite recent advances in Video Large Language Models (VideoLLMs), effectively understanding long-form videos remains a significant challenge. Perceiving lengthy videos containing thousands of frames poses substantial computational burden. To mitigate this issue, this paper introduces Generative Frame Sampler (GenS), a plug-and-play module integrated with VideoLLMs to facilitate efficient lengthy video perception. Built upon a lightweight VideoLLM, GenS leverages its inherent vision-language capabilities to identify question-relevant frames. To facilitate effective retrieval, we construct GenS-Video-150K, a large-scale video instruction dataset with dense frame relevance annotations. Extensive experiments demonstrate that GenS consistently boosts the performance of various VideoLLMs, including open-source models (Qwen2-VL-7B, Aria-25B, VILA-40B, LLaVA-Video-7B/72B) and proprietary assistants (GPT-4o, Gemini). When equipped with GenS, open-source VideoLLMs achieve impressive state-of-the-art results on long-form video benchmarks: LLaVA-Video-72B reaches 66.8 (+4.3) on LongVideoBench and 77.0 (+2.7) on MLVU, while Aria obtains 39.2 on HourVideo surpassing the Gemini-1.5-pro by 1.9 points. We will release all datasets and models at https://generative-sampler.github.io.