 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Image Cross-Domain Object Detection Method based on Spectral-Spatial Feature Alignment
Nov 25, 2024
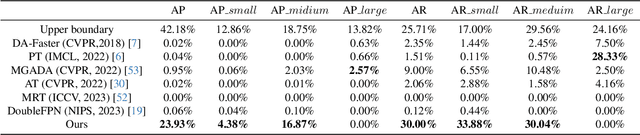

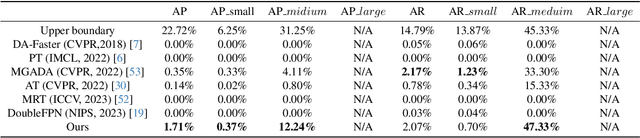
With consecutive bands in a wide range of wavelengths, hyperspectral images (HSI) have provided a unique tool for object detection task. However, existing HSI object detection methods have not been fully utilized in real applications, which is mainly resulted by the difference of spatial and spectral resolution between the unlabeled target domain and a labeled source domain, i.e. the domain shift of HSI. In this work, we aim to explore the unsupervised cross-domain object detection of HSI. Our key observation is that the local spatial-spectral characteristics remain invariant across different domains. For solving the problem of domain-shift, we propose a HSI cross-domain object detection method based on spectral-spatial feature alignment, which is the first attempt in the object detection community to the best of our knowledge. Firstly, we develop a spectral-spatial alignment module to extract domain-invariant local spatial-spectral features. Secondly, the spectral autocorrelation module has been designed to solve the domain shift in the spectral domain specifically, which can effectively align HSIs with different spectral resolutions. Besides, we have collected and annotated an HSI dataset for the cross-domain object detection. Our experimental results have proved the effectiveness of HSI cross-domain object detection, which has firstly demonstrated a significant and promising step towards HSI cross-domain object detection in the object detection community.
HorGait: Advancing Gait Recognition with Efficient High-Order Spatial Interactions in LiDAR Point Clouds
Oct 11, 2024Gait recognition is a remote biometric technology that utilizes the dynamic characteristics of human movement to identify individuals even under various extreme lighting conditions. Due to the limitation in spatial perception capability inherent in 2D gait representations, LiDAR can directly capture 3D gait features and represent them as point clouds, reducing environmental and lighting interference in recognition while significantly advancing privacy protection. For complex 3D representations, shallow networks fail to achieve accurate recognition, making vision Transformers the foremost prevalent method. However, the prevalence of dumb patches has limited the widespread use of Transformer architecture in gait recognition. This paper proposes a method named HorGait, which utilizes a hybrid model with a Transformer architecture for gait recognition on the planar projection of 3D point clouds from LiDAR. Specifically, it employs a hybrid model structure called LHM Block to achieve input adaptation, long-range, and high-order spatial interaction of the Transformer architecture. Additionally, it uses large convolutional kernel CNNs to segment the input representation, replacing attention windows to reduce dumb patches. We conducted extensive experiments, and the results show that HorGait achieves state-of-the-art performance among Transformer architecture methods on the SUSTech1K dataset, verifying that the hybrid model can complete the full Transformer process and perform better in point cloud planar projection. The outstanding performance of HorGait offers new insights for the future application of the Transformer architecture in gait recognition.
SpheriGait: Enriching Spatial Representation via Spherical Projection for LiDAR-based Gait Recognition
Sep 18, 2024Gait recognition is a rapidly progressing technique for the remote identification of individuals. Prior research predominantly employing 2D sensors to gather gait data has achieved notable advancements; nonetheless, they have unavoidably neglected the influence of 3D dynamic characteristics on recognition. Gait recognition utilizing LiDAR 3D point clouds not only directly captures 3D spatial features but also diminishes the impact of lighting conditions while ensuring privacy protection.The essence of the problem lies in how to effectively extract discriminative 3D dynamic representation from point clouds.In this paper, we proposes a method named SpheriGait for extracting and enhancing dynamic features from point clouds for Lidar-based gait recognition. Specifically, it substitutes the conventional point cloud plane projection method with spherical projection to augment the perception of dynamic feature.Additionally, a network block named DAM-L is proposed to extract gait cues from the projected point cloud data. We conducted extensive experiments and the results demonstrated the SpheriGait achieved state-of-the-art performance on the SUSTech1K dataset, and verified that the spherical projection method can serve as a universal data preprocessing technique to enhance the performance of other LiDAR-based gait recognition methods, exhibiting exceptional flexibility and practicality.
Shallow Network Based on Depthwise Over-Parameterized Convolution for Hyperspectral Image Classification
Dec 01, 2021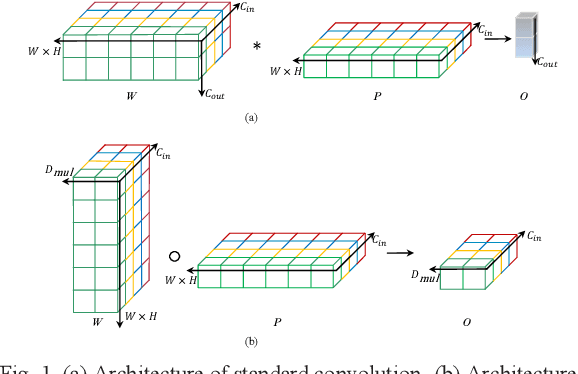
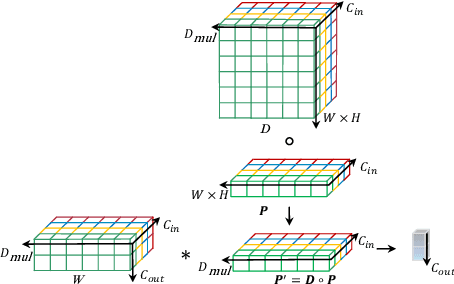
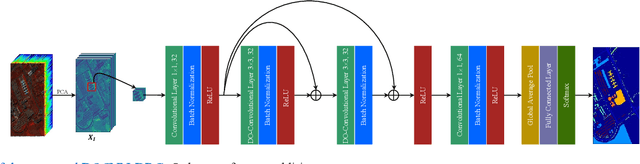
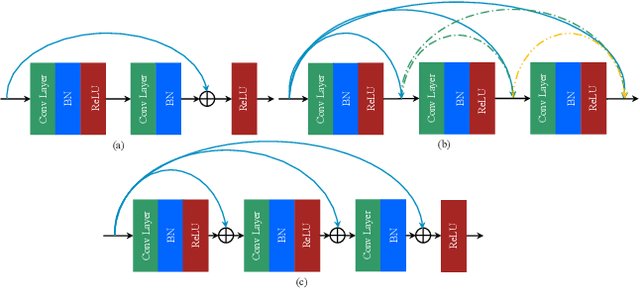
Recently, convolutional neural network (CNN) techniques have gained popularity as a tool for hyperspectral image classification (HSIC). To improve the feature extraction efficiency of HSIC under the condition of limited samples, the current methods generally use deep models with plenty of layers. However, deep network models are prone to overfitting and gradient vanishing problems when samples are limited. In addition, the spatial resolution decreases severely with deeper depth, which is very detrimental to spatial edge feature extraction. Therefore, this letter proposes a shallow model for HSIC, which is called depthwise over-parameterized convolutional neural network (DOCNN). To ensure the effective extraction of the shallow model, the depthwise over-parameterized convolution (DO-Conv) kernel is introduced to extract the discriminative features. The depthwise over-parameterized Convolution kernel is composed of a standard convolution kernel and a depthwise convolution kernel, which can extract the spatial feature of the different channels individually and fuse the spatial features of the whole channels simultaneously. Moreover, to further reduce the loss of spatial edge features due to the convolution operation, a dense residual connection (DRC) structure is proposed to apply to the feature extraction part of the whole network. Experimental results obtained from three benchmark data sets show that the proposed method outperforms other state-of-the-art methods in terms of classification accuracy and computational efficiency.