 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Network Based on Depthwise Over-Parameterized Convolution for Hyperspectral Image Classification
Dec 01, 2021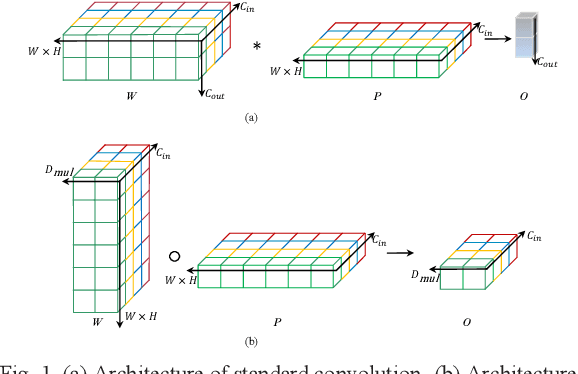
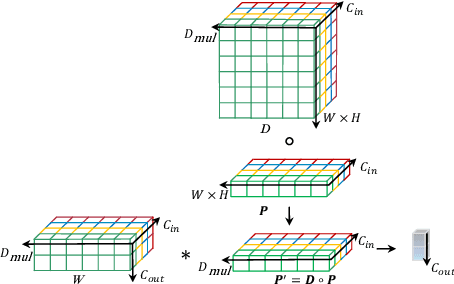
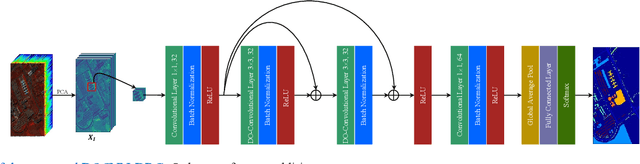
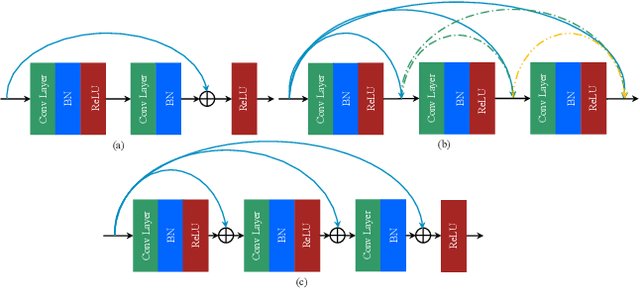
Recently, convolutional neural network (CNN) techniques have gained popularity as a tool for hyperspectral image classification (HSIC). To improve the feature extraction efficiency of HSIC under the condition of limited samples, the current methods generally use deep models with plenty of layers. However, deep network models are prone to overfitting and gradient vanishing problems when samples are limited. In addition, the spatial resolution decreases severely with deeper depth, which is very detrimental to spatial edge feature extraction. Therefore, this letter proposes a shallow model for HSIC, which is called depthwise over-parameterized convolutional neural network (DOCNN). To ensure the effective extraction of the shallow model, the depthwise over-parameterized convolution (DO-Conv) kernel is introduced to extract the discriminative features. The depthwise over-parameterized Convolution kernel is composed of a standard convolution kernel and a depthwise convolution kernel, which can extract the spatial feature of the different channels individually and fuse the spatial features of the whole channels simultaneously. Moreover, to further reduce the loss of spatial edge features due to the convolution operation, a dense residual connection (DRC) structure is proposed to apply to the feature extraction part of the whole network. Experimental results obtained from three benchmark data sets show that the proposed method outperforms other state-of-the-art methods in terms of classification accuracy and computational efficiency.
VSSA-NET: Vertical Spatial Sequence Attention Network for Traffic Sign Detection
May 05, 2019
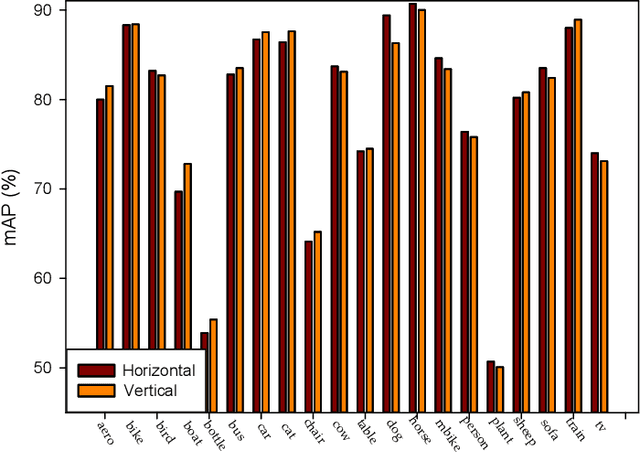
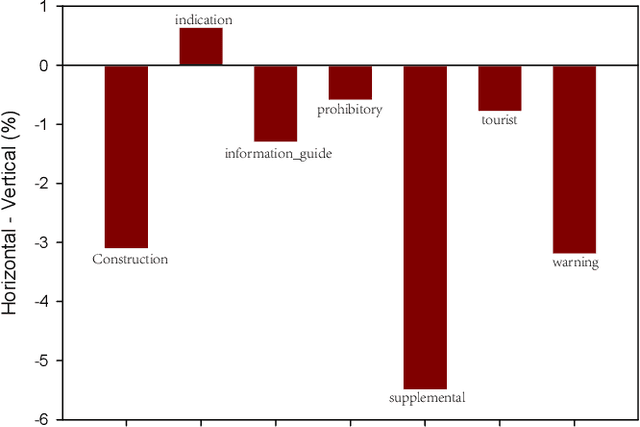

Although traffic sign detection has been studied for years and great progress has been made with the rise of deep learning technique, there are still many problems remaining to be addressed. For complicated real-world traffic scenes, there are two main challenges. Firstly, traffic signs are usually small size objects, which makes it more difficult to detect than large ones; Secondly, it is hard to distinguish false targets which resemble real traffic signs in complex street scenes without context information. To handle these problems, we propose a novel end-to-end deep learning method for traffic sign detection in complex environments. Our contributions are as follows: 1) We propose a multi-resolution feature fusion network architecture which exploits densely connected deconvolution layers with skip connections, and can learn more effective features for the small size object; 2) We frame the traffic sign detection as a spatial sequence classification and regression task, and propose a vertical spatial sequence attention (VSSA) module to gain more context information for better detection performance. To comprehensively evaluate the proposed method, we do experiments on several traffic sign datasets as well as the general object detection dataset and the results have shown the effectiveness of our proposed method.