 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Network Based on Depthwise Over-Parameterized Convolution for Hyperspectral Image Classification
Dec 01, 2021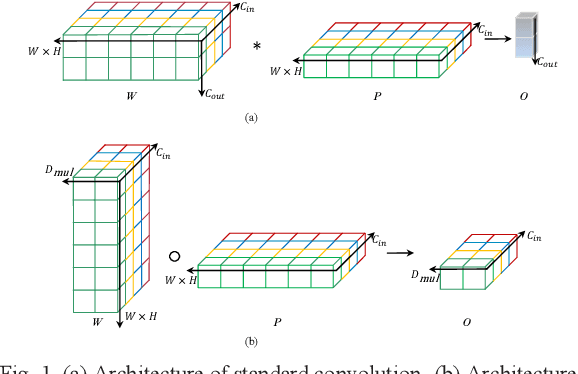
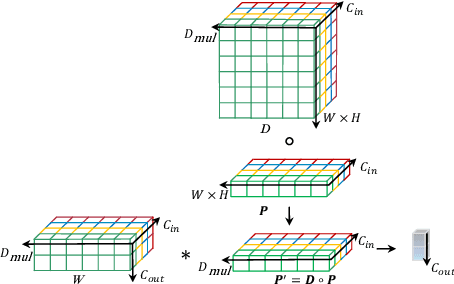
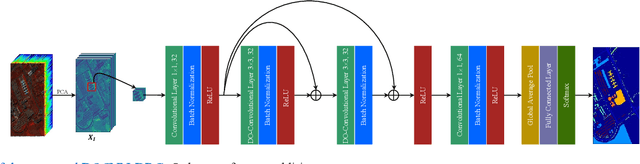
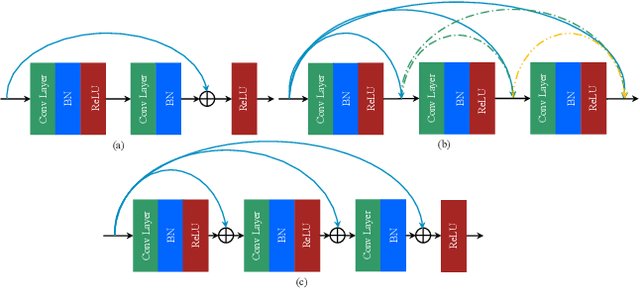
Recently, convolutional neural network (CNN) techniques have gained popularity as a tool for hyperspectral image classification (HSIC). To improve the feature extraction efficiency of HSIC under the condition of limited samples, the current methods generally use deep models with plenty of layers. However, deep network models are prone to overfitting and gradient vanishing problems when samples are limited. In addition, the spatial resolution decreases severely with deeper depth, which is very detrimental to spatial edge feature extraction. Therefore, this letter proposes a shallow model for HSIC, which is called depthwise over-parameterized convolutional neural network (DOCNN). To ensure the effective extraction of the shallow model, the depthwise over-parameterized convolution (DO-Conv) kernel is introduced to extract the discriminative features. The depthwise over-parameterized Convolution kernel is composed of a standard convolution kernel and a depthwise convolution kernel, which can extract the spatial feature of the different channels individually and fuse the spatial features of the whole channels simultaneously. Moreover, to further reduce the loss of spatial edge features due to the convolution operation, a dense residual connection (DRC) structure is proposed to apply to the feature extraction part of the whole network. Experimental results obtained from three benchmark data sets show that the proposed method outperforms other state-of-the-art methods in terms of classification accuracy and computational efficiency.
Frame-wise Cross-modal Match for Video Moment Retrieval
Sep 22, 2020
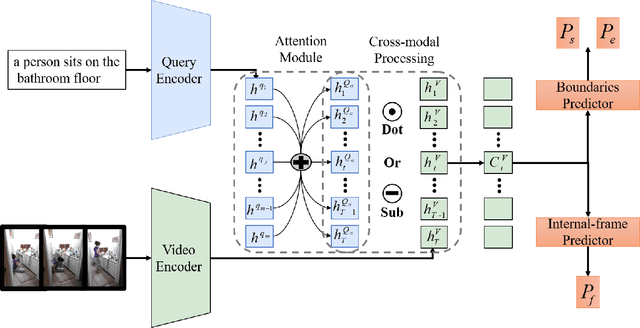
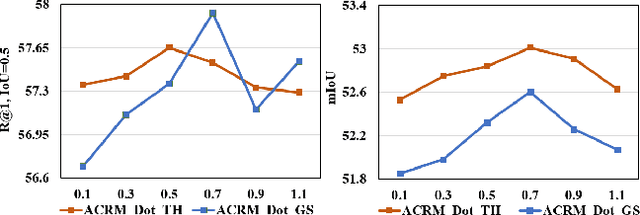

Video moment retrieval targets at retrieving a golden moment in a video for a given natural language query. The main challenges of this task include 1) the requirement of accurately localizing (i.e., the start time and the end time of) the relevant moment in an untrimmed video stream, and 2) bridging the semantic gap between textual query and video contents. To tackle those problems, One mainstream approach is to generate a multimodal feature vector for the target query and video frames (e.g., concatenation) and then use a regression approach upon the multimodal feature vector for boundary detection. Although some progress has been achieved by this approach, we argue that those methods have not well captured the cross-modal interactions between the query and video frames. In this paper, we propose an Attentive Cross-modal Relevance Matching (ACRM) model which predicts the temporal bounders based on an interaction modeling between two modalities. In addition, an attention module is introduced to automatically assign higher weights to query words with richer semantic cues, which are considered to be more important for finding relevant video contents. Another contribution is that we propose an additional predictor to utilize the internal frames in the model training to improve the localization accuracy. Extensive experiments on two public datasetsdemonstrate the superiority of our method over several state-of-the-art methods.
Channel Estimation for RIS-Empowered Multi-User MISO Wireless Communications
Aug 04, 2020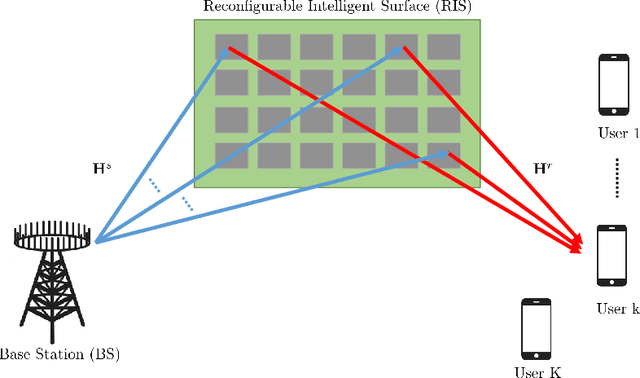
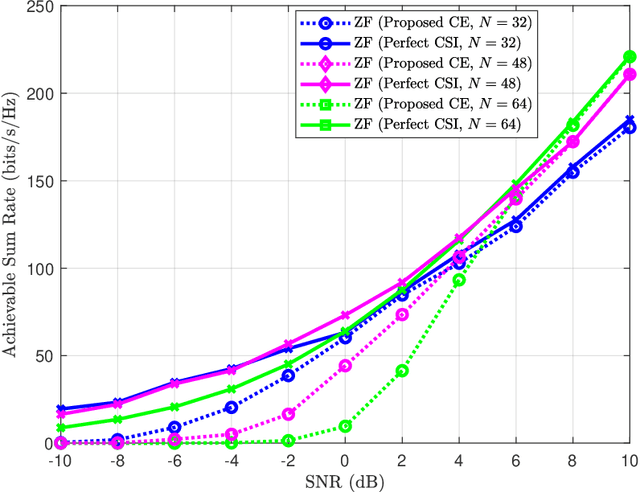
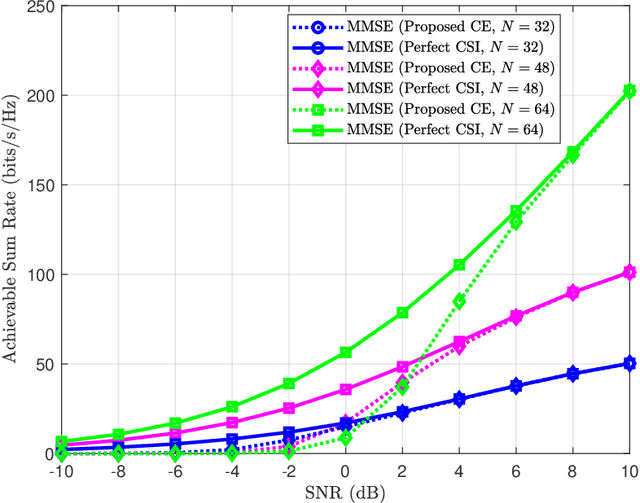
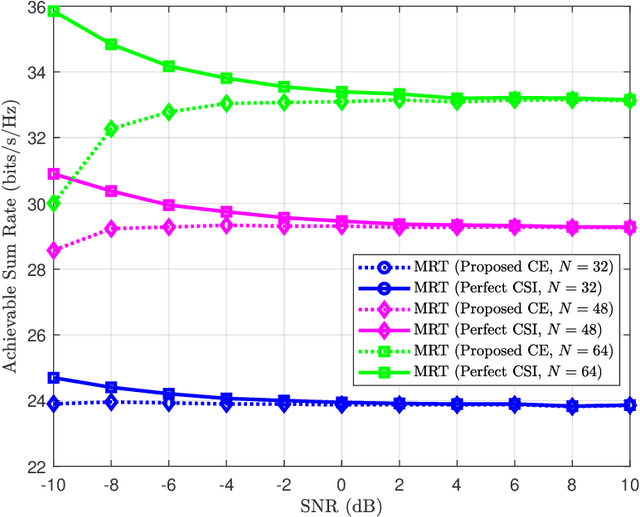
Reconfigurable Intelligent Surfaces (RISs) have been recently considered as an energy-efficient solution for future wireless networks due to their fast and low-power configuration, which has increased potential in enabling massive connectivity and low-latency communications. Accurate and low-overhead channel estimation in RIS-based systems is one of the most critical challenges due to the usually large number of RIS unit elements and their distinctive hardware constraints. In this paper, we focus on the downlink of a RIS-empowered multi-user Multiple Input Single Output (MISO) downlink communication systems and propose a channel estimation framework based on the PARAllel FACtor (PARAFAC) decomposition to unfold the resulting cascaded channel model. We present two iterative estimation algorithms for the channels between the base station and RIS, as well as the channels between RIS and users. One is based on alternating least squares (ALS), while the other uses vector approximate message passing to iteratively reconstruct two unknown channels from the estimated vectors. To theoretically assess the performance of the ALS-based algorithm, we derived its estimation Cram\'er-Rao Bound (CRB). We also discuss the achievable sum-rate computation with estimated channels and different precoding schemes for the base station. Our extensive simulation results show that our algorithms outperform benchmark schemes and that the ALS technique achieve the CRB. It is also demonstrated that the sum rate using the estimated channels reached that of perfect channel estimation under various settings, thus, verifying the effectiveness and robustness of the proposed estimation algorithms.
Reconfigurable Intelligent Surface Assisted Multiuser MISO Systems Exploiting Deep Reinforcement Learning
Feb 24, 2020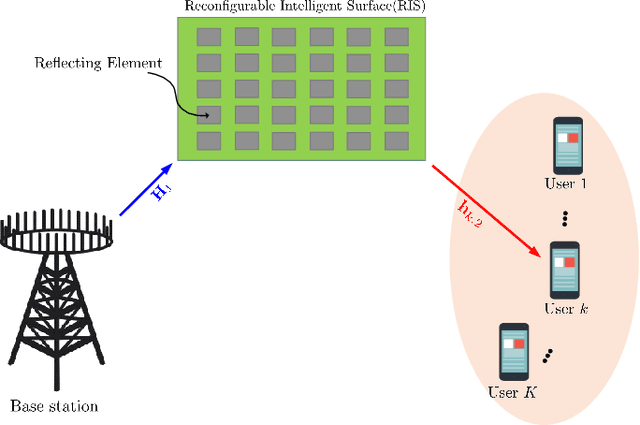
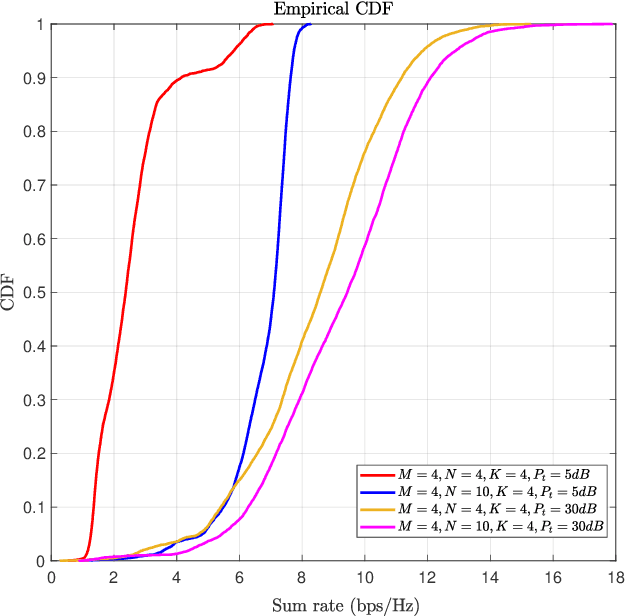
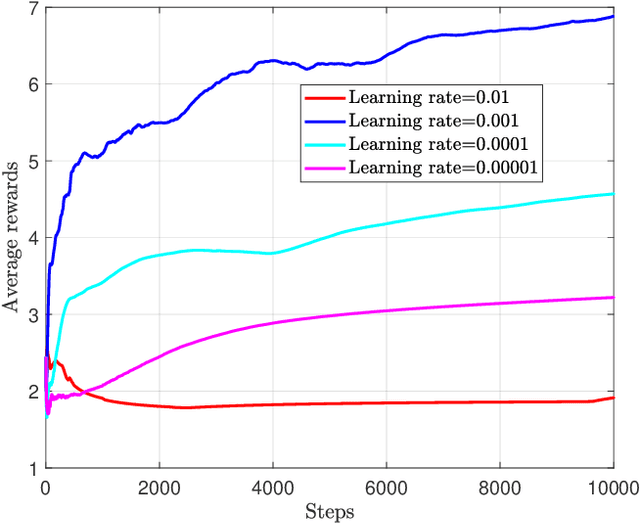
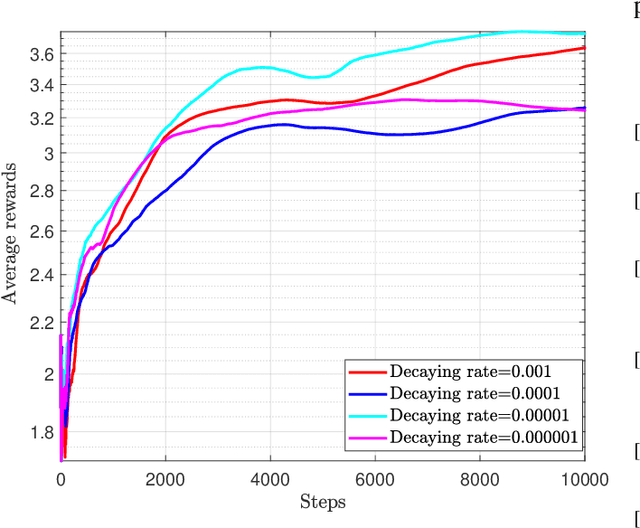
Recently, the reconfigurable intelligent surface (RIS), benefited from the breakthrough on the fabrication of programmable meta-material, has been speculated as one of the key enabling technologies for the future six generation (6G) wireless communication systems scaled up beyond massive multiple input multiple output (Massive-MIMO) technology to achieve smart radio environments. Employed as reflecting arrays, RIS is able to assist MIMO transmissions without the need of radio frequency chains resulting in considerable reduction in power consumption. In this paper, we investigate the joint design of transmit beamforming matrix at the base station and the phase shift matrix at the RIS, by leveraging recent advances in deep reinforcement learning (DRL). We first develop a DRL based algorithm, in which the joint design is obtained through trial-and-error interactions with the environment by observing predefined rewards, in the context of continuous state and action. Unlike the most reported works utilizing the alternating optimization techniques to alternatively obtain the transmit beamforming and phase shifts, the proposed DRL based algorithm obtains the joint design simultaneously as the output of the DRL neural network. Simulation results show that the proposed algorithm is not only able to learn from the environment and gradually improve its behavior, but also obtains the comparable performance compared with two state-of-the-art benchmarks. It is also observed that, appropriate neural network parameter settings will improve significantly the performance and convergence rate of the proposed algorithm.
Broad Learning System Based on Maximum Correntropy Criterion
Dec 24, 2019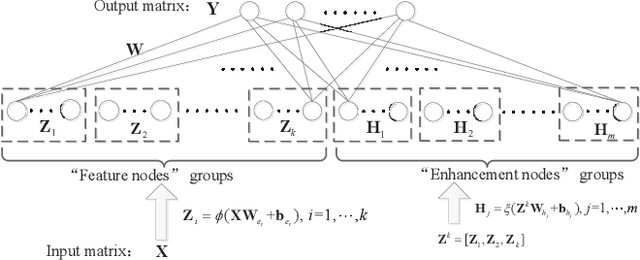
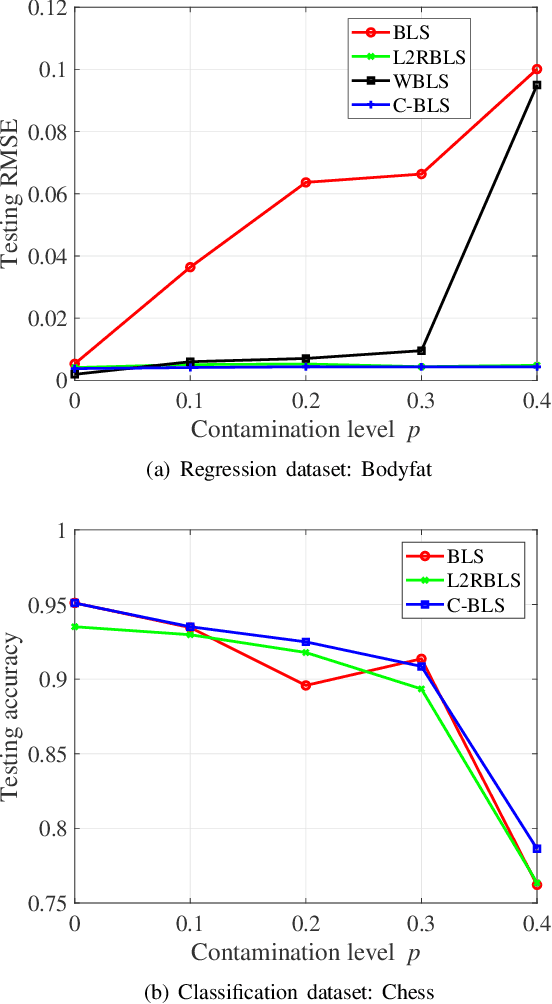
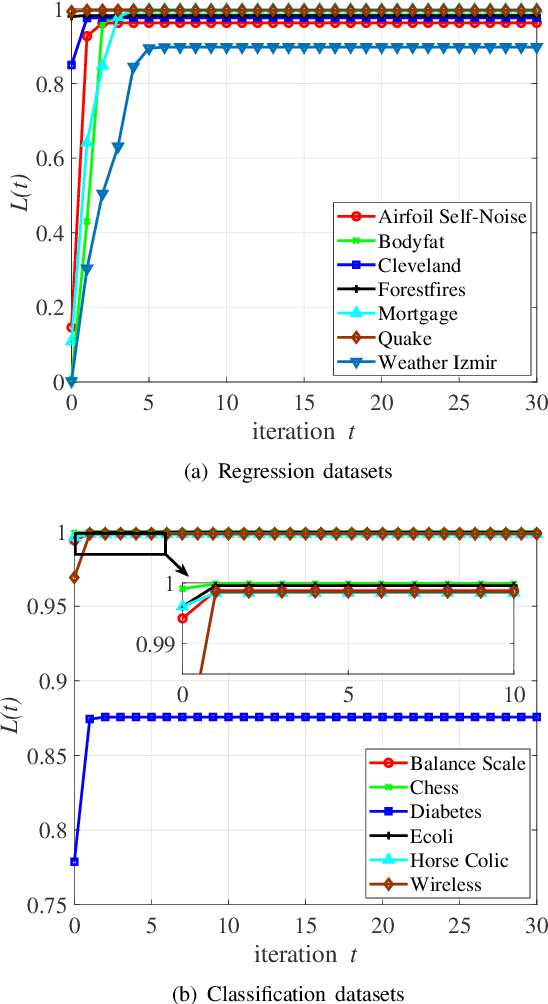
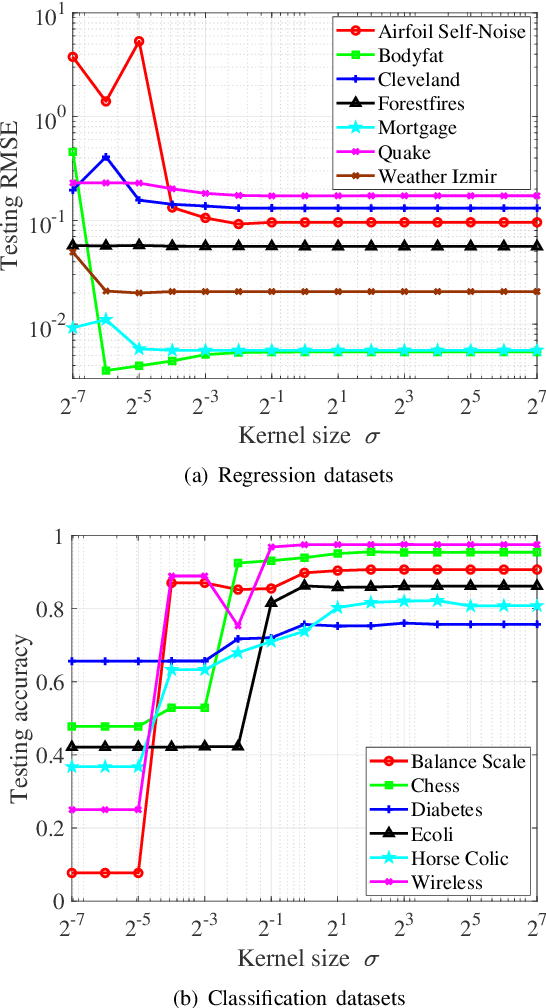
As an effective and efficient discriminative learning method, Broad Learning System (BLS) has received increasing attention due to its outstanding performance in various regression and classification problems. However, the standard BLS is derived under the minimum mean square error (MMSE) criterion, which is, of course, not always a good choice due to its sensitivity to outliers. To enhance the robustness of BLS, we propose in this work to adopt the maximum correntropy criterion (MCC) to train the output weights, obtaining a correntropy based broad learning system (C-BLS). Thanks to the inherent superiorities of MCC, the proposed C-BLS is expected to achieve excellent robustness to outliers while maintaining the original performance of the standard BLS in Gaussian or noise-free environment. In addition, three alternative incremental learning algorithms, derived from a weighted regularized least-squares solution rather than pseudoinverse formula, for C-BLS are developed.With the incremental learning algorithms, the system can be updated quickly without the entire retraining process from the beginning, when some new samples arrive or the network deems to be expanded. Experiments on various regression and classification datasets are reported to demonstrate the desirable performance of the new methods.
A Universal Approximation Result for Difference of log-sum-exp Neural Networks
May 21, 2019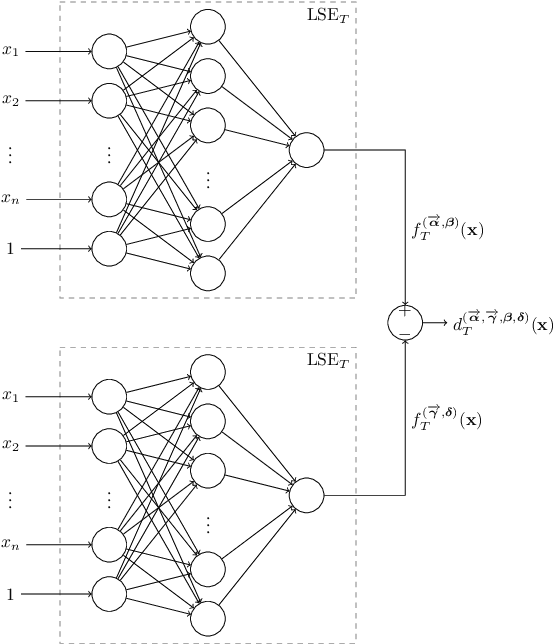
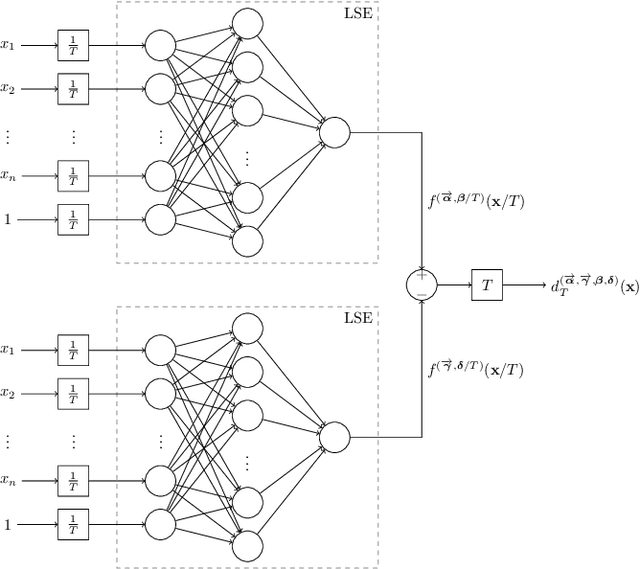
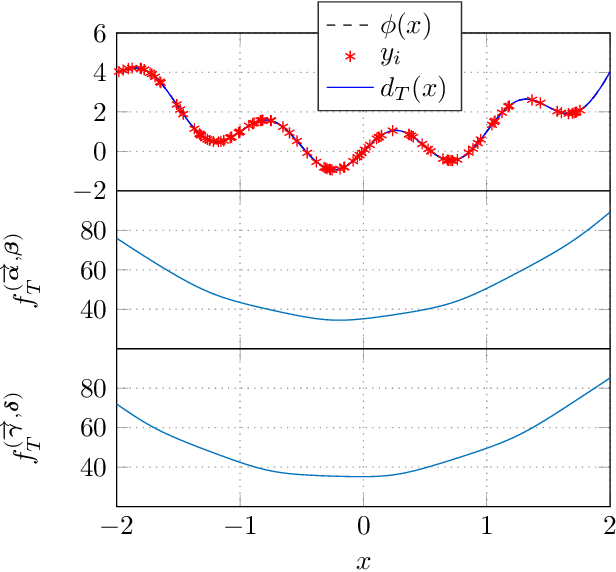
We show that a neural network whose output is obtained as the difference of the outputs of two feedforward networks with exponential activation function in the hidden layer and logarithmic activation function in the output node (LSE networks) is a smooth universal approximator of continuous functions over convex, compact sets. By using a logarithmic transform, this class of networks maps to a family of subtraction-free ratios of generalized posynomials, which we also show to be universal approximators of positive functions over log-convex, compact subsets of the positive orthant. The main advantage of Difference-LSE networks with respect to classical feedforward neural networks is that, after a standard training phase, they provide surrogate models for design that possess a specific difference-of-convex-functions form, which makes them optimizable via relatively efficient numerical methods. In particular, by adapting an existing difference-of-convex algorithm to these models, we obtain an algorithm for performing effective optimization-based design. We illustrate the proposed approach by applying it to data-driven design of a diet for a patient with type-2 diabetes.
PEA265: Perceptual Assessment of Video Compression Artifacts
Mar 01, 2019
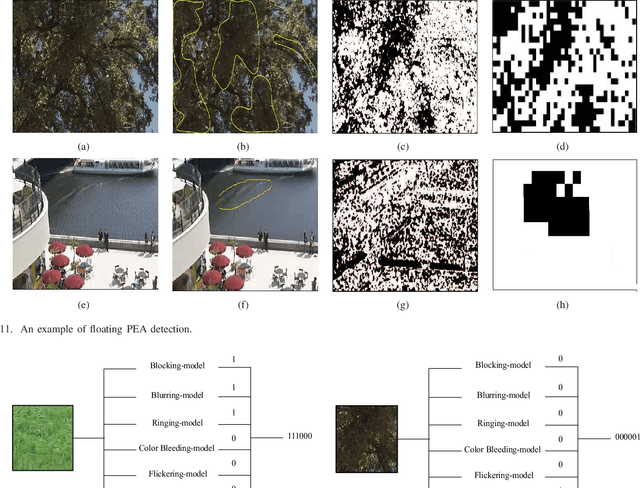
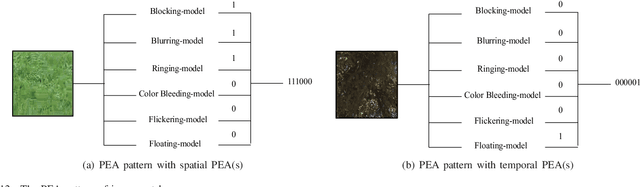
The most widely used video encoders share a common hybrid coding framework that includes block-based motion estimation/compensation and block-based transform coding. Despite their high coding efficiency, the encoded videos often exhibit visually annoying artifacts, denoted as Perceivable Encoding Artifacts (PEAs), which significantly degrade the visual Qualityof- Experience (QoE) of end users. To monitor and improve visual QoE, it is crucial to develop subjective and objective measures that can identify and quantify various types of PEAs. In this work, we make the first attempt to build a large-scale subjectlabelled database composed of H.265/HEVC compressed videos containing various PEAs. The database, namely the PEA265 database, includes 4 types of spatial PEAs (i.e. blurring, blocking, ringing and color bleeding) and 2 types of temporal PEAs (i.e. flickering and floating). Each containing at least 60,000 image or video patches with positive and negative labels. To objectively identify these PEAs, we train Convolutional Neural Networks (CNNs) using the PEA265 database. It appears that state-of-theart ResNeXt is capable of identifying each type of PEAs with high accuracy. Furthermore, we define PEA pattern and PEA intensity measures to quantify PEA levels of compressed video sequence. We believe that the PEA265 database and our findings will benefit the future development of video quality assessment methods and perceptually motivated video encoders.
Design and Control of a Quasi-Direct Drive Soft Hybrid Knee Exoskeleton for Injury Prevention during Squatting
Feb 19, 2019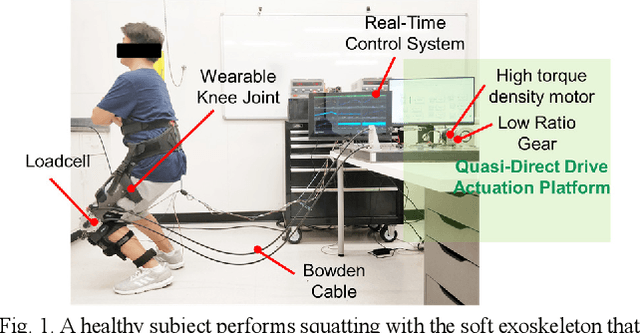
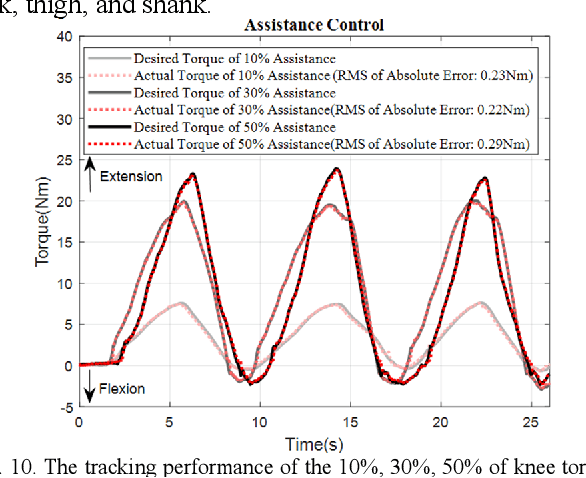
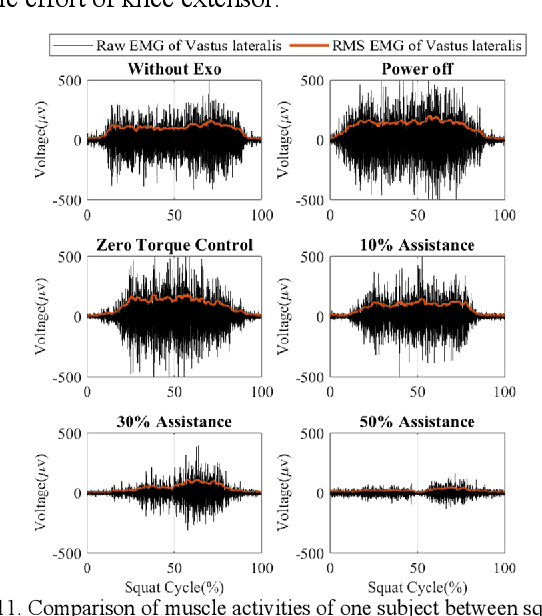
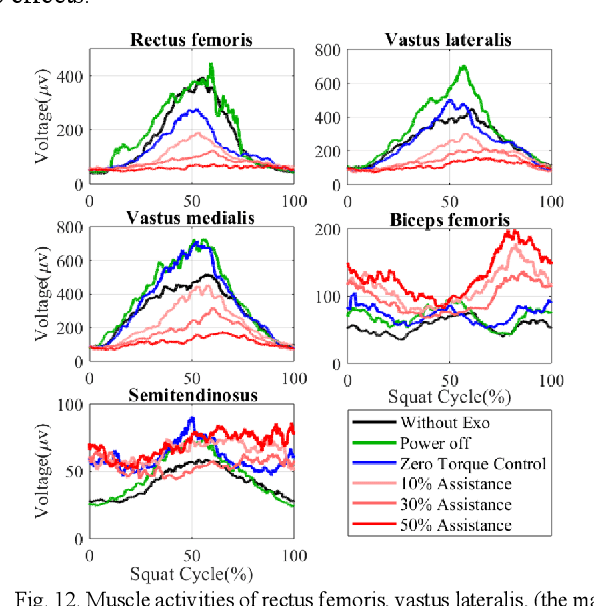
This paper presents a new design approach of wearable robots that tackle the three barriers to mainstay practical use of exoskeletons, namely discomfort, weight of the device, and symbiotic control of the exoskeleton-human co-robot system. The hybrid exoskeleton approach, demonstrated in a soft knee industrial exoskeleton case, mitigates the discomfort of wearers as it aims to avoid the drawbacks of rigid exoskeletons and textile-based soft exosuits. Quasi-direct drive actuation using high-torque density motors minimizes the weight of the device and presents high backdrivability that does not restrict natural movement. We derive a biomechanics model that is generic to both squat and stoop lifting motion. The control algorithm symbiotically detects posture using compact inertial measurement unit (IMU) sensors to generate an assistive profile that is proportional to the biological torque generated from our model. Experimental results demonstrate that the robot exhibits 1.5 Nm torque when it is unpowered and 0.5 Nm torque with zero-torque tracking control. The efficacy of injury prevention is demonstrated with one healthy subject. Root mean square (RMS) error of torque tracking is less than 0.29 Nm (1.21% of 24 Nm peak torque) for 50% assistance of biological torque. Comparing to the squat without exoskeleton, the maximum amplitude of the knee extensor muscle activity (rectus femoris) measured by Electromyography (EMG) sensors is reduced by 30% with 50% assistance of biological torque.
Comfort-Centered Design of a Lightweight and Backdrivable Knee Exoskeleton
Feb 11, 2019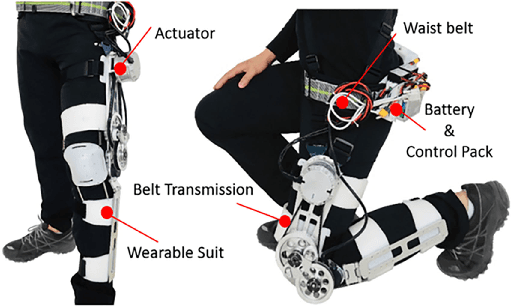
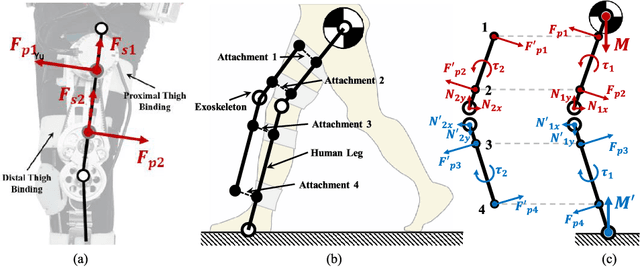
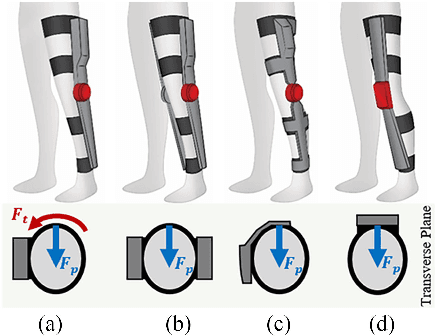
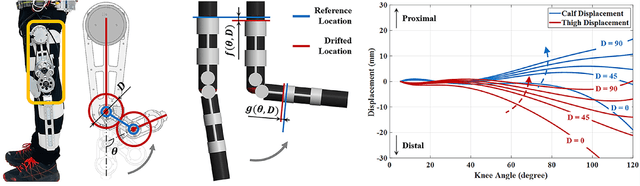
This paper presents design principles for comfort-centered wearable robots and their application in a lightweight and backdrivable knee exoskeleton. The mitigation of discomfort is treated as mechanical design and control issues and three solutions are proposed in this paper: 1) a new wearable structure optimizes the strap attachment configuration and suit layout to ameliorate excessive shear forces of conventional wearable structure design; 2) rolling knee joint and double-hinge mechanisms reduce the misalignment in the sagittal and frontal plane, without increasing the mechanical complexity and inertia, respectively; 3) a low impedance mechanical transmission reduces the reflected inertia and damping of the actuator to human, thus the exoskeleton is highly-backdrivable. Kinematic simulations demonstrate that misalignment between the robot joint and knee joint can be reduced by 74% at maximum knee flexion. In experiments, the exoskeleton in the unpowered mode exhibits 1.03 Nm root mean square (RMS) low resistive torque. The torque control experiments demonstrate 0.31 Nm RMS torque tracking error in three human subjects.