 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Adjacency Matrix Configuration in GCN-based Models for Skeleton-based Action Recognition
Jun 29, 2022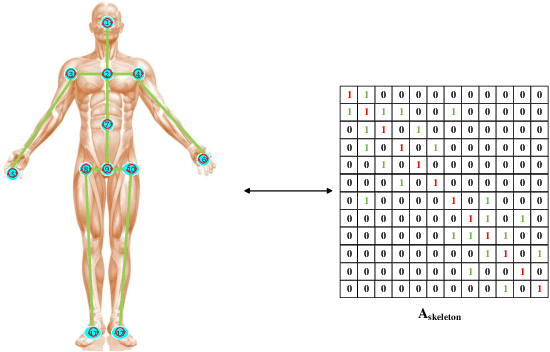
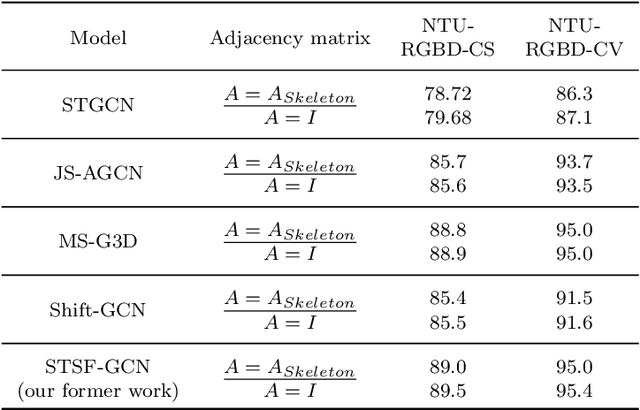
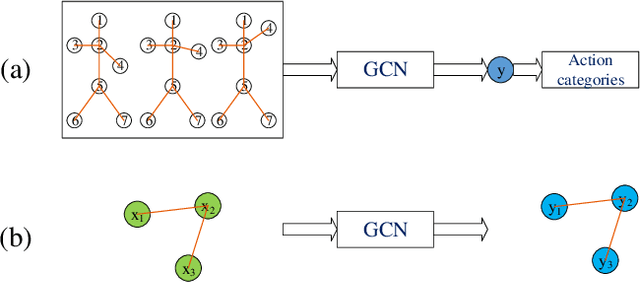
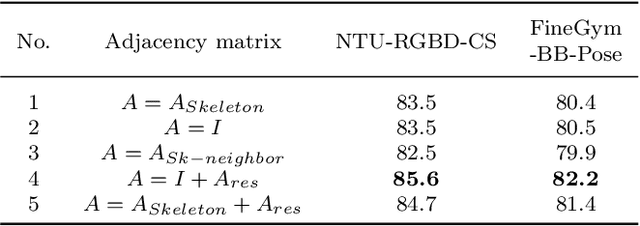
Human skeleton data has received increasing attention in action recognition due to its background robustness and high efficiency. In skeleton-based action recognition, graph convolutional network (GCN) has become the mainstream method. This paper analyzes the fundamental factor for GCN-based models -- the adjacency matrix. We notice that most GCN-based methods conduct their adjacency matrix based on the human natural skeleton structure. Based on our former work and analysis, we propose that the human natural skeleton structure adjacency matrix is not proper for skeleton-based action recognition. We propose a new adjacency matrix that abandons all rigid neighbor connections but lets the model adaptively learn the relationships of joints. We conduct extensive experiments and analysis with a validation model on two skeleton-based action recognition datasets (NTURGBD60 and FineGYM). Comprehensive experimental results and analysis reveals that 1) the most widely used human natural skeleton structure adjacency matrix is unsuitable in skeleton-based action recognition; 2) The proposed adjacency matrix is superior in model performance, noise robustness and transferability.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021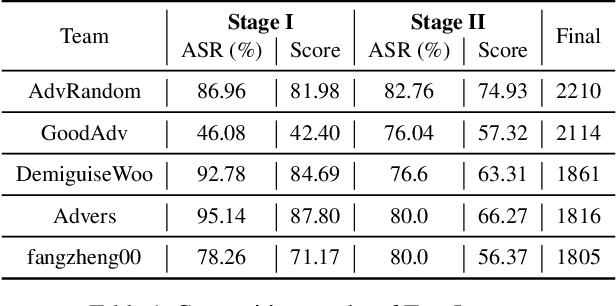
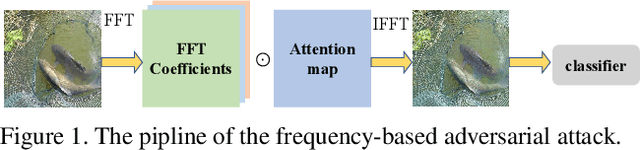
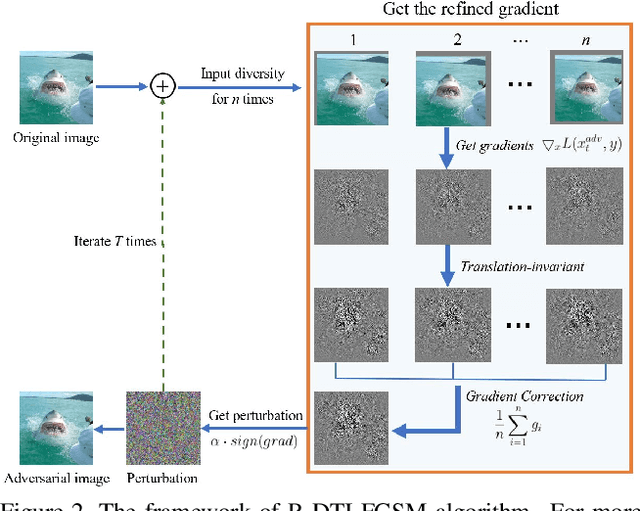
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Error Loss Networks
Jun 08, 2021



A novel model called error loss network (ELN) is proposed to build an error loss function for supervised learning. The ELN is in structure similar to a radial basis function (RBF) neural network, but its input is an error sample and output is a loss corresponding to that error sample. That means the nonlinear input-output mapper of ELN creates an error loss function. The proposed ELN provides a unified model for a large class of error loss functions, which includes some information theoretic learning (ITL) loss functions as special cases. The activation function, weight parameters and network size of the ELN can be predetermined or learned from the error samples. On this basis, we propose a new machine learning paradigm where the learning process is divided into two stages: first, learning a loss function using an ELN; second, using the learned loss function to continue to perform the learning. Experimental results are presented to demonstrate the desirable performance of the new method.
Broad Learning System Based on Maximum Correntropy Criterion
Dec 24, 2019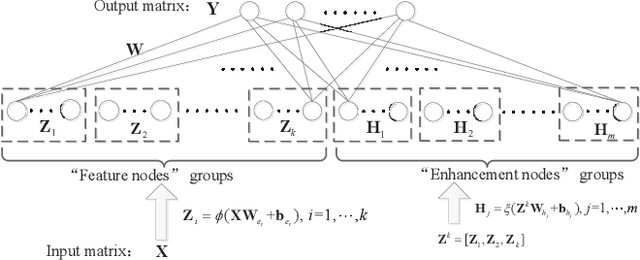
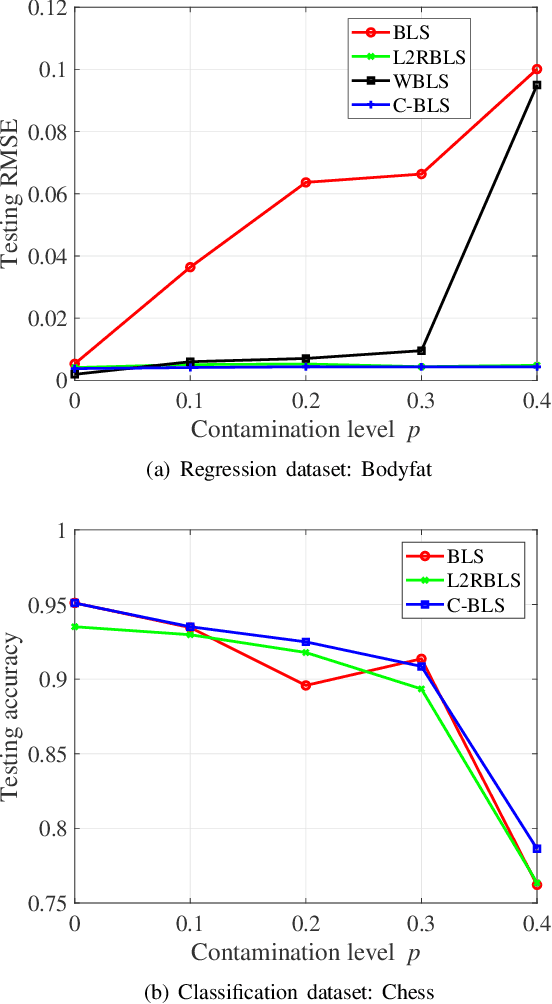
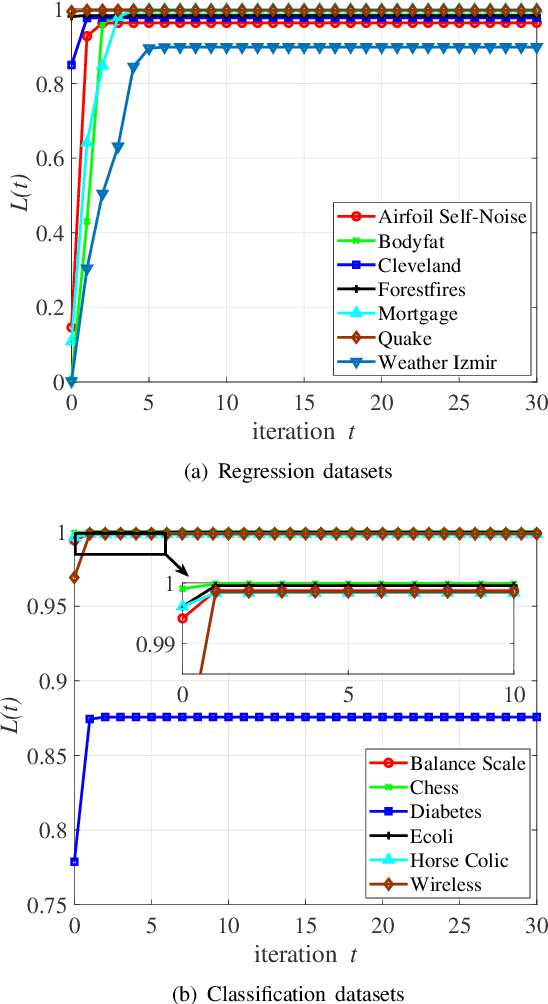
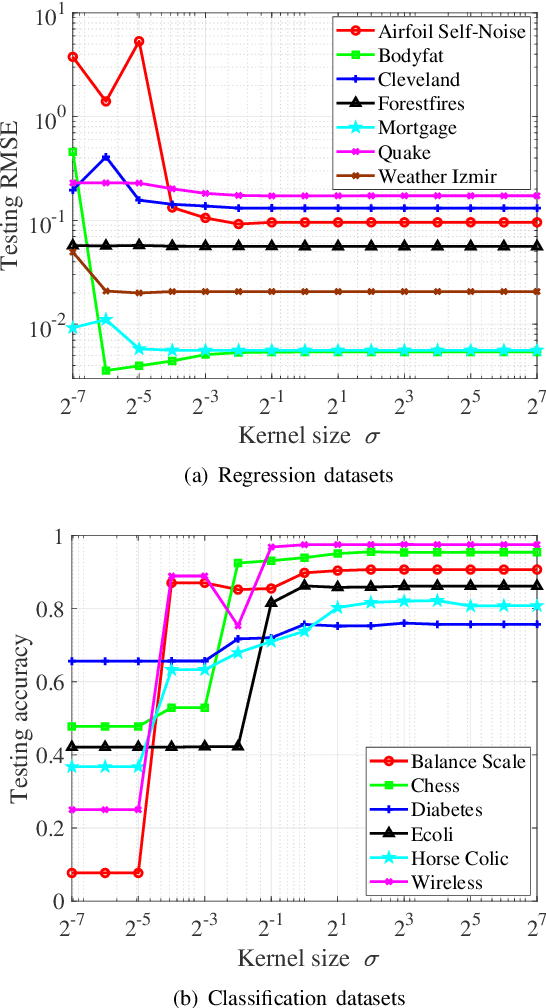
As an effective and efficient discriminative learning method, Broad Learning System (BLS) has received increasing attention due to its outstanding performance in various regression and classification problems. However, the standard BLS is derived under the minimum mean square error (MMSE) criterion, which is, of course, not always a good choice due to its sensitivity to outliers. To enhance the robustness of BLS, we propose in this work to adopt the maximum correntropy criterion (MCC) to train the output weights, obtaining a correntropy based broad learning system (C-BLS). Thanks to the inherent superiorities of MCC, the proposed C-BLS is expected to achieve excellent robustness to outliers while maintaining the original performance of the standard BLS in Gaussian or noise-free environment. In addition, three alternative incremental learning algorithms, derived from a weighted regularized least-squares solution rather than pseudoinverse formula, for C-BLS are developed.With the incremental learning algorithms, the system can be updated quickly without the entire retraining process from the beginning, when some new samples arrive or the network deems to be expanded. Experiments on various regression and classification datasets are reported to demonstrate the desirable performance of the new methods.