 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
Towards the Resistance of Neural Network Watermarking to Fine-tuning
May 02, 2025
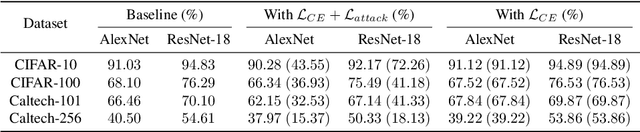


This paper proves a new watermarking method to embed the ownership information into a deep neural network (DNN), which is robust to fine-tuning. Specifically, we prove that when the input feature of a convolutional layer only contains low-frequency components, specific frequency components of the convolutional filter will not be changed by gradient descent during the fine-tuning process, where we propose a revised Fourier transform to extract frequency components from the convolutional filter. Additionally, we also prove that these frequency components are equivariant to weight scaling and weight permutations. In this way, we design a watermark module to encode the watermark information to specific frequency components in a convolutional filter. Preliminary experiments demonstrate the effectiveness of our method.
fairBERTs: Erasing Sensitive Information Through Semantic and Fairness-aware Perturbations
Jul 11, 2024Pre-trained language models (PLMs) have revolutionized both the natural language processing research and applications. However, stereotypical biases (e.g., gender and racial discrimination) encoded in PLMs have raised negative ethical implications for PLMs, which critically limits their broader applications. To address the aforementioned unfairness issues, we present fairBERTs, a general framework for learning fair fine-tuned BERT series models by erasing the protected sensitive information via semantic and fairness-aware perturbations generated by a generative adversarial network. Through extensive qualitative and quantitative experiments on two real-world tasks, we demonstrate the great superiority of fairBERTs in mitigating unfairness while maintaining the model utility. We also verify the feasibility of transferring adversarial components in fairBERTs to other conventionally trained BERT-like models for yielding fairness improvements. Our findings may shed light on further research on building fairer fine-tuned PLMs.
S-Eval: Automatic and Adaptive Test Generation for Benchmarking Safety Evaluation of Large Language Models
May 28, 2024Large Language Models have gained considerable attention for their revolutionary capabilities. However, there is also growing concern on their safety implications, making a comprehensive safety evaluation for LLMs urgently needed before model deployment. In this work, we propose S-Eval, a new comprehensive, multi-dimensional and open-ended safety evaluation benchmark. At the core of S-Eval is a novel LLM-based automatic test prompt generation and selection framework, which trains an expert testing LLM Mt combined with a range of test selection strategies to automatically construct a high-quality test suite for the safety evaluation. The key to the automation of this process is a novel expert safety-critique LLM Mc able to quantify the riskiness score of an LLM's response, and additionally produce risk tags and explanations. Besides, the generation process is also guided by a carefully designed risk taxonomy with four different levels, covering comprehensive and multi-dimensional safety risks of concern. Based on these, we systematically construct a new and large-scale safety evaluation benchmark for LLMs consisting of 220,000 evaluation prompts, including 20,000 base risk prompts (10,000 in Chinese and 10,000 in English) and 200,000 corresponding attack prompts derived from 10 popular adversarial instruction attacks against LLMs. Moreover, considering the rapid evolution of LLMs and accompanied safety threats, S-Eval can be flexibly configured and adapted to include new risks, attacks and models. S-Eval is extensively evaluated on 20 popular and representative LLMs. The results confirm that S-Eval can better reflect and inform the safety risks of LLMs compared to existing benchmarks. We also explore the impacts of parameter scales, language environments, and decoding parameters on the evaluation, providing a systematic methodology for evaluating the safety of LLMs.
Enhancing Few-shot CLIP with Semantic-Aware Fine-Tuning
Nov 09, 2023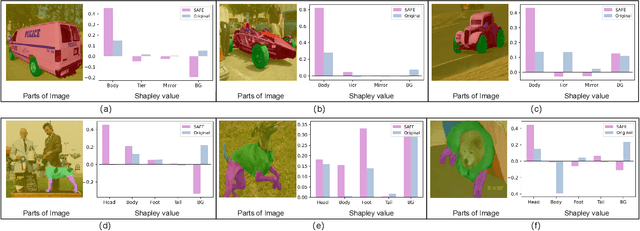
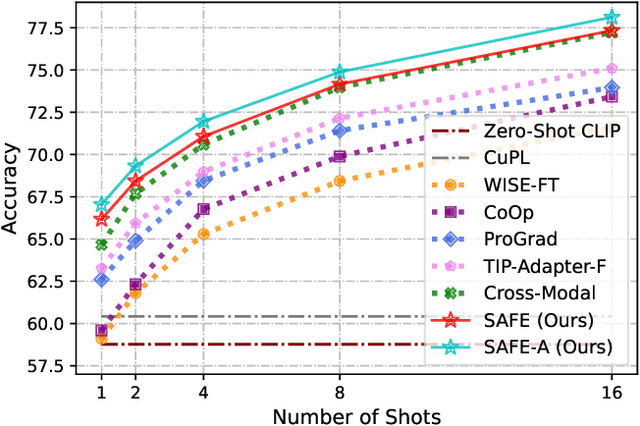
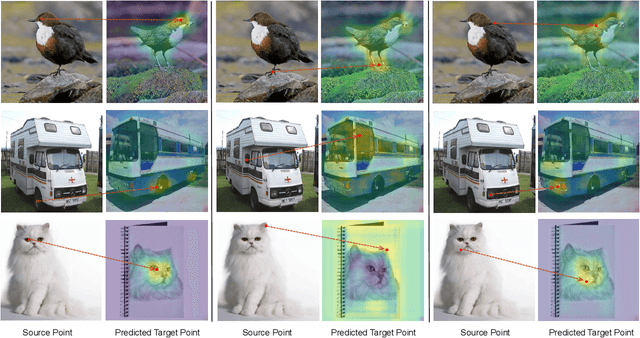
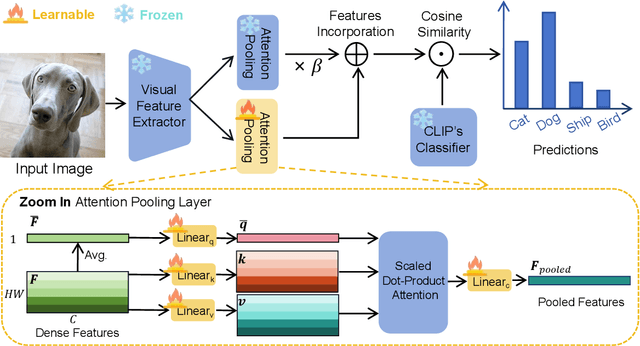
Learning generalized representations from limited training samples is crucial for applying deep neural networks in low-resource scenarios. Recently, methods based on Contrastive Language-Image Pre-training (CLIP) have exhibited promising performance in few-shot adaptation tasks. To avoid catastrophic forgetting and overfitting caused by few-shot fine-tuning, existing works usually freeze the parameters of CLIP pre-trained on large-scale datasets, overlooking the possibility that some parameters might not be suitable for downstream tasks. To this end, we revisit CLIP's visual encoder with a specific focus on its distinctive attention pooling layer, which performs a spatial weighted-sum of the dense feature maps. Given that dense feature maps contain meaningful semantic information, and different semantics hold varying importance for diverse downstream tasks (such as prioritizing semantics like ears and eyes in pet classification tasks rather than side mirrors), using the same weighted-sum operation for dense features across different few-shot tasks might not be appropriate. Hence, we propose fine-tuning the parameters of the attention pooling layer during the training process to encourage the model to focus on task-specific semantics. In the inference process, we perform residual blending between the features pooled by the fine-tuned and the original attention pooling layers to incorporate both the few-shot knowledge and the pre-trained CLIP's prior knowledge. We term this method as Semantic-Aware FinE-tuning (SAFE). SAFE is effective in enhancing the conventional few-shot CLIP and is compatible with the existing adapter approach (termed SAFE-A).
Revisiting and Exploring Efficient Fast Adversarial Training via LAW: Lipschitz Regularization and Auto Weight Averaging
Aug 22, 2023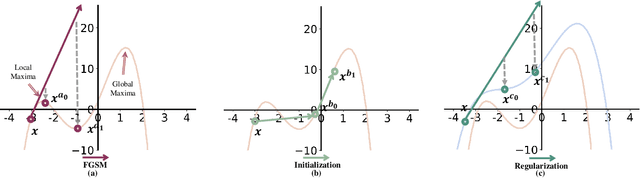
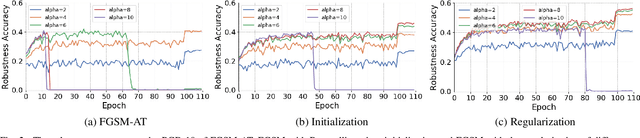
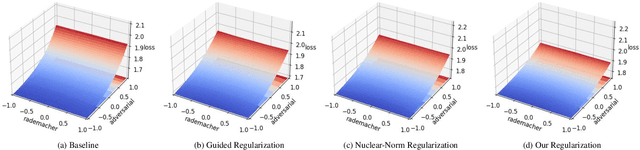
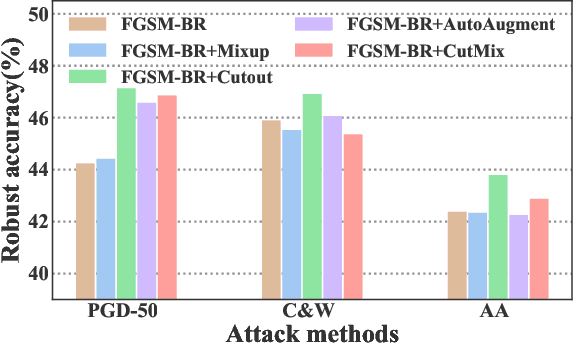
Fast Adversarial Training (FAT) not only improves the model robustness but also reduces the training cost of standard adversarial training. However, fast adversarial training often suffers from Catastrophic Overfitting (CO), which results in poor robustness performance. Catastrophic Overfitting describes the phenomenon of a sudden and significant decrease in robust accuracy during the training of fast adversarial training. Many effective techniques have been developed to prevent Catastrophic Overfitting and improve the model robustness from different perspectives. However, these techniques adopt inconsistent training settings and require different training costs, i.e, training time and memory costs, leading to unfair comparisons. In this paper, we conduct a comprehensive study of over 10 fast adversarial training methods in terms of adversarial robustness and training costs. We revisit the effectiveness and efficiency of fast adversarial training techniques in preventing Catastrophic Overfitting from the perspective of model local nonlinearity and propose an effective Lipschitz regularization method for fast adversarial training. Furthermore, we explore the effect of data augmentation and weight averaging in fast adversarial training and propose a simple yet effective auto weight averaging method to improve robustness further. By assembling these techniques, we propose a FGSM-based fast adversarial training method equipped with Lipschitz regularization and Auto Weight averaging, abbreviated as FGSM-LAW. Experimental evaluations on four benchmark databases demonstrate the superiority of the proposed method over state-of-the-art fast adversarial training methods and the advanced standard adversarial training methods.
COCO-O: A Benchmark for Object Detectors under Natural Distribution Shifts
Aug 02, 2023



Practical object detection application can lose its effectiveness on image inputs with natural distribution shifts. This problem leads the research community to pay more attention on the robustness of detectors under Out-Of-Distribution (OOD) inputs. Existing works construct datasets to benchmark the detector's OOD robustness for a specific application scenario, e.g., Autonomous Driving. However, these datasets lack universality and are hard to benchmark general detectors built on common tasks such as COCO. To give a more comprehensive robustness assessment, we introduce COCO-O(ut-of-distribution), a test dataset based on COCO with 6 types of natural distribution shifts. COCO-O has a large distribution gap with training data and results in a significant 55.7% relative performance drop on a Faster R-CNN detector. We leverage COCO-O to conduct experiments on more than 100 modern object detectors to investigate if their improvements are credible or just over-fitting to the COCO test set. Unfortunately, most classic detectors in early years do not exhibit strong OOD generalization. We further study the robustness effect on recent breakthroughs of detector's architecture design, augmentation and pre-training techniques. Some empirical findings are revealed: 1) Compared with detection head or neck, backbone is the most important part for robustness; 2) An end-to-end detection transformer design brings no enhancement, and may even reduce robustness; 3) Large-scale foundation models have made a great leap on robust object detection. We hope our COCO-O could provide a rich testbed for robustness study of object detection. The dataset will be available at https://github.com/alibaba/easyrobust/tree/main/benchmarks/coco_o.
Robust Automatic Speech Recognition via WavAugment Guided Phoneme Adversarial Training
Jul 24, 2023


Developing a practically-robust automatic speech recognition (ASR) is challenging since the model should not only maintain the original performance on clean samples, but also achieve consistent efficacy under small volume perturbations and large domain shifts. To address this problem, we propose a novel WavAugment Guided Phoneme Adversarial Training (wapat). wapat use adversarial examples in phoneme space as augmentation to make the model invariant to minor fluctuations in phoneme representation and preserve the performance on clean samples. In addition, wapat utilizes the phoneme representation of augmented samples to guide the generation of adversaries, which helps to find more stable and diverse gradient-directions, resulting in improved generalization. Extensive experiments demonstrate the effectiveness of wapat on End-to-end Speech Challenge Benchmark (ESB). Notably, SpeechLM-wapat outperforms the original model by 6.28% WER reduction on ESB, achieving the new state-of-the-art.
ImageNet-E: Benchmarking Neural Network Robustness via Attribute Editing
Mar 30, 2023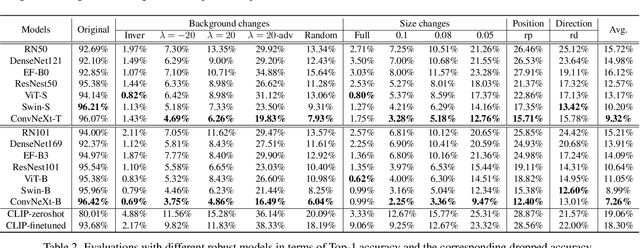
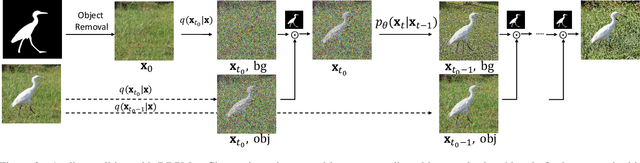

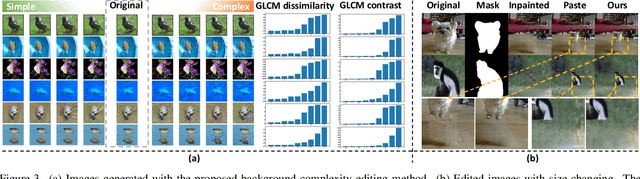
Recent studies have shown that higher accuracy on ImageNet usually leads to better robustness against different corruptions. Therefore, in this paper, instead of following the traditional research paradigm that investigates new out-of-distribution corruptions or perturbations deep models may encounter, we conduct model debugging in in-distribution data to explore which object attributes a model may be sensitive to. To achieve this goal, we create a toolkit for object editing with controls of backgrounds, sizes, positions, and directions, and create a rigorous benchmark named ImageNet-E(diting) for evaluating the image classifier robustness in terms of object attributes. With our ImageNet-E, we evaluate the performance of current deep learning models, including both convolutional neural networks and vision transformers. We find that most models are quite sensitive to attribute changes. A small change in the background can lead to an average of 9.23\% drop on top-1 accuracy. We also evaluate some robust models including both adversarially trained models and other robust trained models and find that some models show worse robustness against attribute changes than vanilla models. Based on these findings, we discover ways to enhance attribute robustness with preprocessing, architecture designs, and training strategies. We hope this work can provide some insights to the community and open up a new avenue for research in robust computer vision. The code and dataset are available at https://github.com/alibaba/easyrobust.
* Accepted by CVPR2023
TransAudio: Towards the Transferable Adversarial Audio Attack via Learning Contextualized Perturbations
Mar 28, 2023
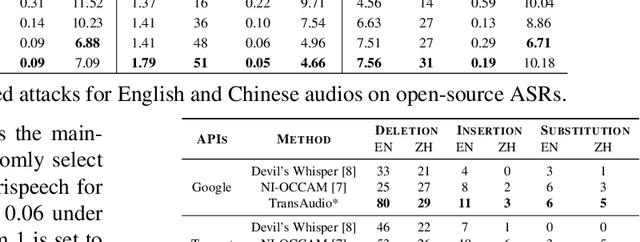

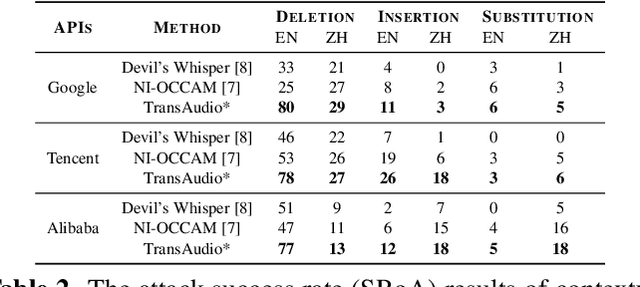
In a transfer-based attack against Automatic Speech Recognition (ASR) systems, attacks are unable to access the architecture and parameters of the target model. Existing attack methods are mostly investigated in voice assistant scenarios with restricted voice commands, prohibiting their applicability to more general ASR related applications. To tackle this challenge, we propose a novel contextualized attack with deletion, insertion, and substitution adversarial behaviors, namely TransAudio, which achieves arbitrary word-level attacks based on the proposed two-stage framework. To strengthen the attack transferability, we further introduce an audio score-matching optimization strategy to regularize the training process, which mitigates adversarial example over-fitting to the surrogate model. Extensive experiments and analysis demonstrate the effectiveness of TransAudio against open-source ASR models and commercial APIs.