 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
Jul 12, 2024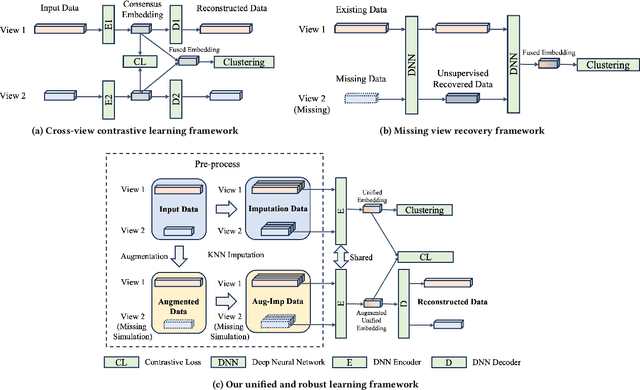
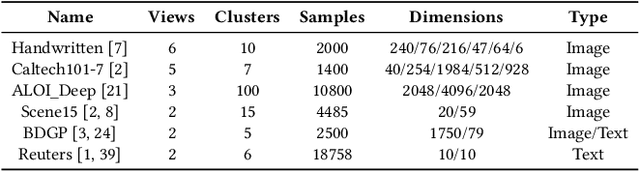
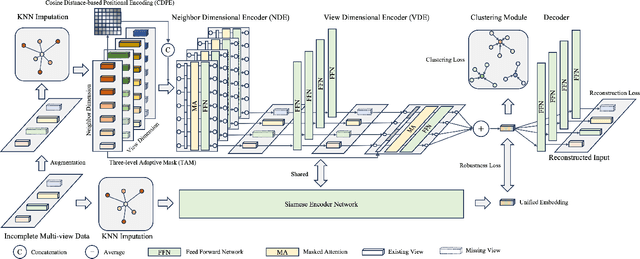
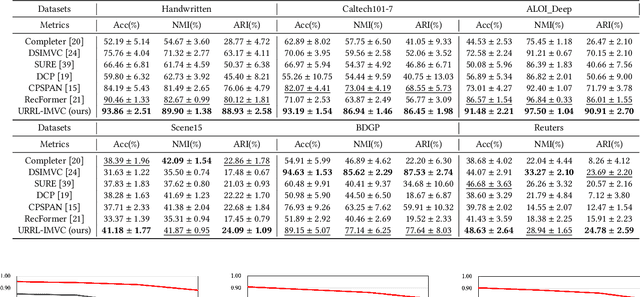
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.
Information-containing Adversarial Perturbation for Combating Facial Manipulation Systems
Mar 21, 2023



With the development of deep learning technology, the facial manipulation system has become powerful and easy to use. Such systems can modify the attributes of the given facial images, such as hair color, gender, and age. Malicious applications of such systems pose a serious threat to individuals' privacy and reputation. Existing studies have proposed various approaches to protect images against facial manipulations. Passive defense methods aim to detect whether the face is real or fake, which works for posterior forensics but can not prevent malicious manipulation. Initiative defense methods protect images upfront by injecting adversarial perturbations into images to disrupt facial manipulation systems but can not identify whether the image is fake. To address the limitation of existing methods, we propose a novel two-tier protection method named Information-containing Adversarial Perturbation (IAP), which provides more comprehensive protection for {facial images}. We use an encoder to map a facial image and its identity message to a cross-model adversarial example which can disrupt multiple facial manipulation systems to achieve initiative protection. Recovering the message in adversarial examples with a decoder serves passive protection, contributing to provenance tracking and fake image detection. We introduce a feature-level correlation measurement that is more suitable to measure the difference between the facial images than the commonly used mean squared error. Moreover, we propose a spectral diffusion method to spread messages to different frequency channels, thereby improving the robustness of the message against facial manipulation. Extensive experimental results demonstrate that our proposed IAP can recover the messages from the adversarial examples with high average accuracy and effectively disrupt the facial manipulation systems.
Rethinking Out-of-Distribution Detection From a Human-Centric Perspective
Nov 30, 2022



Out-Of-Distribution (OOD) detection has received broad attention over the years, aiming to ensure the reliability and safety of deep neural networks (DNNs) in real-world scenarios by rejecting incorrect predictions. However, we notice a discrepancy between the conventional evaluation vs. the essential purpose of OOD detection. On the one hand, the conventional evaluation exclusively considers risks caused by label-space distribution shifts while ignoring the risks from input-space distribution shifts. On the other hand, the conventional evaluation reward detection methods for not rejecting the misclassified image in the validation dataset. However, the misclassified image can also cause risks and should be rejected. We appeal to rethink OOD detection from a human-centric perspective, that a proper detection method should reject the case that the deep model's prediction mismatches the human expectations and adopt the case that the deep model's prediction meets the human expectations. We propose a human-centric evaluation and conduct extensive experiments on 45 classifiers and 8 test datasets. We find that the simple baseline OOD detection method can achieve comparable and even better performance than the recently proposed methods, which means that the development in OOD detection in the past years may be overestimated. Additionally, our experiments demonstrate that model selection is non-trivial for OOD detection and should be considered as an integral of the proposed method, which differs from the claim in existing works that proposed methods are universal across different models.
Boosting Out-of-distribution Detection with Typical Features
Oct 09, 2022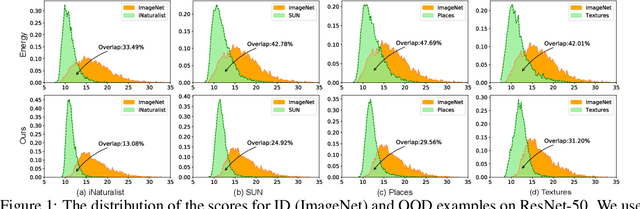
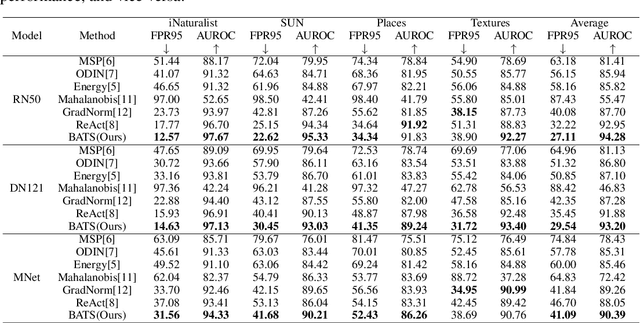

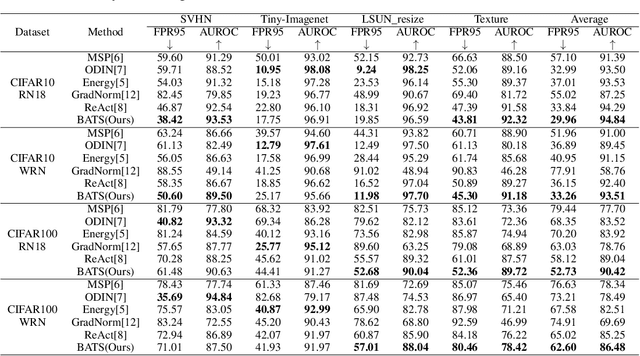
Out-of-distribution (OOD) detection is a critical task for ensuring the reliability and safety of deep neural networks in real-world scenarios. Different from most previous OOD detection methods that focus on designing OOD scores or introducing diverse outlier examples to retrain the model, we delve into the obstacle factors in OOD detection from the perspective of typicality and regard the feature's high-probability region of the deep model as the feature's typical set. We propose to rectify the feature into its typical set and calculate the OOD score with the typical features to achieve reliable uncertainty estimation. The feature rectification can be conducted as a {plug-and-play} module with various OOD scores. We evaluate the superiority of our method on both the commonly used benchmark (CIFAR) and the more challenging high-resolution benchmark with large label space (ImageNet). Notably, our approach outperforms state-of-the-art methods by up to 5.11$\%$ in the average FPR95 on the ImageNet benchmark.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
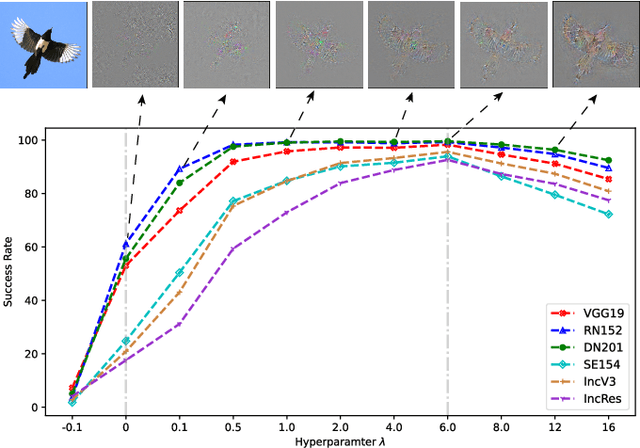
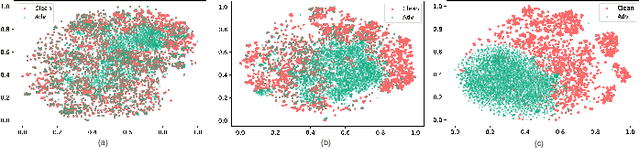
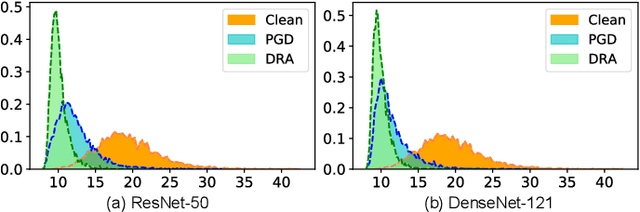
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
Spatial Likelihood Voting with Self-Knowledge Distillation for Weakly Supervised Object Detection
Apr 14, 2022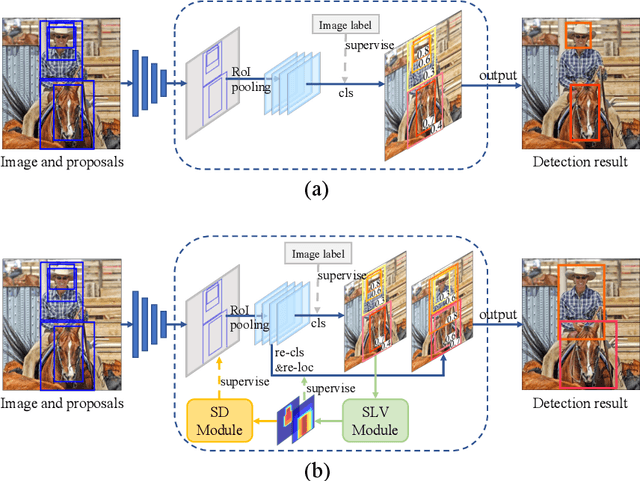
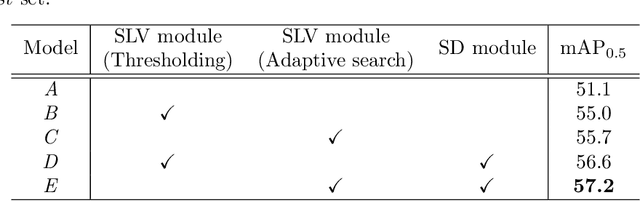
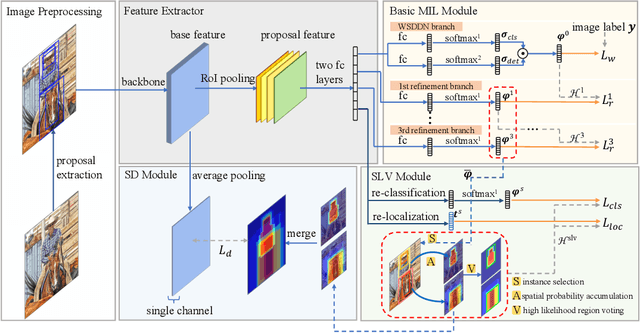

Weakly supervised object detection (WSOD), which is an effective way to train an object detection model using only image-level annotations, has attracted considerable attention from researchers. However, most of the existing methods, which are based on multiple instance learning (MIL), tend to localize instances to the discriminative parts of salient objects instead of the entire content of all objects. In this paper, we propose a WSOD framework called the Spatial Likelihood Voting with Self-knowledge Distillation Network (SLV-SD Net). In this framework, we introduce a spatial likelihood voting (SLV) module to converge region proposal localization without bounding box annotations. Specifically, in every iteration during training, all the region proposals in a given image act as voters voting for the likelihood of each category in the spatial dimensions. After dilating the alignment on the area with large likelihood values, the voting results are regularized as bounding boxes, which are then used for the final classification and localization. Based on SLV, we further propose a self-knowledge distillation (SD) module to refine the feature representations of the given image. The likelihood maps generated by the SLV module are used to supervise the feature learning of the backbone network, encouraging the network to attend to wider and more diverse areas of the image. Extensive experiments on the PASCAL VOC 2007/2012 and MS-COCO datasets demonstrate the excellent performance of SLV-SD Net. In addition, SLV-SD Net produces new state-of-the-art results on these benchmarks.
* arXiv admin note: text overlap with arXiv:2006.12884
Dynamic Supervisor for Cross-dataset Object Detection
Apr 01, 2022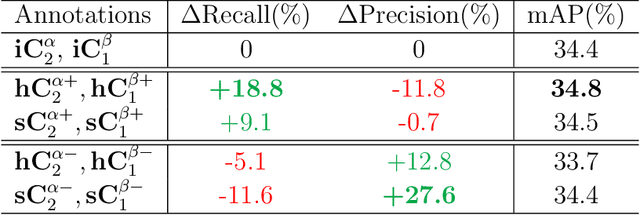
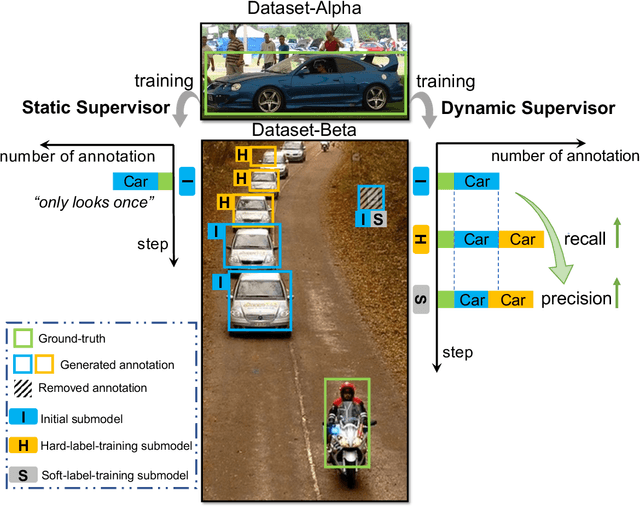

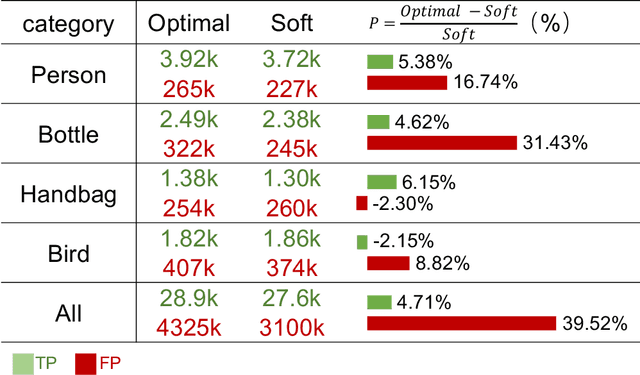
The application of cross-dataset training in object detection tasks is complicated because the inconsistency in the category range across datasets transforms fully supervised learning into semi-supervised learning. To address this problem, recent studies focus on the generation of high-quality missing annotations. In this study, we first point out that it is not enough to generate high-quality annotations using a single model, which only looks once for annotations. Through detailed experimental analyses, we further conclude that hard-label training is conducive to generating high-recall annotations, while soft-label training tends to obtain high-precision annotations. Inspired by the aspects mentioned above, we propose a dynamic supervisor framework that updates the annotations multiple times through multiple-updated submodels trained using hard and soft labels. In the final generated annotations, both recall and precision improve significantly through the integration of hard-label training with soft-label training. Extensive experiments conducted on various dataset combination settings support our analyses and demonstrate the superior performance of the proposed dynamic supervisor.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019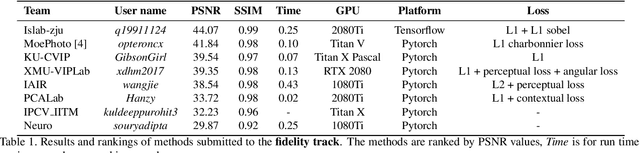
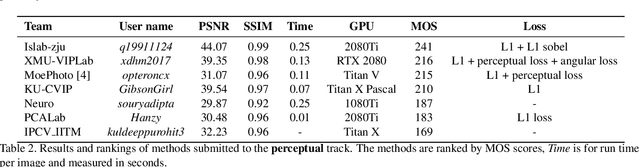
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.
Implicit Dual-domain Convolutional Network for Robust Color Image Compression Artifact Reduction
Oct 18, 2018

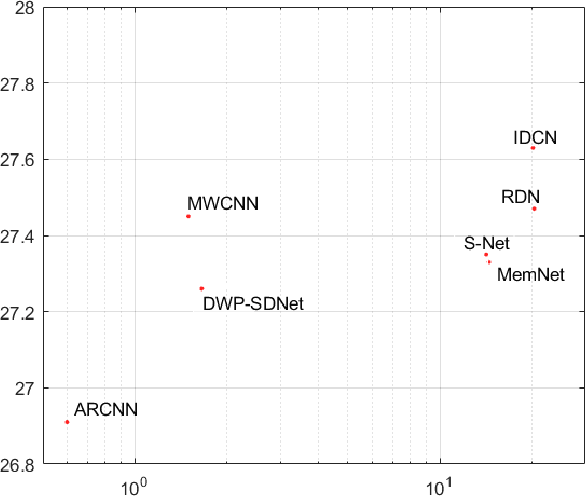
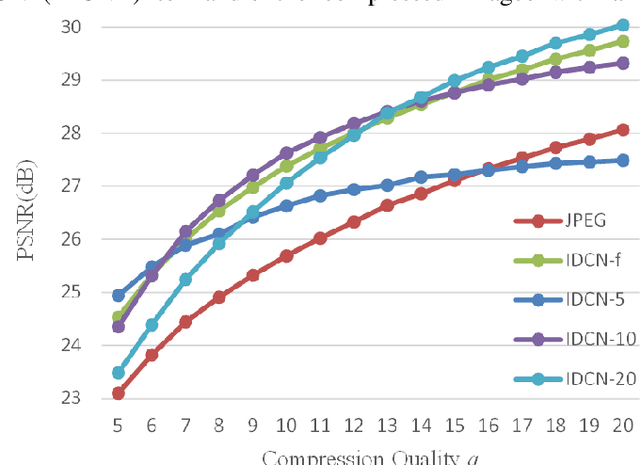
Several dual-domain convolutional neural network-based methods show outstanding performance in reducing image compression artifacts. However, they suffer from handling color images because the compression processes for gray-scale and color images are completely different. Moreover, these methods train a specific model for each compression quality and require multiple models to achieve different compression qualities. To address these problems, we proposed an implicit dual-domain convolutional network (IDCN) with the pixel position labeling map and the quantization tables as inputs. Specifically, we proposed an extractor-corrector framework-based dual-domain correction unit (DRU) as the basic component to formulate the IDCN. A dense block was introduced to improve the performance of extractor in DRU. The implicit dual-domain translation allows the IDCN to handle color images with the discrete cosine transform (DCT)-domain priors. A flexible version of IDCN (IDCN-f) was developed to handle a wide range of compression qualities. Experiments for both objective and subjective evaluations on benchmark datasets show that IDCN is superior to the state-of-the-art methods and IDCN-f exhibits excellent abilities to handle a wide range of compression qualities with little performance sacrifice and demonstrates great potential for practical applications.
S-Net: A Scalable Convolutional Neural Network for JPEG Compression Artifact Reduction
Oct 18, 2018Recent studies have used deep residual convolutional neural networks (CNNs) for JPEG compression artifact reduction. This study proposes a scalable CNN called S-Net. Our approach effectively adjusts the network scale dynamically in a multitask system for real-time operation with little performance loss. It offers a simple and direct technique to evaluate the performance gains obtained with increasing network depth, and it is helpful for removing redundant network layers to maximize the network efficiency. We implement our architecture using the Keras framework with the TensorFlow backend on an NVIDIA K80 GPU server. We train our models on the DIV2K dataset and evaluate their performance on public benchmark datasets. To validate the generality and universality of the proposed method, we created and utilized a new dataset, called WIN143, for over-processed images evaluation. Experimental results indicate that our proposed approach outperforms other CNN-based methods and achieves state-of-the-art performance.