 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Likelihood-Based Fairness Auditing: Distribution-Free Certification and Flagging
Jan 28, 2026Machine learning models in high-stakes applications, such as recidivism prediction and automated personnel selection, often exhibit systematic performance disparities across sensitive subpopulations, raising critical concerns regarding algorithmic bias. Fairness auditing addresses these risks through two primary functions: certification, which verifies adherence to fairness constraints; and flagging, which isolates specific demographic groups experiencing disparate treatment. However, existing auditing techniques are frequently limited by restrictive distributional assumptions or prohibitive computational overhead. We propose a novel empirical likelihood-based (EL) framework that constructs robust statistical measures for model performance disparities. Unlike traditional methods, our approach is non-parametric; the proposed disparity statistics follow asymptotically chi-square or mixed chi-square distributions, ensuring valid inference without assuming underlying data distributions. This framework uses a constrained optimization profile that admits stable numerical solutions, facilitating both large-scale certification and efficient subpopulation discovery. Empirically, the EL methods outperform bootstrap-based approaches, yielding coverage rates closer to nominal levels while reducing computational latency by several orders of magnitude. We demonstrate the practical utility of this framework on the COMPAS dataset, where it successfully flags intersectional biases, specifically identifying a significantly higher positive prediction rate for African-American males under 25 and a systemic under-prediction for Caucasian females relative to the population mean.
ONRW: Optimizing inversion noise for high-quality and robust watermark
Jan 24, 2026Watermarking methods have always been effective means of protecting intellectual property, yet they face significant challenges. Although existing deep learning-based watermarking systems can hide watermarks in images with minimal impact on image quality, they often lack robustness when encountering image corruptions during transmission, which undermines their practical application value. To this end, we propose a high-quality and robust watermark framework based on the diffusion model. Our method first converts the clean image into inversion noise through a null-text optimization process, and after optimizing the inversion noise in the latent space, it produces a high-quality watermarked image through an iterative denoising process of the diffusion model. The iterative denoising process serves as a powerful purification mechanism, ensuring both the visual quality of the watermarked image and enhancing the robustness of the watermark against various corruptions. To prevent the optimizing of inversion noise from distorting the original semantics of the image, we specifically introduced self-attention constraints and pseudo-mask strategies. Extensive experimental results demonstrate the superior performance of our method against various image corruptions. In particular, our method outperforms the stable signature method by an average of 10\% across 12 different image transformations on COCO datasets. Our codes are available at https://github.com/920927/ONRW.
In-Context Learning as Nonparametric Conditional Probability Estimation: Risk Bounds and Optimality
Aug 12, 2025This paper investigates the expected excess risk of In-Context Learning (ICL) for multiclass classification. We model each task as a sequence of labeled prompt samples and a query input, where a pre-trained model estimates the conditional class probabilities of the query. The expected excess risk is defined as the average truncated Kullback-Leibler (KL) divergence between the predicted and ground-truth conditional class distributions, averaged over a specified family of tasks. We establish a new oracle inequality for the expected excess risk based on KL divergence in multiclass classification. This allows us to derive tight upper and lower bounds for the expected excess risk in transformer-based models, demonstrating that the ICL estimator achieves the minimax optimal rate - up to a logarithmic factor - for conditional probability estimation. From a technical standpoint, our results introduce a novel method for controlling generalization error using the uniform empirical covering entropy of the log-likelihood function class. Furthermore, we show that multilayer perceptrons (MLPs) can also perform ICL and achieve this optimal rate under specific assumptions, suggesting that transformers may not be the exclusive architecture capable of effective ICL.
A Sliding Layer Merging Method for Efficient Depth-Wise Pruning in LLMs
Feb 26, 2025Compared to width-wise pruning, depth-wise pruning can significantly accelerate inference in resource-constrained scenarios. Howerver, treating the entire Transformer layer as the minimum pruning unit may degrade model performance by indiscriminately discarding the entire information of the layer. This paper reveals the "Patch-like" feature relationship between layers in large language models by analyzing the correlation of the outputs of different layers in the reproducing kernel Hilbert space. Building on this observation, we proposes a sliding layer merging method that dynamically selects and fuses consecutive layers from top to bottom according to a pre-defined similarity threshold, thereby simplifying the model structure while maintaining its performance. Extensive experiments on LLMs with various architectures and different parameter scales show that our method outperforms existing pruning techniques in both zero-shot inference performance and retraining recovery quality after pruning. In particular, in the experiment with 35\% pruning on the Vicuna-7B model, our method achieved a 1.654\% improvement in average performance on zero-shot tasks compared to the existing method. Moreover, we further reveal the potential of combining depth pruning with width pruning to enhance the pruning effect. Our codes are available at https://github.com/920927/SLM-a-sliding-layer-merging-method.
An Efficient Framework for Enhancing Discriminative Models via Diffusion Techniques
Dec 12, 2024Image classification serves as the cornerstone of computer vision, traditionally achieved through discriminative models based on deep neural networks. Recent advancements have introduced classification methods derived from generative models, which offer the advantage of zero-shot classification. However, these methods suffer from two main drawbacks: high computational overhead and inferior performance compared to discriminative models. Inspired by the coordinated cognitive processes of rapid-slow pathway interactions in the human brain during visual signal recognition, we propose the Diffusion-Based Discriminative Model Enhancement Framework (DBMEF). This framework seamlessly integrates discriminative and generative models in a training-free manner, leveraging discriminative models for initial predictions and endowing deep neural networks with rethinking capabilities via diffusion models. Consequently, DBMEF can effectively enhance the classification accuracy and generalization capability of discriminative models in a plug-and-play manner. We have conducted extensive experiments across 17 prevalent deep model architectures with different training methods, including both CNN-based models such as ResNet and Transformer-based models like ViT, to demonstrate the effectiveness of the proposed DBMEF. Specifically, the framework yields a 1.51\% performance improvement for ResNet-50 on the ImageNet dataset and 3.02\% on the ImageNet-A dataset. In conclusion, our research introduces a novel paradigm for image classification, demonstrating stable improvements across different datasets and neural networks.
DSDE: Using Proportion Estimation to Improve Model Selection for Out-of-Distribution Detection
Nov 03, 2024
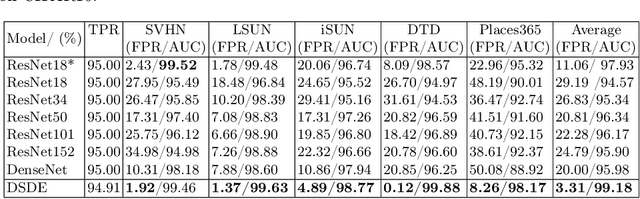

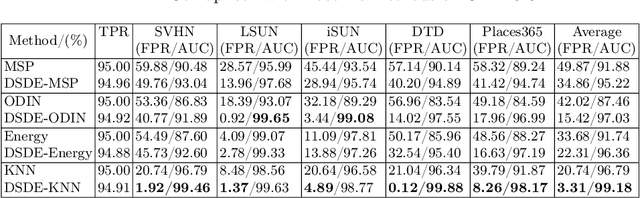
Model library is an effective tool for improving the performance of single-model Out-of-Distribution (OoD) detector, mainly through model selection and detector fusion. However, existing methods in the literature do not provide uncertainty quantification for model selection results. Additionally, the model ensemble process primarily focuses on controlling the True Positive Rate (TPR) while neglecting the False Positive Rate (FPR). In this paper, we emphasize the significance of the proportion of models in the library that identify the test sample as an OoD sample. This proportion holds crucial information and directly influences the error rate of OoD detection.To address this, we propose inverting the commonly-used sequential p-value strategies. We define the rejection region initially and then estimate the error rate. Furthermore, we introduce a novel perspective from change-point detection and propose an approach for proportion estimation with automatic hyperparameter selection. We name the proposed approach as DOS-Storey-based Detector Ensemble (DSDE). Experimental results on CIFAR10 and CIFAR100 demonstrate the effectiveness of our approach in tackling OoD detection challenges. Specifically, the CIFAR10 experiments show that DSDE reduces the FPR from 11.07% to 3.31% compared to the top-performing single-model detector.
AdvLogo: Adversarial Patch Attack against Object Detectors based on Diffusion Models
Sep 11, 2024



With the rapid development of deep learning, object detectors have demonstrated impressive performance; however, vulnerabilities still exist in certain scenarios. Current research exploring the vulnerabilities using adversarial patches often struggles to balance the trade-off between attack effectiveness and visual quality. To address this problem, we propose a novel framework of patch attack from semantic perspective, which we refer to as AdvLogo. Based on the hypothesis that every semantic space contains an adversarial subspace where images can cause detectors to fail in recognizing objects, we leverage the semantic understanding of the diffusion denoising process and drive the process to adversarial subareas by perturbing the latent and unconditional embeddings at the last timestep. To mitigate the distribution shift that exposes a negative impact on image quality, we apply perturbation to the latent in frequency domain with the Fourier Transform. Experimental results demonstrate that AdvLogo achieves strong attack performance while maintaining high visual quality.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Provable Contrastive Continual Learning
May 29, 2024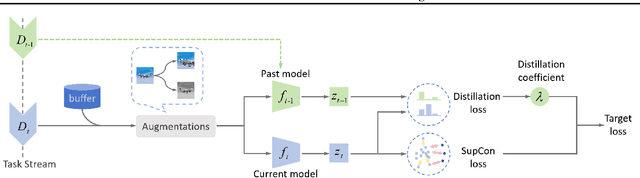


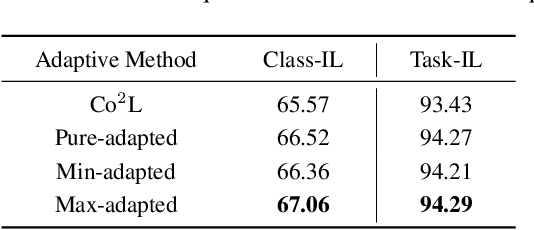
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
Enhancing Out-of-Distribution Detection with Multitesting-based Layer-wise Feature Fusion
Mar 16, 2024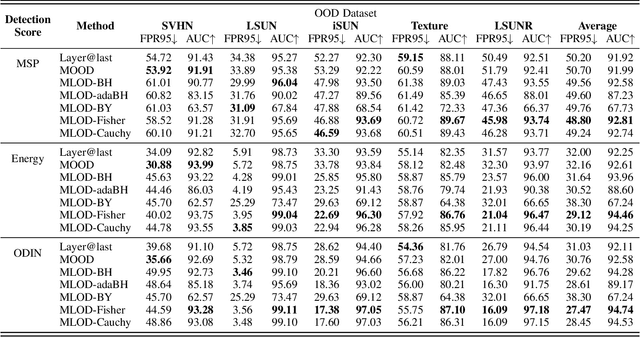
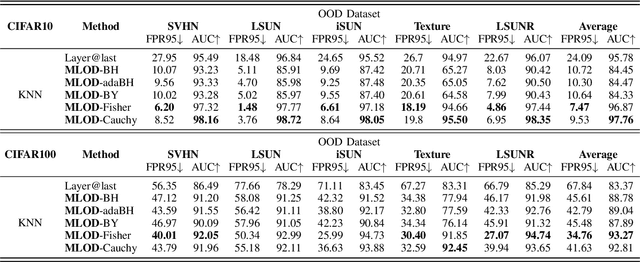
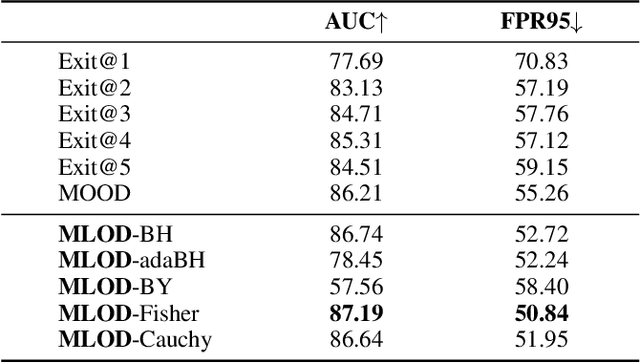
Deploying machine learning in open environments presents the challenge of encountering diverse test inputs that differ significantly from the training data. These out-of-distribution samples may exhibit shifts in local or global features compared to the training distribution. The machine learning (ML) community has responded with a number of methods aimed at distinguishing anomalous inputs from original training data. However, the majority of previous studies have primarily focused on the output layer or penultimate layer of pre-trained deep neural networks. In this paper, we propose a novel framework, Multitesting-based Layer-wise Out-of-Distribution (OOD) Detection (MLOD), to identify distributional shifts in test samples at different levels of features through rigorous multiple testing procedure. Our approach distinguishes itself from existing methods as it does not require modifying the structure or fine-tuning of the pre-trained classifier. Through extensive experiments, we demonstrate that our proposed framework can seamlessly integrate with any existing distance-based inspection method while efficiently utilizing feature extractors of varying depths. Our scheme effectively enhances the performance of out-of-distribution detection when compared to baseline methods. In particular, MLOD-Fisher achieves superior performance in general. When trained using KNN on CIFAR10, MLOD-Fisher significantly lowers the false positive rate (FPR) from 24.09% to 7.47% on average compared to merely utilizing the features of the last layer.