 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Knowledge-enhanced Spatio-temporal Epidemic Forecasting
Feb 25, 2026Spatio-temporal epidemic forecasting is critical for public health management, yet existing methods often struggle with insensitivity to weak epidemic signals, over-simplified spatial relations, and unstable parameter estimation. To address these challenges, we propose the Spatio-Temporal priOr-aware Epidemic Predictor (STOEP), a novel hybrid framework that integrates implicit spatio-temporal priors and explicit expert priors. STOEP consists of three key components: (1) Case-aware Adjacency Learning (CAL), which dynamically adjusts mobility-based regional dependencies using historical infection patterns; (2) Space-informed Parameter Estimating (SPE), which employs learnable spatial priors to amplify weak epidemic signals; and (3) Filter-based Mechanistic Forecasting (FMF), which uses an expert-guided adaptive thresholding strategy to regularize epidemic parameters. Extensive experiments on real-world COVID-19 and influenza datasets demonstrate that STOEP outperforms the best baseline by 11.1% in RMSE. The system has been deployed at one provincial CDC in China to facilitate downstream applications.
STAR : Bridging Statistical and Agentic Reasoning for Large Model Performance Prediction
Feb 12, 2026As comprehensive large model evaluation becomes prohibitively expensive, predicting model performance from limited observations has become essential. However, existing statistical methods struggle with pattern shifts, data sparsity, and lack of explanation, while pure LLM methods remain unreliable. We propose STAR, a framework that bridges data-driven STatistical expectations with knowledge-driven Agentic Reasoning. STAR leverages specialized retrievers to gather external knowledge and embeds semantic features into Constrained Probabilistic Matrix Factorization (CPMF) to generate statistical expectations with uncertainty. A reasoning module guided by Expectation Violation Theory (EVT) then refines predictions through intra-family analysis, cross-model comparison, and credibility-aware aggregation, producing adjustments with traceable explanations. Extensive experiments show that STAR consistently outperforms all baselines on both score-based and rank-based metrics, delivering a 14.46% gain in total score over the strongest statistical method under extreme sparsity, with only 1--2 observed scores per test model.
Bridging the Gap Between Ideal and Real-world Evaluation: Benchmarking AI-Generated Image Detection in Challenging Scenarios
Sep 11, 2025



With the rapid advancement of generative models, highly realistic image synthesis has posed new challenges to digital security and media credibility. Although AI-generated image detection methods have partially addressed these concerns, a substantial research gap remains in evaluating their performance under complex real-world conditions. This paper introduces the Real-World Robustness Dataset (RRDataset) for comprehensive evaluation of detection models across three dimensions: 1) Scenario Generalization: RRDataset encompasses high-quality images from seven major scenarios (War and Conflict, Disasters and Accidents, Political and Social Events, Medical and Public Health, Culture and Religion, Labor and Production, and everyday life), addressing existing dataset gaps from a content perspective. 2) Internet Transmission Robustness: examining detector performance on images that have undergone multiple rounds of sharing across various social media platforms. 3) Re-digitization Robustness: assessing model effectiveness on images altered through four distinct re-digitization methods. We benchmarked 17 detectors and 10 vision-language models (VLMs) on RRDataset and conducted a large-scale human study involving 192 participants to investigate human few-shot learning capabilities in detecting AI-generated images. The benchmarking results reveal the limitations of current AI detection methods under real-world conditions and underscore the importance of drawing on human adaptability to develop more robust detection algorithms.
FLARE: A Framework for Stellar Flare Forecasting using Stellar Physical Properties and Historical Records
Feb 25, 2025
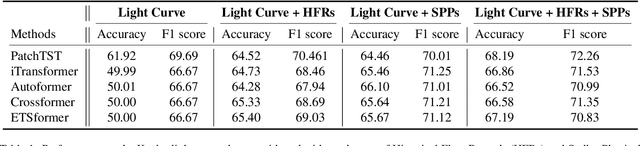
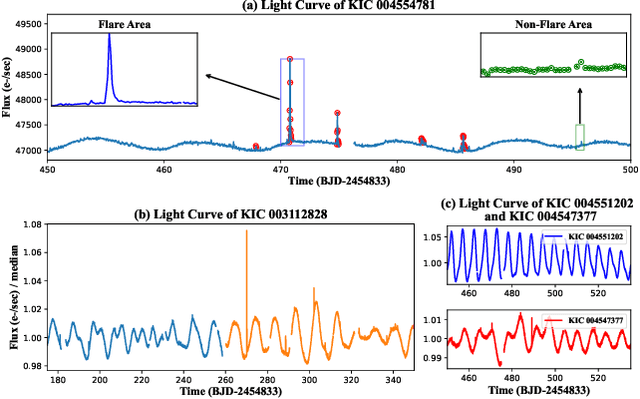
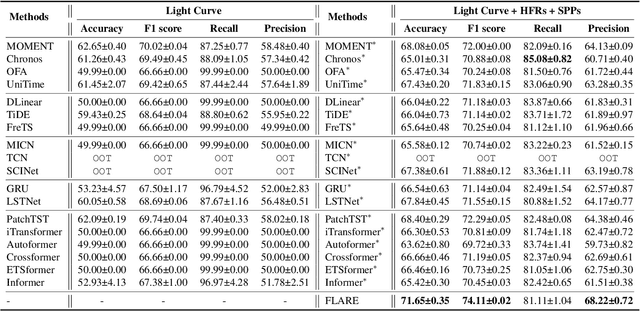
Stellar flare events are critical observational samples for astronomical research; however, recorded flare events remain limited. Stellar flare forecasting can provide additional flare event samples to support research efforts. Despite this potential, no specialized models for stellar flare forecasting have been proposed to date. In this paper, we present extensive experimental evidence demonstrating that both stellar physical properties and historical flare records are valuable inputs for flare forecasting tasks. We then introduce FLARE (Forecasting Light-curve-based Astronomical Records via features Ensemble), the first-of-its-kind large model specifically designed for stellar flare forecasting. FLARE integrates stellar physical properties and historical flare records through a novel Soft Prompt Module and Residual Record Fusion Module. Our experiments on the publicly available Kepler light curve dataset demonstrate that FLARE achieves superior performance compared to other methods across all evaluation metrics. Finally, we validate the forecast capability of our model through a comprehensive case study.
An Efficient Framework for Enhancing Discriminative Models via Diffusion Techniques
Dec 12, 2024Image classification serves as the cornerstone of computer vision, traditionally achieved through discriminative models based on deep neural networks. Recent advancements have introduced classification methods derived from generative models, which offer the advantage of zero-shot classification. However, these methods suffer from two main drawbacks: high computational overhead and inferior performance compared to discriminative models. Inspired by the coordinated cognitive processes of rapid-slow pathway interactions in the human brain during visual signal recognition, we propose the Diffusion-Based Discriminative Model Enhancement Framework (DBMEF). This framework seamlessly integrates discriminative and generative models in a training-free manner, leveraging discriminative models for initial predictions and endowing deep neural networks with rethinking capabilities via diffusion models. Consequently, DBMEF can effectively enhance the classification accuracy and generalization capability of discriminative models in a plug-and-play manner. We have conducted extensive experiments across 17 prevalent deep model architectures with different training methods, including both CNN-based models such as ResNet and Transformer-based models like ViT, to demonstrate the effectiveness of the proposed DBMEF. Specifically, the framework yields a 1.51\% performance improvement for ResNet-50 on the ImageNet dataset and 3.02\% on the ImageNet-A dataset. In conclusion, our research introduces a novel paradigm for image classification, demonstrating stable improvements across different datasets and neural networks.
Noise Diffusion for Enhancing Semantic Faithfulness in Text-to-Image Synthesis
Nov 25, 2024

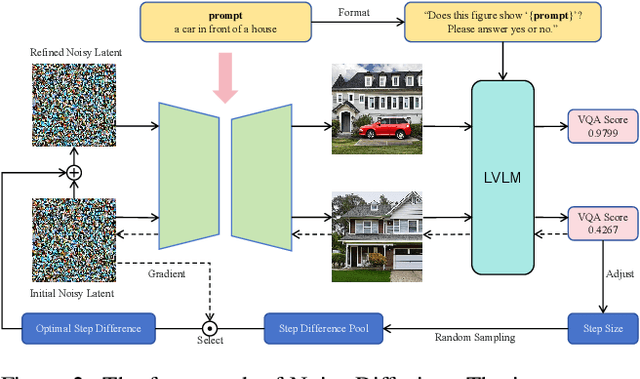

Diffusion models have achieved impressive success in generating photorealistic images, but challenges remain in ensuring precise semantic alignment with input prompts. Optimizing the initial noisy latent offers a more efficient alternative to modifying model architectures or prompt engineering for improving semantic alignment. A latest approach, InitNo, refines the initial noisy latent by leveraging attention maps; however, these maps capture only limited information, and the effectiveness of InitNo is highly dependent on the initial starting point, as it tends to converge on a local optimum near this point. To this end, this paper proposes leveraging the language comprehension capabilities of large vision-language models (LVLMs) to guide the optimization of the initial noisy latent, and introduces the Noise Diffusion process, which updates the noisy latent to generate semantically faithful images while preserving distribution consistency. Furthermore, we provide a theoretical analysis of the condition under which the update improves semantic faithfulness. Experimental results demonstrate the effectiveness and adaptability of our framework, consistently enhancing semantic alignment across various diffusion models. The code is available at https://github.com/Bomingmiao/NoiseDiffusion.
MRGazer: Decoding Eye Gaze Points from Functional Magnetic Resonance Imaging in Individual Space
Nov 27, 2023Eye-tracking research has proven valuable in understanding numerous cognitive functions. Recently, Frey et al. provided an exciting deep learning method for learning eye movements from fMRI data. However, it needed to co-register fMRI into standard space to obtain eyeballs masks, and thus required additional templates and was time consuming. To resolve this issue, in this paper, we propose a framework named MRGazer for predicting eye gaze points from fMRI in individual space. The MRGazer consisted of eyeballs extraction module and a residual network-based eye gaze prediction. Compared to the previous method, the proposed framework skips the fMRI co-registration step, simplifies the processing protocol and achieves end-to-end eye gaze regression. The proposed method achieved superior performance in a variety of eye movement tasks than the co-registration-based method, and delivered objective results within a shorter time (~ 0.02 Seconds for each volume) than prior method (~0.3 Seconds for each volume).
Opportunistic Episodic Reinforcement Learning
Oct 24, 2022



In this paper, we propose and study opportunistic reinforcement learning - a new variant of reinforcement learning problems where the regret of selecting a suboptimal action varies under an external environmental condition known as the variation factor. When the variation factor is low, so is the regret of selecting a suboptimal action and vice versa. Our intuition is to exploit more when the variation factor is high, and explore more when the variation factor is low. We demonstrate the benefit of this novel framework for finite-horizon episodic MDPs by designing and evaluating OppUCRL2 and OppPSRL algorithms. Our algorithms dynamically balance the exploration-exploitation trade-off for reinforcement learning by introducing variation factor-dependent optimism to guide exploration. We establish an $\tilde{O}(HS \sqrt{AT})$ regret bound for the OppUCRL2 algorithm and show through simulations that both OppUCRL2 and OppPSRL algorithm outperform their original corresponding algorithms.
Causal Explanation for Reinforcement Learning: Quantifying State and Temporal Importance
Oct 24, 2022Explainability plays an increasingly important role in machine learning. Because reinforcement learning (RL) involves interactions between states and actions over time, explaining an RL policy is more challenging than that of supervised learning. Furthermore, humans view the world from causal lens and thus prefer causal explanations over associational ones. Therefore, in this paper, we develop a causal explanation mechanism that quantifies the causal importance of states on actions and such importance over time. Moreover, via a series of simulation studies including crop irrigation, Blackjack, collision avoidance, and lunar lander, we demonstrate the advantages of our mechanism over state-of-the-art associational methods in terms of RL policy explanation.
FINETUNA: Fine-tuning Accelerated Molecular Simulations
May 02, 2022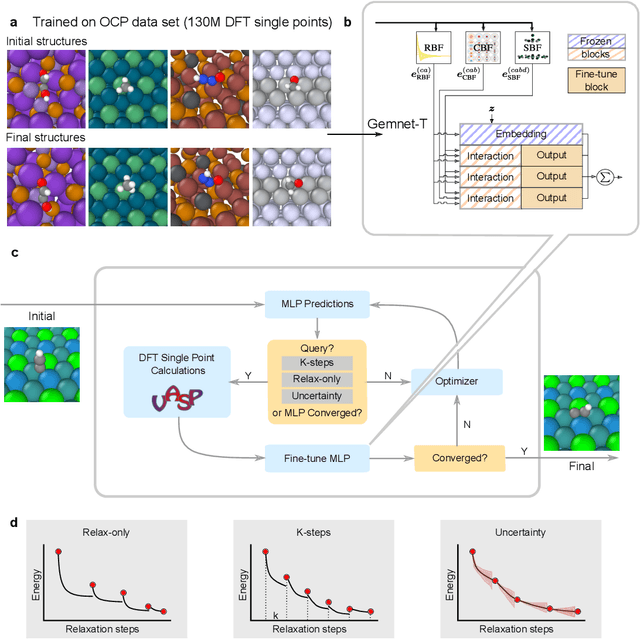
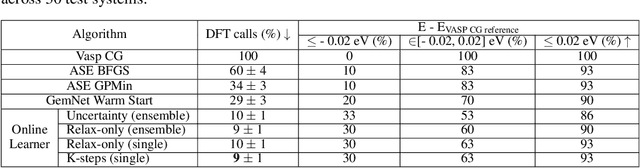
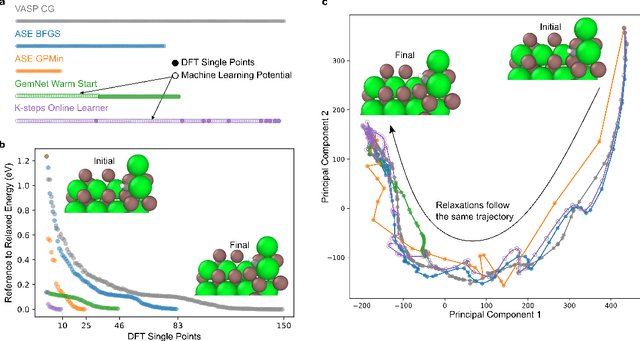
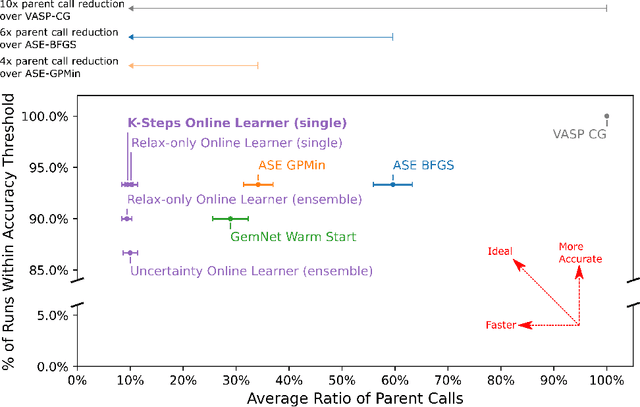
Machine learning approaches have the potential to approximate Density Functional Theory (DFT) for atomistic simulations in a computationally efficient manner, which could dramatically increase the impact of computational simulations on real-world problems. However, they are limited by their accuracy and the cost of generating labeled data. Here, we present an online active learning framework for accelerating the simulation of atomic systems efficiently and accurately by incorporating prior physical information learned by large-scale pre-trained graph neural network models from the Open Catalyst Project. Accelerating these simulations enables useful data to be generated more cheaply, allowing better models to be trained and more atomistic systems to be screened. We also present a method of comparing local optimization techniques on the basis of both their speed and accuracy. Experiments on 30 benchmark adsorbate-catalyst systems show that our method of transfer learning to incorporate prior information from pre-trained models accelerates simulations by reducing the number of DFT calculations by 91%, while meeting an accuracy threshold of 0.02 eV 93% of the time. Finally, we demonstrate a technique for leveraging the interactive functionality built in to VASP to efficiently compute single point calculations within our online active learning framework without the significant startup costs. This allows VASP to work in tandem with our framework while requiring 75% fewer self-consistent cycles than conventional single point calculations. The online active learning implementation, and examples using the VASP interactive code, are available in the open source FINETUNA package on Github.