 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVAD v2: Unified Visual Anomaly Detection via Support-Conditioned Boundary Construction
Jun 29, 2026Unified visual anomaly detection seeks to train a single detector that can be deployed across categories, domains, and application scenarios. In the few-shot transfer regime, the key challenge is to estimate an episode-specific boundary for an unseen target category from a small support set. Existing approaches mainly infer this boundary from normal-side evidence and provide limited abnormal-side evidence for deployment-specific tolerance. Within the normal side, they often struggle to jointly capture local correspondences and global support-query relations, making their boundaries less reliable for unseen anomalies. To address these issues, we propose UniVAD v2, a two-sided support-conditioned boundary construction framework for unified visual anomaly detection. Built on the component-patch divide-and-conquer framework of UniVAD, UniVAD v2 strengthens the normal side with an Optimal Transport-based Relational Modeling module (OTRM), which complements retrieval with support-query matching through transport-style allocation, and an Adaptive Coordination mechanism for Retrieval and Relational Modeling (ACRRM), which estimates episode-conditioned reliabilities to fuse the two sources of evidence. On the abnormal side, a Few-Shot Abnormal Reference module (FAR) converts optional abnormal references into rejection-side evidence for boundary adjustment. Experiments on six datasets spanning industrial, logical, and medical anomaly detection demonstrate strong cross-domain generalization. Under the 1N-shot protocol, UniVAD v2 improves the mean image-level AUC over UniVAD from 83.0\% to 84.5\%, and further reaches 85.7\% in the 1N+1A-shot setting. On the MVTec-AD Severity Split (MVTec-AD-SS), UniVAD v2 achieves 96.2\% image-level AUC and 96.9\% pixel-level AUC, showing that abnormal references enable controllable boundary customization without retraining.
Semantic Noise Reduction via Teacher-Guided Dual-Path Audio-Visual Representation Learning
Apr 09, 2026Recent advances in audio-visual representation learning have shown the value of combining contrastive alignment with masked reconstruction. However, jointly optimizing these objectives in a single forward pass forces the contrastive branch to rely on randomly visible patches designed for reconstruction rather than cross-modal alignment, introducing semantic noise and optimization interference. We propose TG-DP, a Teacher-Guided Dual-Path framework that decouples reconstruction and alignment into separate optimization paths. By disentangling the masking regimes of the two branches, TG-DP enables the contrastive pathway to use a visibility pattern better suited to cross-modal alignment. A teacher model further provides auxiliary guidance for organizing visible tokens in this branch, helping reduce interference and stabilize cross-modal representation learning. TG-DP achieves state-of-the-art performance in zero-shot retrieval. On AudioSet, it improves R@1 from 35.2\% to 37.4\% for video-to-audio retrieval and from 27.9\% to 37.1\% for audio-to-video retrieval. The learned representations also remain semantically robust, achieving state-of-the-art linear-probe performance on AS20K and VGGSound. Taken together, our results suggest that decoupling multimodal objectives and introducing teacher-guided structure into the contrastive pathway provide an effective framework for improving large-scale audio-visual pretraining. Code is available at https://github.com/wanglg20/TG-DP.
AnomalyMoE: Towards a Language-free Generalist Model for Unified Visual Anomaly Detection
Aug 08, 2025Anomaly detection is a critical task across numerous domains and modalities, yet existing methods are often highly specialized, limiting their generalizability. These specialized models, tailored for specific anomaly types like textural defects or logical errors, typically exhibit limited performance when deployed outside their designated contexts. To overcome this limitation, we propose AnomalyMoE, a novel and universal anomaly detection framework based on a Mixture-of-Experts (MoE) architecture. Our key insight is to decompose the complex anomaly detection problem into three distinct semantic hierarchies: local structural anomalies, component-level semantic anomalies, and global logical anomalies. AnomalyMoE correspondingly employs three dedicated expert networks at the patch, component, and global levels, and is specialized in reconstructing features and identifying deviations at its designated semantic level. This hierarchical design allows a single model to concurrently understand and detect a wide spectrum of anomalies. Furthermore, we introduce an Expert Information Repulsion (EIR) module to promote expert diversity and an Expert Selection Balancing (ESB) module to ensure the comprehensive utilization of all experts. Experiments on 8 challenging datasets spanning industrial imaging, 3D point clouds, medical imaging, video surveillance, and logical anomaly detection demonstrate that AnomalyMoE establishes new state-of-the-art performance, significantly outperforming specialized methods in their respective domains.
MUG: Pseudo Labeling Augmented Audio-Visual Mamba Network for Audio-Visual Video Parsing
Jul 02, 2025The weakly-supervised audio-visual video parsing (AVVP) aims to predict all modality-specific events and locate their temporal boundaries. Despite significant progress, due to the limitations of the weakly-supervised and the deficiencies of the model architecture, existing methods are lacking in simultaneously improving both the segment-level prediction and the event-level prediction. In this work, we propose a audio-visual Mamba network with pseudo labeling aUGmentation (MUG) for emphasising the uniqueness of each segment and excluding the noise interference from the alternate modalities. Specifically, we annotate some of the pseudo-labels based on previous work. Using unimodal pseudo-labels, we perform cross-modal random combinations to generate new data, which can enhance the model's ability to parse various segment-level event combinations. For feature processing and interaction, we employ a audio-visual mamba network. The AV-Mamba enhances the ability to perceive different segments and excludes additional modal noise while sharing similar modal information. Our extensive experiments demonstrate that MUG improves state-of-the-art results on LLP dataset in all metrics (e.g,, gains of 2.1% and 1.2% in terms of visual Segment-level and audio Segment-level metrics). Our code is available at https://github.com/WangLY136/MUG.
MathPhys-Guided Coarse-to-Fine Anomaly Synthesis with SQE-Driven Bi-Level Optimization for Anomaly Detection
Apr 17, 2025Anomaly detection is a crucial task in computer vision, yet collecting real-world defect images is inherently difficult due to the rarity and unpredictability of anomalies. Consequently, researchers have turned to synthetic methods for training data augmentation. However, existing synthetic strategies (e.g., naive cut-and-paste or inpainting) overlook the underlying physical causes of defects, leading to inconsistent, low-fidelity anomalies that hamper model generalization to real-world complexities. In this thesis, we introduced a novel pipeline that generates synthetic anomalies through Math-Physics model guidance, refines them via a Coarse-to-Fine approach and employs a bi-level optimization strategy with a Synthesis Quality Estimator(SQE). By incorporating physical modeling of cracks, corrosion, and deformation, our method produces realistic defect masks, which are subsequently enhanced in two phases. The first stage (npcF) enforces a PDE-based consistency to achieve a globally coherent anomaly structure, while the second stage (npcF++) further improves local fidelity using wavelet transforms and boundary synergy blocks. Additionally, we leverage SQE-driven weighting, ensuring that high-quality synthetic samples receive greater emphasis during training. To validate our approach, we conducted comprehensive experiments on three widely adopted industrial anomaly detection benchmarks: MVTec AD, VisA, and BTAD. Across these datasets, the proposed pipeline achieves state-of-the-art (SOTA) results in both image-AUROC and pixel-AUROC, confirming the effectiveness of our MaPhC2F and BiSQAD.
FLARE: A Framework for Stellar Flare Forecasting using Stellar Physical Properties and Historical Records
Feb 25, 2025
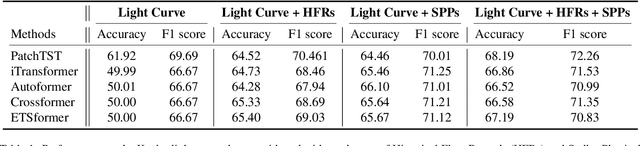
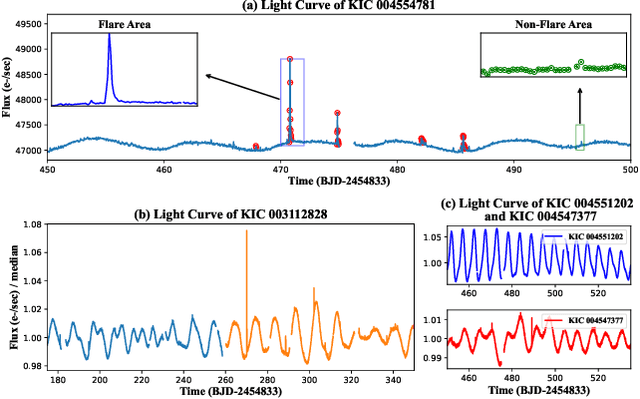
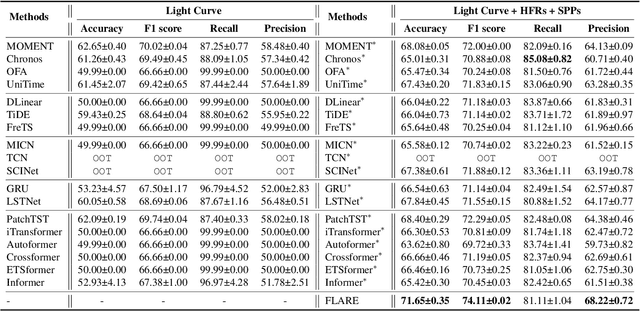
Stellar flare events are critical observational samples for astronomical research; however, recorded flare events remain limited. Stellar flare forecasting can provide additional flare event samples to support research efforts. Despite this potential, no specialized models for stellar flare forecasting have been proposed to date. In this paper, we present extensive experimental evidence demonstrating that both stellar physical properties and historical flare records are valuable inputs for flare forecasting tasks. We then introduce FLARE (Forecasting Light-curve-based Astronomical Records via features Ensemble), the first-of-its-kind large model specifically designed for stellar flare forecasting. FLARE integrates stellar physical properties and historical flare records through a novel Soft Prompt Module and Residual Record Fusion Module. Our experiments on the publicly available Kepler light curve dataset demonstrate that FLARE achieves superior performance compared to other methods across all evaluation metrics. Finally, we validate the forecast capability of our model through a comprehensive case study.
FiLo++: Zero-/Few-Shot Anomaly Detection by Fused Fine-Grained Descriptions and Deformable Localization
Jan 17, 2025



Anomaly detection methods typically require extensive normal samples from the target class for training, limiting their applicability in scenarios that require rapid adaptation, such as cold start. Zero-shot and few-shot anomaly detection do not require labeled samples from the target class in advance, making them a promising research direction. Existing zero-shot and few-shot approaches often leverage powerful multimodal models to detect and localize anomalies by comparing image-text similarity. However, their handcrafted generic descriptions fail to capture the diverse range of anomalies that may emerge in different objects, and simple patch-level image-text matching often struggles to localize anomalous regions of varying shapes and sizes. To address these issues, this paper proposes the FiLo++ method, which consists of two key components. The first component, Fused Fine-Grained Descriptions (FusDes), utilizes large language models to generate anomaly descriptions for each object category, combines both fixed and learnable prompt templates and applies a runtime prompt filtering method, producing more accurate and task-specific textual descriptions. The second component, Deformable Localization (DefLoc), integrates the vision foundation model Grounding DINO with position-enhanced text descriptions and a Multi-scale Deformable Cross-modal Interaction (MDCI) module, enabling accurate localization of anomalies with various shapes and sizes. In addition, we design a position-enhanced patch matching approach to improve few-shot anomaly detection performance. Experiments on multiple datasets demonstrate that FiLo++ achieves significant performance improvements compared with existing methods. Code will be available at https://github.com/CASIA-IVA-Lab/FiLo.
LINK: Adaptive Modality Interaction for Audio-Visual Video Parsing
Dec 30, 2024



Audio-visual video parsing focuses on classifying videos through weak labels while identifying events as either visible, audible, or both, alongside their respective temporal boundaries. Many methods ignore that different modalities often lack alignment, thereby introducing extra noise during modal interaction. In this work, we introduce a Learning Interaction method for Non-aligned Knowledge (LINK), designed to equilibrate the contributions of distinct modalities by dynamically adjusting their input during event prediction. Additionally, we leverage the semantic information of pseudo-labels as a priori knowledge to mitigate noise from other modalities. Our experimental findings demonstrate that our model outperforms existing methods on the LLP dataset.
UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection
Dec 05, 2024



Visual Anomaly Detection (VAD) aims to identify abnormal samples in images that deviate from normal patterns, covering multiple domains, including industrial, logical, and medical fields. Due to the domain gaps between these fields, existing VAD methods are typically tailored to each domain, with specialized detection techniques and model architectures that are difficult to generalize across different domains. Moreover, even within the same domain, current VAD approaches often follow a "one-category-one-model" paradigm, requiring large amounts of normal samples to train class-specific models, resulting in poor generalizability and hindering unified evaluation across domains. To address this issue, we propose a generalized few-shot VAD method, UniVAD, capable of detecting anomalies across various domains, such as industrial, logical, and medical anomalies, with a training-free unified model. UniVAD only needs few normal samples as references during testing to detect anomalies in previously unseen objects, without training on the specific domain. Specifically, UniVAD employs a Contextual Component Clustering ($C^3$) module based on clustering and vision foundation models to segment components within the image accurately, and leverages Component-Aware Patch Matching (CAPM) and Graph-Enhanced Component Modeling (GECM) modules to detect anomalies at different semantic levels, which are aggregated to produce the final detection result. We conduct experiments on nine datasets spanning industrial, logical, and medical fields, and the results demonstrate that UniVAD achieves state-of-the-art performance in few-shot anomaly detection tasks across multiple domains, outperforming domain-specific anomaly detection models. The code will be made publicly available.
Precision Profile Pollution Attack on Sequential Recommenders via Influence Function
Dec 02, 2024



Sequential recommendation approaches have demonstrated remarkable proficiency in modeling user preferences. Nevertheless, they are susceptible to profile pollution attacks (PPA), wherein items are introduced into a user's interaction history deliberately to influence the recommendation list. Since retraining the model for each polluted item is time-consuming, recent PPAs estimate item influence based on gradient directions to identify the most effective attack candidates. However, the actual item representations diverge significantly from the gradients, resulting in disparate outcomes.To tackle this challenge, we introduce an INFluence Function-based Attack approach INFAttack that offers a more accurate estimation of the influence of polluting items. Specifically, we calculate the modifications to the original model using the influence function when generating polluted sequences by introducing specific items. Subsequently, we choose the sequence that has been most significantly influenced to substitute the original sequence, thus promoting the target item. Comprehensive experiments conducted on five real-world datasets illustrate that INFAttack surpasses all baseline methods and consistently delivers stable attack performance for both popular and unpopular items.