 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in LLM Structured Pruning via Function-Aware Neuron Grouping
Dec 28, 2025Large Language Models (LLMs) demonstrate impressive performance across natural language tasks but incur substantial computational and storage costs due to their scale. Post-training structured pruning offers an efficient solution. However, when few-shot calibration sets fail to adequately reflect the pretraining data distribution, existing methods exhibit limited generalization to downstream tasks. To address this issue, we propose Function-Aware Neuron Grouping (FANG), a post-training pruning framework that alleviates calibration bias by identifying and preserving neurons critical to specific function. FANG groups neurons with similar function based on the type of semantic context they process and prunes each group independently. During importance estimation within each group, tokens that strongly correlate with the functional role of the neuron group are given higher weighting. Additionally, FANG also preserves neurons that contribute across multiple context types. To achieve a better trade-off between sparsity and performance, it allocates sparsity to each block adaptively based on its functional complexity. Experiments show that FANG improves downstream accuracy while preserving language modeling performance. It achieves the state-of-the-art (SOTA) results when combined with FLAP and OBC, two representative pruning methods. Specifically, FANG outperforms FLAP and OBC by 1.5%--8.5% in average accuracy under 30% and 40% sparsity.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
AnomalyMoE: Towards a Language-free Generalist Model for Unified Visual Anomaly Detection
Aug 08, 2025Anomaly detection is a critical task across numerous domains and modalities, yet existing methods are often highly specialized, limiting their generalizability. These specialized models, tailored for specific anomaly types like textural defects or logical errors, typically exhibit limited performance when deployed outside their designated contexts. To overcome this limitation, we propose AnomalyMoE, a novel and universal anomaly detection framework based on a Mixture-of-Experts (MoE) architecture. Our key insight is to decompose the complex anomaly detection problem into three distinct semantic hierarchies: local structural anomalies, component-level semantic anomalies, and global logical anomalies. AnomalyMoE correspondingly employs three dedicated expert networks at the patch, component, and global levels, and is specialized in reconstructing features and identifying deviations at its designated semantic level. This hierarchical design allows a single model to concurrently understand and detect a wide spectrum of anomalies. Furthermore, we introduce an Expert Information Repulsion (EIR) module to promote expert diversity and an Expert Selection Balancing (ESB) module to ensure the comprehensive utilization of all experts. Experiments on 8 challenging datasets spanning industrial imaging, 3D point clouds, medical imaging, video surveillance, and logical anomaly detection demonstrate that AnomalyMoE establishes new state-of-the-art performance, significantly outperforming specialized methods in their respective domains.
A Benchmark for Crime Surveillance Video Analysis with Large Models
Feb 13, 2025Anomaly analysis in surveillance videos is a crucial topic in computer vision. In recent years, multimodal large language models (MLLMs) have outperformed task-specific models in various domains. Although MLLMs are particularly versatile, their abilities to understand anomalous concepts and details are insufficiently studied because of the outdated benchmarks of this field not providing MLLM-style QAs and efficient algorithms to assess the model's open-ended text responses. To fill this gap, we propose a benchmark for crime surveillance video analysis with large models denoted as UCVL, including 1,829 videos and reorganized annotations from the UCF-Crime and UCF-Crime Annotation datasets. We design six types of questions and generate diverse QA pairs. Then we develop detailed instructions and use OpenAI's GPT-4o for accurate assessment. We benchmark eight prevailing MLLMs ranging from 0.5B to 40B parameters, and the results demonstrate the reliability of this bench. Moreover, we finetune LLaVA-OneVision on UCVL's training set. The improvement validates our data's high quality for video anomaly analysis.
MME-Industry: A Cross-Industry Multimodal Evaluation Benchmark
Jan 28, 2025

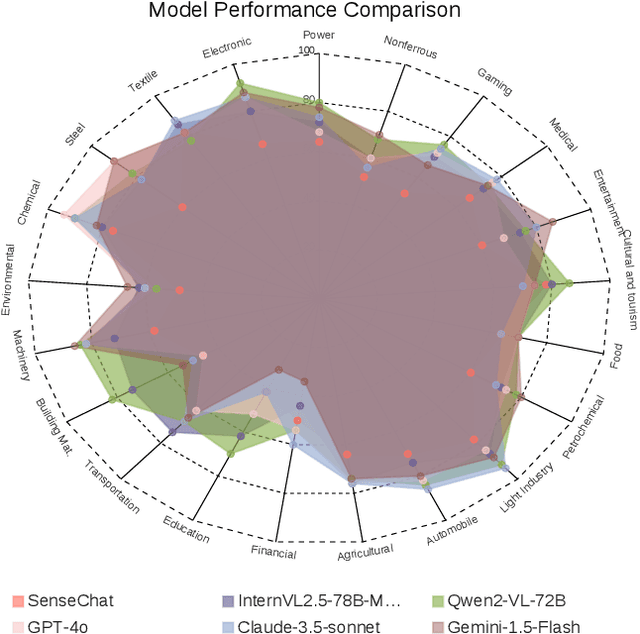
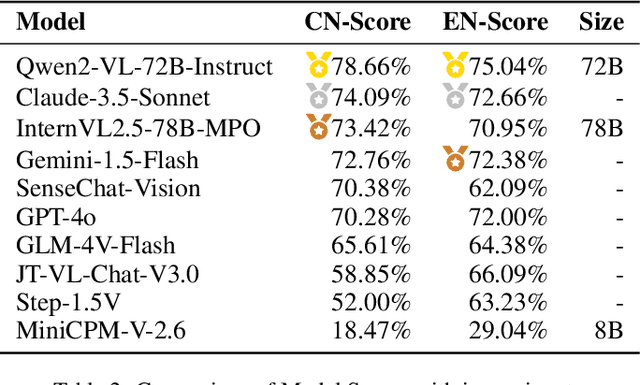
With the rapid advancement of Multimodal Large Language Models (MLLMs), numerous evaluation benchmarks have emerged. However, comprehensive assessments of their performance across diverse industrial applications remain limited. In this paper, we introduce MME-Industry, a novel benchmark designed specifically for evaluating MLLMs in industrial settings.The benchmark encompasses 21 distinct domain, comprising 1050 question-answer pairs with 50 questions per domain. To ensure data integrity and prevent potential leakage from public datasets, all question-answer pairs were manually crafted and validated by domain experts. Besides, the benchmark's complexity is effectively enhanced by incorporating non-OCR questions that can be answered directly, along with tasks requiring specialized domain knowledge. Moreover, we provide both Chinese and English versions of the benchmark, enabling comparative analysis of MLLMs' capabilities across these languages. Our findings contribute valuable insights into MLLMs' practical industrial applications and illuminate promising directions for future model optimization research.
FiLo++: Zero-/Few-Shot Anomaly Detection by Fused Fine-Grained Descriptions and Deformable Localization
Jan 17, 2025



Anomaly detection methods typically require extensive normal samples from the target class for training, limiting their applicability in scenarios that require rapid adaptation, such as cold start. Zero-shot and few-shot anomaly detection do not require labeled samples from the target class in advance, making them a promising research direction. Existing zero-shot and few-shot approaches often leverage powerful multimodal models to detect and localize anomalies by comparing image-text similarity. However, their handcrafted generic descriptions fail to capture the diverse range of anomalies that may emerge in different objects, and simple patch-level image-text matching often struggles to localize anomalous regions of varying shapes and sizes. To address these issues, this paper proposes the FiLo++ method, which consists of two key components. The first component, Fused Fine-Grained Descriptions (FusDes), utilizes large language models to generate anomaly descriptions for each object category, combines both fixed and learnable prompt templates and applies a runtime prompt filtering method, producing more accurate and task-specific textual descriptions. The second component, Deformable Localization (DefLoc), integrates the vision foundation model Grounding DINO with position-enhanced text descriptions and a Multi-scale Deformable Cross-modal Interaction (MDCI) module, enabling accurate localization of anomalies with various shapes and sizes. In addition, we design a position-enhanced patch matching approach to improve few-shot anomaly detection performance. Experiments on multiple datasets demonstrate that FiLo++ achieves significant performance improvements compared with existing methods. Code will be available at https://github.com/CASIA-IVA-Lab/FiLo.
UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection
Dec 05, 2024



Visual Anomaly Detection (VAD) aims to identify abnormal samples in images that deviate from normal patterns, covering multiple domains, including industrial, logical, and medical fields. Due to the domain gaps between these fields, existing VAD methods are typically tailored to each domain, with specialized detection techniques and model architectures that are difficult to generalize across different domains. Moreover, even within the same domain, current VAD approaches often follow a "one-category-one-model" paradigm, requiring large amounts of normal samples to train class-specific models, resulting in poor generalizability and hindering unified evaluation across domains. To address this issue, we propose a generalized few-shot VAD method, UniVAD, capable of detecting anomalies across various domains, such as industrial, logical, and medical anomalies, with a training-free unified model. UniVAD only needs few normal samples as references during testing to detect anomalies in previously unseen objects, without training on the specific domain. Specifically, UniVAD employs a Contextual Component Clustering ($C^3$) module based on clustering and vision foundation models to segment components within the image accurately, and leverages Component-Aware Patch Matching (CAPM) and Graph-Enhanced Component Modeling (GECM) modules to detect anomalies at different semantic levels, which are aggregated to produce the final detection result. We conduct experiments on nine datasets spanning industrial, logical, and medical fields, and the results demonstrate that UniVAD achieves state-of-the-art performance in few-shot anomaly detection tasks across multiple domains, outperforming domain-specific anomaly detection models. The code will be made publicly available.
Auto DragGAN: Editing the Generative Image Manifold in an Autoregressive Manner
Jul 26, 2024



Pixel-level fine-grained image editing remains an open challenge. Previous works fail to achieve an ideal trade-off between control granularity and inference speed. They either fail to achieve pixel-level fine-grained control, or their inference speed requires optimization. To address this, this paper for the first time employs a regression-based network to learn the variation patterns of StyleGAN latent codes during the image dragging process. This method enables pixel-level precision in dragging editing with little time cost. Users can specify handle points and their corresponding target points on any GAN-generated images, and our method will move each handle point to its corresponding target point. Through experimental analysis, we discover that a short movement distance from handle points to target points yields a high-fidelity edited image, as the model only needs to predict the movement of a small portion of pixels. To achieve this, we decompose the entire movement process into multiple sub-processes. Specifically, we develop a transformer encoder-decoder based network named 'Latent Predictor' to predict the latent code motion trajectories from handle points to target points in an autoregressive manner. Moreover, to enhance the prediction stability, we introduce a component named 'Latent Regularizer', aimed at constraining the latent code motion within the distribution of natural images. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) inference speed and image editing performance at the pixel-level granularity.
Recurrent Context Compression: Efficiently Expanding the Context Window of LLM
Jun 10, 2024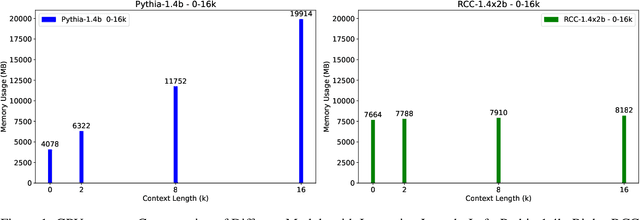

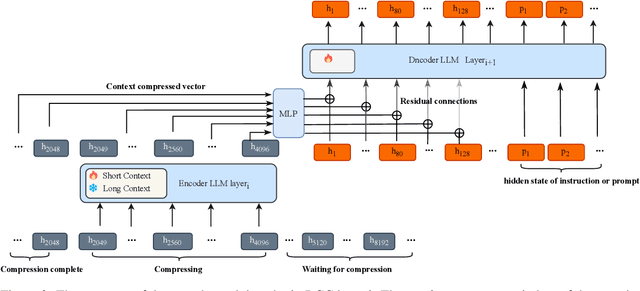

To extend the context length of Transformer-based large language models (LLMs) and improve comprehension capabilities, we often face limitations due to computational resources and bounded memory storage capacity. This work introduces a method called Recurrent Context Compression (RCC), designed to efficiently expand the context window length of LLMs within constrained storage space. We also investigate the issue of poor model responses when both instructions and context are compressed in downstream tasks, and propose an instruction reconstruction method to mitigate this problem. We validated the effectiveness of our approach on multiple tasks, achieving a compression rate of up to 32x on text reconstruction tasks with a BLEU4 score close to 0.95, and nearly 100\% accuracy on a passkey retrieval task with a sequence length of 1M. Finally, our method demonstrated competitive performance in long-text question-answering tasks compared to non-compressed methods, while significantly saving storage resources in long-text inference tasks. Our code, models, and demo are available at https://github.com/WUHU-G/RCC_Transformer
FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization
Apr 21, 2024



Zero-shot anomaly detection (ZSAD) methods entail detecting anomalies directly without access to any known normal or abnormal samples within the target item categories. Existing approaches typically rely on the robust generalization capabilities of multimodal pretrained models, computing similarities between manually crafted textual features representing "normal" or "abnormal" semantics and image features to detect anomalies and localize anomalous patches. However, the generic descriptions of "abnormal" often fail to precisely match diverse types of anomalies across different object categories. Additionally, computing feature similarities for single patches struggles to pinpoint specific locations of anomalies with various sizes and scales. To address these issues, we propose a novel ZSAD method called FiLo, comprising two components: adaptively learned Fine-Grained Description (FG-Des) and position-enhanced High-Quality Localization (HQ-Loc). FG-Des introduces fine-grained anomaly descriptions for each category using Large Language Models (LLMs) and employs adaptively learned textual templates to enhance the accuracy and interpretability of anomaly detection. HQ-Loc, utilizing Grounding DINO for preliminary localization, position-enhanced text prompts, and Multi-scale Multi-shape Cross-modal Interaction (MMCI) module, facilitates more accurate localization of anomalies of different sizes and shapes. Experimental results on datasets like MVTec and VisA demonstrate that FiLo significantly improves the performance of ZSAD in both detection and localization, achieving state-of-the-art performance with an image-level AUC of 83.9% and a pixel-level AUC of 95.9% on the VisA dataset.