 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Context Compression: Efficiently Expanding the Context Window of LLM
Jun 10, 2024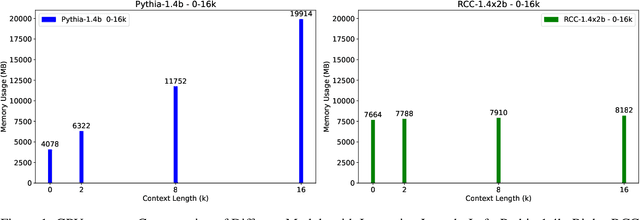

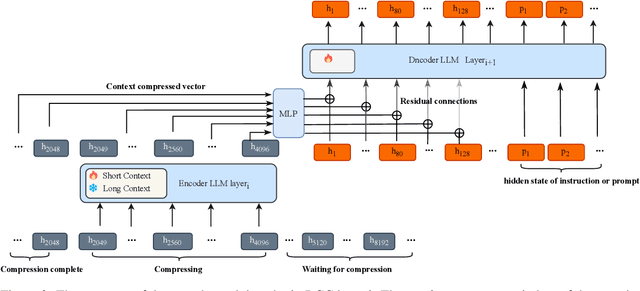

To extend the context length of Transformer-based large language models (LLMs) and improve comprehension capabilities, we often face limitations due to computational resources and bounded memory storage capacity. This work introduces a method called Recurrent Context Compression (RCC), designed to efficiently expand the context window length of LLMs within constrained storage space. We also investigate the issue of poor model responses when both instructions and context are compressed in downstream tasks, and propose an instruction reconstruction method to mitigate this problem. We validated the effectiveness of our approach on multiple tasks, achieving a compression rate of up to 32x on text reconstruction tasks with a BLEU4 score close to 0.95, and nearly 100\% accuracy on a passkey retrieval task with a sequence length of 1M. Finally, our method demonstrated competitive performance in long-text question-answering tasks compared to non-compressed methods, while significantly saving storage resources in long-text inference tasks. Our code, models, and demo are available at https://github.com/WUHU-G/RCC_Transformer
BFRFormer: Transformer-based generator for Real-World Blind Face Restoration
Feb 29, 2024Blind face restoration is a challenging task due to the unknown and complex degradation. Although face prior-based methods and reference-based methods have recently demonstrated high-quality results, the restored images tend to contain over-smoothed results and lose identity-preserved details when the degradation is severe. It is observed that this is attributed to short-range dependencies, the intrinsic limitation of convolutional neural networks. To model long-range dependencies, we propose a Transformer-based blind face restoration method, named BFRFormer, to reconstruct images with more identity-preserved details in an end-to-end manner. In BFRFormer, to remove blocking artifacts, the wavelet discriminator and aggregated attention module are developed, and spectral normalization and balanced consistency regulation are adaptively applied to address the training instability and over-fitting problem, respectively. Extensive experiments show that our method outperforms state-of-the-art methods on a synthetic dataset and four real-world datasets. The source code, Casia-Test dataset, and pre-trained models are released at https://github.com/s8Znk/BFRFormer.
We Choose to Go to Space: Agent-driven Human and Multi-Robot Collaboration in Microgravity
Feb 22, 2024



We present SpaceAgents-1, a system for learning human and multi-robot collaboration (HMRC) strategies under microgravity conditions. Future space exploration requires humans to work together with robots. However, acquiring proficient robot skills and adept collaboration under microgravity conditions poses significant challenges within ground laboratories. To address this issue, we develop a microgravity simulation environment and present three typical configurations of intra-cabin robots. We propose a hierarchical heterogeneous multi-agent collaboration architecture: guided by foundation models, a Decision-Making Agent serves as a task planner for human-robot collaboration, while individual Skill-Expert Agents manage the embodied control of robots. This mechanism empowers the SpaceAgents-1 system to execute a range of intricate long-horizon HMRC tasks.
Temporal-Channel Topology Enhanced Network for Skeleton-Based Action Recognition
Feb 25, 2023Skeleton-based action recognition has become popular in recent years due to its efficiency and robustness. Most current methods adopt graph convolutional network (GCN) for topology modeling, but GCN-based methods are limited in long-distance correlation modeling and generalizability. In contrast, the potential of convolutional neural network (CNN) for topology modeling has not been fully explored. In this paper, we propose a novel CNN architecture, Temporal-Channel Topology Enhanced Network (TCTE-Net), to learn spatial and temporal topologies for skeleton-based action recognition. The TCTE-Net consists of two modules: the Temporal-Channel Focus module, which learns a temporal-channel focus matrix to identify the most critical feature representations, and the Dynamic Channel Topology Attention module, which dynamically learns spatial topological features, and fuses them with an attention mechanism to model long-distance channel-wise topology. We conduct experiments on NTU RGB+D, NTU RGB+D 120, and FineGym datasets. TCTE-Net shows state-of-the-art performance compared to CNN-based methods and achieves superior performance compared to GCN-based methods. The code is available at https://github.com/aikuniverse/TCTE-Net.