 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Crime Surveillance Video Analysis with Large Models
Feb 13, 2025Anomaly analysis in surveillance videos is a crucial topic in computer vision. In recent years, multimodal large language models (MLLMs) have outperformed task-specific models in various domains. Although MLLMs are particularly versatile, their abilities to understand anomalous concepts and details are insufficiently studied because of the outdated benchmarks of this field not providing MLLM-style QAs and efficient algorithms to assess the model's open-ended text responses. To fill this gap, we propose a benchmark for crime surveillance video analysis with large models denoted as UCVL, including 1,829 videos and reorganized annotations from the UCF-Crime and UCF-Crime Annotation datasets. We design six types of questions and generate diverse QA pairs. Then we develop detailed instructions and use OpenAI's GPT-4o for accurate assessment. We benchmark eight prevailing MLLMs ranging from 0.5B to 40B parameters, and the results demonstrate the reliability of this bench. Moreover, we finetune LLaVA-OneVision on UCVL's training set. The improvement validates our data's high quality for video anomaly analysis.
Recurrent Context Compression: Efficiently Expanding the Context Window of LLM
Jun 10, 2024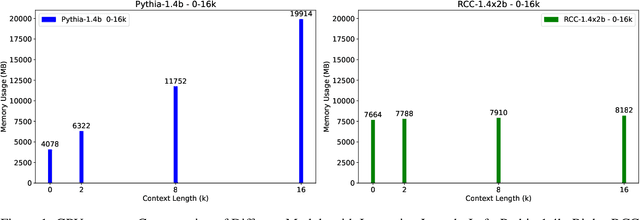

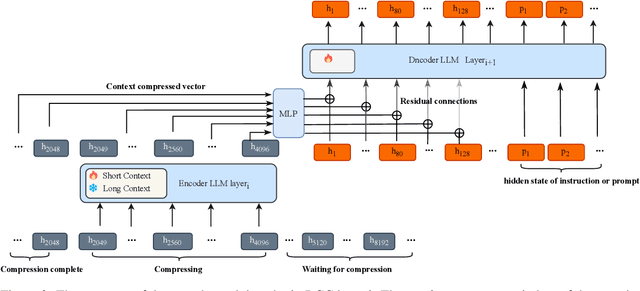

To extend the context length of Transformer-based large language models (LLMs) and improve comprehension capabilities, we often face limitations due to computational resources and bounded memory storage capacity. This work introduces a method called Recurrent Context Compression (RCC), designed to efficiently expand the context window length of LLMs within constrained storage space. We also investigate the issue of poor model responses when both instructions and context are compressed in downstream tasks, and propose an instruction reconstruction method to mitigate this problem. We validated the effectiveness of our approach on multiple tasks, achieving a compression rate of up to 32x on text reconstruction tasks with a BLEU4 score close to 0.95, and nearly 100\% accuracy on a passkey retrieval task with a sequence length of 1M. Finally, our method demonstrated competitive performance in long-text question-answering tasks compared to non-compressed methods, while significantly saving storage resources in long-text inference tasks. Our code, models, and demo are available at https://github.com/WUHU-G/RCC_Transformer