 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Responsive Materials Enhance Humanoid Safety
Jan 06, 2026Humanoid robots are envisioned as general-purpose platforms in human-centered environments, yet their deployment is limited by vulnerability to falls and the risks posed by rigid metal-plastic structures to people and surroundings. We introduce a soft-rigid co-design framework that leverages non-Newtonian fluid-based soft responsive materials to enhance humanoid safety. The material remains compliant during normal interaction but rapidly stiffens under impact, absorbing and dissipating fall-induced forces. Physics-based simulations guide protector placement and thickness and enable learning of active fall policies. Applied to a 42 kg life-size humanoid, the protector markedly reduces peak impact and allows repeated falls without hardware damage, including drops from 3 m and tumbles down long staircases. Across diverse scenarios, the approach improves robot robustness and environmental safety. By uniting responsive materials, structural co-design, and learning-based control, this work advances interact-safe, industry-ready humanoid robots.
JDPNet: A Network Based on Joint Degradation Processing for Underwater Image Enhancement
Dec 23, 2025



Given the complexity of underwater environments and the variability of water as a medium, underwater images are inevitably subject to various types of degradation. The degradations present nonlinear coupling rather than simple superposition, which renders the effective processing of such coupled degradations particularly challenging. Most existing methods focus on designing specific branches, modules, or strategies for specific degradations, with little attention paid to the potential information embedded in their coupling. Consequently, they struggle to effectively capture and process the nonlinear interactions of multiple degradations from a bottom-up perspective. To address this issue, we propose JDPNet, a joint degradation processing network, that mines and unifies the potential information inherent in coupled degradations within a unified framework. Specifically, we introduce a joint feature-mining module, along with a probabilistic bootstrap distribution strategy, to facilitate effective mining and unified adjustment of coupled degradation features. Furthermore, to balance color, clarity, and contrast, we design a novel AquaBalanceLoss to guide the network in learning from multiple coupled degradation losses. Experiments on six publicly available underwater datasets, as well as two new datasets constructed in this study, show that JDPNet exhibits state-of-the-art performance while offering a better tradeoff between performance, parameter size, and computational cost.
Preserving Cross-Modal Consistency for CLIP-based Class-Incremental Learning
Nov 14, 2025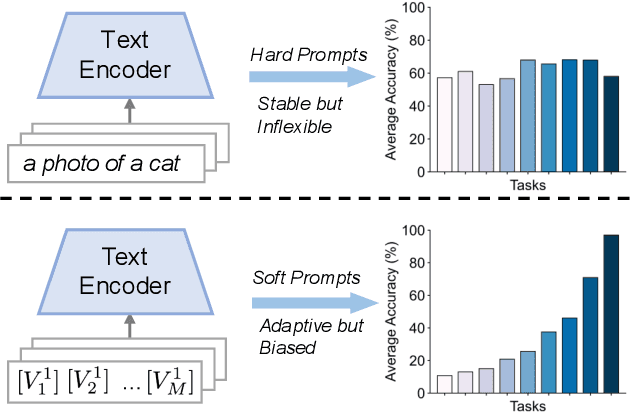
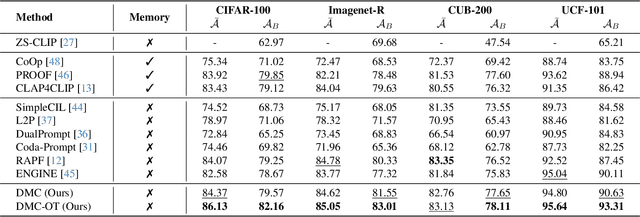
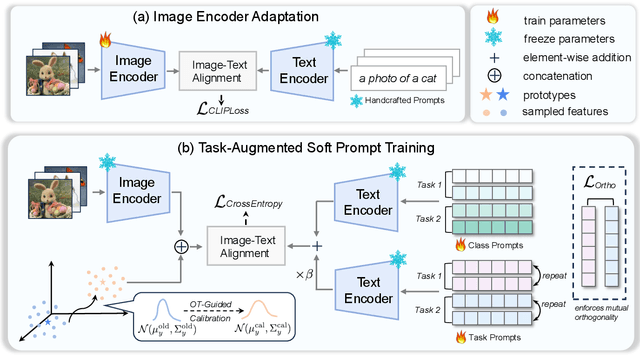
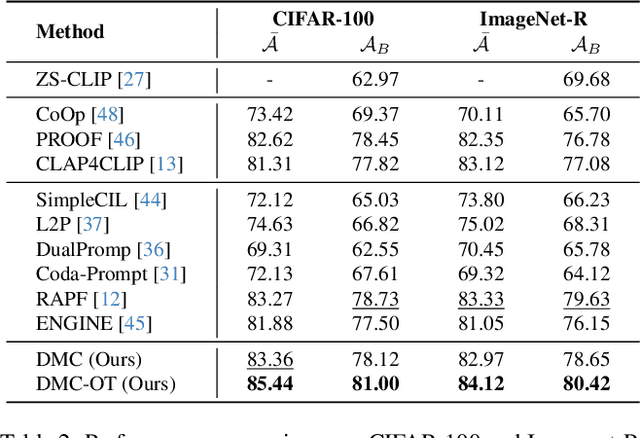
Class-incremental learning (CIL) enables models to continuously learn new categories from sequential tasks without forgetting previously acquired knowledge. While recent advances in vision-language models such as CLIP have demonstrated strong generalization across domains, extending them to continual settings remains challenging. In particular, learning task-specific soft prompts for newly introduced classes often leads to severe classifier bias, as the text prototypes overfit to recent categories when prior data are unavailable. In this paper, we propose DMC, a simple yet effective two-stage framework for CLIP-based CIL that decouples the adaptation of the vision encoder and the optimization of textual soft prompts. Each stage is trained with the other frozen, allowing one modality to act as a stable semantic anchor for the other to preserve cross-modal alignment. Furthermore, current CLIP-based CIL approaches typically store class-wise Gaussian statistics for generative replay, yet they overlook the distributional drift that arises when the vision encoder is updated over time. To address this issue, we introduce DMC-OT, an enhanced version of DMC that incorporates an optimal-transport guided calibration strategy to align memory statistics across evolving encoders, along with a task-specific prompting design that enhances inter-task separability. Extensive experiments on CIFAR-100, Imagenet-R, CUB-200, and UCF-101 demonstrate that both DMC and DMC-OT achieve state-of-the-art performance, with DMC-OT further improving accuracy by an average of 1.80%.
Co-Sight: Enhancing LLM-Based Agents via Conflict-Aware Meta-Verification and Trustworthy Reasoning with Structured Facts
Oct 24, 2025Long-horizon reasoning in LLM-based agents often fails not from generative weakness but from insufficient verification of intermediate reasoning. Co-Sight addresses this challenge by turning reasoning into a falsifiable and auditable process through two complementary mechanisms: Conflict-Aware Meta-Verification (CAMV) and Trustworthy Reasoning with Structured Facts (TRSF). CAMV reformulates verification as conflict identification and targeted falsification, allocating computation only to disagreement hotspots among expert agents rather than to full reasoning chains. This bounds verification cost to the number of inconsistencies and improves efficiency and reliability. TRSF continuously organizes, validates, and synchronizes evidence across agents through a structured facts module. By maintaining verified, traceable, and auditable knowledge, it ensures that all reasoning is grounded in consistent, source-verified information and supports transparent verification throughout the reasoning process. Together, TRSF and CAMV form a closed verification loop, where TRSF supplies structured facts and CAMV selectively falsifies or reinforces them, yielding transparent and trustworthy reasoning. Empirically, Co-Sight achieves state-of-the-art accuracy on GAIA (84.4%) and Humanity's Last Exam (35.5%), and strong results on Chinese-SimpleQA (93.8%). Ablation studies confirm that the synergy between structured factual grounding and conflict-aware verification drives these improvements. Co-Sight thus offers a scalable paradigm for reliable long-horizon reasoning in LLM-based agents. Code is available at https://github.com/ZTE-AICloud/Co-Sight/tree/cosight2.0_benchmarks.
Aerial Grasping via Maximizing Delta-Arm Workspace Utilization
Jun 18, 2025The workspace limits the operational capabilities and range of motion for the systems with robotic arms. Maximizing workspace utilization has the potential to provide more optimal solutions for aerial manipulation tasks, increasing the system's flexibility and operational efficiency. In this paper, we introduce a novel planning framework for aerial grasping that maximizes workspace utilization. We formulate an optimization problem to optimize the aerial manipulator's trajectory, incorporating task constraints to achieve efficient manipulation. To address the challenge of incorporating the delta arm's non-convex workspace into optimization constraints, we leverage a Multilayer Perceptron (MLP) to map position points to feasibility probabilities.Furthermore, we employ Reversible Residual Networks (RevNet) to approximate the complex forward kinematics of the delta arm, utilizing efficient model gradients to eliminate workspace constraints. We validate our methods in simulations and real-world experiments to demonstrate their effectiveness.
Rethinking Visual Layer Selection in Multimodal LLMs
Apr 30, 2025Multimodal large language models (MLLMs) have achieved impressive performance across a wide range of tasks, typically using CLIP-ViT as their visual encoder due to its strong text-image alignment capabilities. While prior studies suggest that different CLIP-ViT layers capture different types of information, with shallower layers focusing on fine visual details and deeper layers aligning more closely with textual semantics, most MLLMs still select visual features based on empirical heuristics rather than systematic analysis. In this work, we propose a Layer-wise Representation Similarity approach to group CLIP-ViT layers with similar behaviors into {shallow, middle, and deep} categories and assess their impact on MLLM performance. Building on this foundation, we revisit the visual layer selection problem in MLLMs at scale, training LLaVA-style models ranging from 1.4B to 7B parameters. Through extensive experiments across 10 datasets and 4 tasks, we find that: (1) deep layers are essential for OCR tasks; (2) shallow and middle layers substantially outperform deep layers on reasoning tasks involving counting, positioning, and object localization; (3) a lightweight fusion of features across shallow, middle, and deep layers consistently outperforms specialized fusion baselines and single-layer selections, achieving gains on 9 out of 10 datasets. Our work offers the first principled study of visual layer selection in MLLMs, laying the groundwork for deeper investigations into visual representation learning for MLLMs.
DAPLSR: Data Augmentation Partial Least Squares Regression Model via Manifold Optimization
Apr 23, 2025Traditional Partial Least Squares Regression (PLSR) models frequently underperform when handling data characterized by uneven categories. To address the issue, this paper proposes a Data Augmentation Partial Least Squares Regression (DAPLSR) model via manifold optimization. The DAPLSR model introduces the Synthetic Minority Over-sampling Technique (SMOTE) to increase the number of samples and utilizes the Value Difference Metric (VDM) to select the nearest neighbor samples that closely resemble the original samples for generating synthetic samples. In solving the model, in order to obtain a more accurate numerical solution for PLSR, this paper proposes a manifold optimization method that uses the geometric properties of the constraint space to improve model degradation and optimization. Comprehensive experiments show that the proposed DAPLSR model achieves superior classification performance and outstanding evaluation metrics on various datasets, significantly outperforming existing methods.
PupiNet: Seamless OCT-OCTA Interconversion Through Wavelet-Driven and Multi-Scale Attention Mechanisms
Mar 31, 2025Optical Coherence Tomography (OCT) and Optical Coherence Tomography Angiography (OCTA) are key diagnostic tools for clinical evaluation and management of retinal diseases. Compared to traditional OCT, OCTA provides richer microvascular information, but its acquisition requires specialized sensors and high-cost equipment, creating significant challenges for the clinical deployment of hardware-dependent OCTA imaging methods. Given the technical complexity of OCTA image acquisition and potential mechanical artifacts, this study proposes a bidirectional image conversion framework called PupiNet, which accurately achieves bidirectional transformation between 3D OCT and 3D OCTA. The generator module of this framework innovatively integrates wavelet transformation and multi-scale attention mechanisms, significantly enhancing image conversion quality. Meanwhile, an Adaptive Discriminator Augmentation (ADA) module has been incorporated into the discriminator to optimize model training stability and convergence efficiency. To ensure clinical accuracy of vascular structures in the converted images, we designed a Vessel Structure Matcher (VSM) supervision module, achieving precise matching of vascular morphology between generated images and target images. Additionally, the Hierarchical Feature Calibration (HFC) module further guarantees high consistency of texture details between generated images and target images across different depth levels. To rigorously validate the clinical effectiveness of the proposed method, we conducted a comprehensive evaluation on a paired OCT-OCTA image dataset containing 300 eyes with various retinal pathologies. Experimental results demonstrate that PupiNet not only reliably achieves high-quality bidirectional transformation between the two modalities but also shows significant advantages in image fidelity, vessel structure preservation, and clinical usability.
EDEN: Enhanced Diffusion for High-quality Large-motion Video Frame Interpolation
Mar 20, 2025Handling complex or nonlinear motion patterns has long posed challenges for video frame interpolation. Although recent advances in diffusion-based methods offer improvements over traditional optical flow-based approaches, they still struggle to generate sharp, temporally consistent frames in scenarios with large motion. To address this limitation, we introduce EDEN, an Enhanced Diffusion for high-quality large-motion vidEo frame iNterpolation. Our approach first utilizes a transformer-based tokenizer to produce refined latent representations of the intermediate frames for diffusion models. We then enhance the diffusion transformer with temporal attention across the process and incorporate a start-end frame difference embedding to guide the generation of dynamic motion. Extensive experiments demonstrate that EDEN achieves state-of-the-art results across popular benchmarks, including nearly a 10% LPIPS reduction on DAVIS and SNU-FILM, and an 8% improvement on DAIN-HD.
4D-ACFNet: A 4D Attention Mechanism-Based Prognostic Framework for Colorectal Cancer Liver Metastasis Integrating Multimodal Spatiotemporal Features
Mar 12, 2025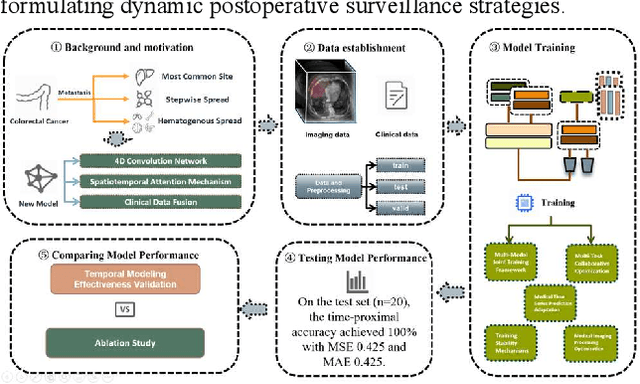

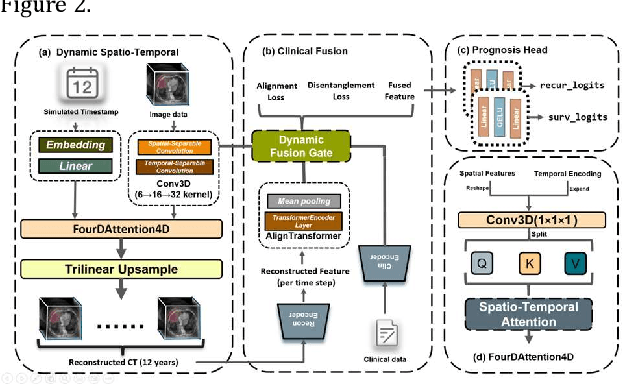

Postoperative prognostic prediction for colorectal cancer liver metastasis (CRLM) remains challenging due to tumor heterogeneity, dynamic evolution of the hepatic microenvironment, and insufficient multimodal data fusion. To address these issues, we propose 4D-ACFNet, the first framework that synergistically integrates lightweight spatiotemporal modeling, cross-modal dynamic calibration, and personalized temporal prediction within a unified architecture. Specifically, it incorporates a novel 4D spatiotemporal attention mechanism, which employs spatiotemporal separable convolution (reducing parameter count by 41%) and virtual timestamp encoding to model the interannual evolution patterns of postoperative dynamic processes, such as liver regeneration and steatosis. For cross-modal feature alignment, Transformer layers are integrated to jointly optimize modality alignment loss and disentanglement loss, effectively suppressing scale mismatch and redundant interference in clinical-imaging data. Additionally, we design a dynamic prognostic decision module that generates personalized interannual recurrence risk heatmaps through temporal upsampling and a gated classification head, overcoming the limitations of traditional methods in temporal dynamic modeling and cross-modal alignment. Experiments on 197 CRLM patients demonstrate that the model achieves 100% temporal adjacency accuracy (TAA), with performance significantly surpassing existing approaches. This study establishes the first spatiotemporal modeling paradigm for postoperative dynamic monitoring of CRLM. The proposed framework can be extended to prognostic analysis of multi-cancer metastases, advancing precision surgery from "spatial resection" to "spatiotemporal cure."