 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlyAware: Inertia-Aware Aerial Manipulation via Vision-Based Estimation and Post-Grasp Adaptation
Jan 30, 2026Aerial manipulators (AMs) are gaining increasing attention in automated transportation and emergency services due to their superior dexterity compared to conventional multirotor drones. However, their practical deployment is challenged by the complexity of time-varying inertial parameters, which are highly sensitive to payload variations and manipulator configurations. Inspired by human strategies for interacting with unknown objects, this letter presents a novel onboard framework for robust aerial manipulation. The proposed system integrates a vision-based pre-grasp inertia estimation module with a post-grasp adaptation mechanism, enabling real-time estimation and adaptation of inertial dynamics. For control, we develop an inertia-aware adaptive control strategy based on gain scheduling, and assess its robustness via frequency-domain system identification. Our study provides new insights into post-grasp control for AMs, and real-world experiments validate the effectiveness and feasibility of the proposed framework.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
SmokeBench: A Real-World Dataset for Surveillance Image Desmoking in Early-Stage Fire Scenes
Sep 16, 2025Early-stage fire scenes (0-15 minutes after ignition) represent a crucial temporal window for emergency interventions. During this stage, the smoke produced by combustion significantly reduces the visibility of surveillance systems, severely impairing situational awareness and hindering effective emergency response and rescue operations. Consequently, there is an urgent need to remove smoke from images to obtain clear scene information. However, the development of smoke removal algorithms remains limited due to the lack of large-scale, real-world datasets comprising paired smoke-free and smoke-degraded images. To address these limitations, we present a real-world surveillance image desmoking benchmark dataset named SmokeBench, which contains image pairs captured under diverse scenes setup and smoke concentration. The curated dataset provides precisely aligned degraded and clean images, enabling supervised learning and rigorous evaluation. We conduct comprehensive experiments by benchmarking a variety of desmoking methods on our dataset. Our dataset provides a valuable foundation for advancing robust and practical image desmoking in real-world fire scenes. This dataset has been released to the public and can be downloaded from https://github.com/ncfjd/SmokeBench.
IRS: Instance-Level 3D Scene Graphs via Room Prior Guided LiDAR-Camera Fusion
Jun 07, 2025Indoor scene understanding remains a fundamental challenge in robotics, with direct implications for downstream tasks such as navigation and manipulation. Traditional approaches often rely on closed-set recognition or loop closure, limiting their adaptability in open-world environments. With the advent of visual foundation models (VFMs), open-vocabulary recognition and natural language querying have become feasible, unlocking new possibilities for 3D scene graph construction. In this paper, we propose a robust and efficient framework for instance-level 3D scene graph construction via LiDAR-camera fusion. Leveraging LiDAR's wide field of view (FOV) and long-range sensing capabilities, we rapidly acquire room-level geometric priors. Multi-level VFMs are employed to improve the accuracy and consistency of semantic extraction. During instance fusion, room-based segmentation enables parallel processing, while the integration of geometric and semantic cues significantly enhances fusion accuracy and robustness. Compared to state-of-the-art methods, our approach achieves up to an order-of-magnitude improvement in construction speed while maintaining high semantic precision. Extensive experiments in both simulated and real-world environments validate the effectiveness of our approach. We further demonstrate its practical value through a language-guided semantic navigation task, highlighting its potential for real-world robotic applications.
Autonomous Flights inside Narrow Tunnels
May 26, 2025



Multirotors are usually desired to enter confined narrow tunnels that are barely accessible to humans in various applications including inspection, search and rescue, and so on. This task is extremely challenging since the lack of geometric features and illuminations, together with the limited field of view, cause problems in perception; the restricted space and significant ego airflow disturbances induce control issues. This paper introduces an autonomous aerial system designed for navigation through tunnels as narrow as 0.5 m in diameter. The real-time and online system includes a virtual omni-directional perception module tailored for the mission and a novel motion planner that incorporates perception and ego airflow disturbance factors modeled using camera projections and computational fluid dynamics analyses, respectively. Extensive flight experiments on a custom-designed quadrotor are conducted in multiple realistic narrow tunnels to validate the superior performance of the system, even over human pilots, proving its potential for real applications. Additionally, a deployment pipeline on other multirotor platforms is outlined and open-source packages are provided for future developments.
FERMI: Flexible Radio Mapping with a Hybrid Propagation Model and Scalable Autonomous Data Collection
Apr 21, 2025Communication is fundamental for multi-robot collaboration, with accurate radio mapping playing a crucial role in predicting signal strength between robots. However, modeling radio signal propagation in large and occluded environments is challenging due to complex interactions between signals and obstacles. Existing methods face two key limitations: they struggle to predict signal strength for transmitter-receiver pairs not present in the training set, while also requiring extensive manual data collection for modeling, making them impractical for large, obstacle-rich scenarios. To overcome these limitations, we propose FERMI, a flexible radio mapping framework. FERMI combines physics-based modeling of direct signal paths with a neural network to capture environmental interactions with radio signals. This hybrid model learns radio signal propagation more efficiently, requiring only sparse training data. Additionally, FERMI introduces a scalable planning method for autonomous data collection using a multi-robot team. By increasing parallelism in data collection and minimizing robot travel costs between regions, overall data collection efficiency is significantly improved. Experiments in both simulation and real-world scenarios demonstrate that FERMI enables accurate signal prediction and generalizes well to unseen positions in complex environments. It also supports fully autonomous data collection and scales to different team sizes, offering a flexible solution for creating radio maps. Our code is open-sourced at https://github.com/ymLuo1214/Flexible-Radio-Mapping.
Whole-Body Integrated Motion Planning for Aerial Manipulators
Jan 11, 2025Efficient motion planning for Aerial Manipulators (AMs) is essential for tackling complex manipulation tasks, yet achieving coupled trajectory planning remains challenging. In this work, we propose, to the best of our knowledge, the first whole-body integrated motion planning framework for aerial manipulators, which is facilitated by an improved Safe Flight Corridor (SFC) generation strategy and high-dimensional collision-free trajectory planning. In particular, we formulate an optimization problem to generate feasible trajectories for both the quadrotor and manipulator while ensuring collision avoidance, dynamic feasibility, kinematic feasibility, and waypoint constraints. To achieve collision avoidance, we introduce a variable geometry approximation method, which dynamically models the changing collision volume induced by different manipulator configurations. Moreover, waypoint constraints in our framework are defined in $\mathrm{SE(3)\times\mathbb{R}^3}$, allowing the aerial manipulator to traverse specified positions while maintaining desired attitudes and end-effector states. The effectiveness of our framework is validated through comprehensive simulations and real-world experiments across various environments.
NDOB-Based Control of a UAV with Delta-Arm Considering Manipulator Dynamics
Jan 10, 2025Aerial Manipulators (AMs) provide a versatile platform for various applications, including 3D printing, architecture, and aerial grasping missions. However, their operational speed is often sacrificed to uphold precision. Existing control strategies for AMs often regard the manipulator as a disturbance and employ robust control methods to mitigate its influence. This research focuses on elevating the precision of the end-effector and enhancing the agility of aerial manipulator movements. We present a composite control scheme to address these challenges. Initially, a Nonlinear Disturbance Observer (NDOB) is utilized to compensate for internal coupling effects and external disturbances. Subsequently, manipulator dynamics are processed through a high pass filter to facilitate agile movements. By integrating the proposed control method into a fully autonomous delta-arm-based AM system, we substantiate the controller's efficacy through extensive real-world experiments. The outcomes illustrate that the end-effector can achieve accuracy at the millimeter level.
DeRainGS: Gaussian Splatting for Enhanced Scene Reconstruction in Rainy Environments
Aug 22, 2024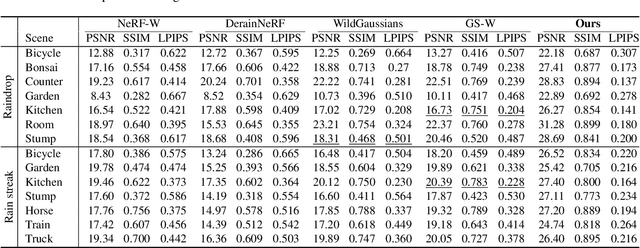


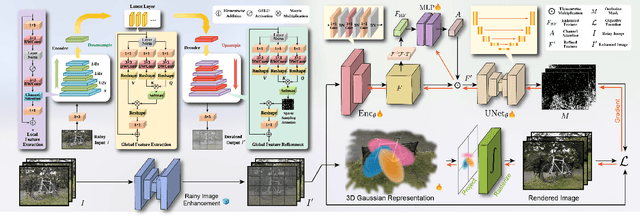
Reconstruction under adverse rainy conditions poses significant challenges due to reduced visibility and the distortion of visual perception. These conditions can severely impair the quality of geometric maps, which is essential for applications ranging from autonomous planning to environmental monitoring. In response to these challenges, this study introduces the novel task of 3D Reconstruction in Rainy Environments (3DRRE), specifically designed to address the complexities of reconstructing 3D scenes under rainy conditions. To benchmark this task, we construct the HydroViews dataset that comprises a diverse collection of both synthesized and real-world scene images characterized by various intensities of rain streaks and raindrops. Furthermore, we propose DeRainGS, the first 3DGS method tailored for reconstruction in adverse rainy environments. Extensive experiments across a wide range of rain scenarios demonstrate that our method delivers state-of-the-art performance, remarkably outperforming existing occlusion-free methods.
LSD3K: A Benchmark for Smoke Removal from Laparoscopic Surgery Images
Jul 18, 2024Smoke generated by surgical instruments during laparoscopic surgery can obscure the visual field, impairing surgeons' ability to perform operations accurately and safely. Thus, smoke removal task for laparoscopic images is highly desirable. Despite laparoscopic image desmoking has attracted the attention of researchers in recent years and several algorithms have emerged, the lack of publicly available high-quality benchmark datasets is the main bottleneck to hamper the development progress of this task. To advance this field, we construct a new high-quality dataset for Laparoscopic Surgery image Desmoking, named LSD3K, consisting of 3,000 paired synthetic non-homogeneous smoke images. In this paper, we provide a dataset generation pipeline, which includes modeling smoke shape using Blender, collecting ground-truth images from the Cholec80 dataset, random sampling of smoke masks and etc. Based on the proposed benchmark, we further conducted a comprehensive evaluation of the existing representative desmoking algorithms. The proposed dataset is publicly available at https://drive.google.com/file/d/1v0U5_3S4nJpaUiP898Q0pc-MfEAtnbOq/view?usp=sharing