 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphology-Aware Graph Reinforcement Learning for Tensegrity Robot Locomotion
Oct 30, 2025Tensegrity robots combine rigid rods and elastic cables, offering high resilience and deployability but posing major challenges for locomotion control due to their underactuated and highly coupled dynamics. This paper introduces a morphology-aware reinforcement learning framework that integrates a graph neural network (GNN) into the Soft Actor-Critic (SAC) algorithm. By representing the robot's physical topology as a graph, the proposed GNN-based policy captures coupling among components, enabling faster and more stable learning than conventional multilayer perceptron (MLP) policies. The method is validated on a physical 3-bar tensegrity robot across three locomotion primitives, including straight-line tracking and bidirectional turning. It shows superior sample efficiency, robustness to noise and stiffness variations, and improved trajectory accuracy. Notably, the learned policies transfer directly from simulation to hardware without fine-tuning, achieving stable real-world locomotion. These results demonstrate the advantages of incorporating structural priors into reinforcement learning for tensegrity robot control.
Dy3DGS-SLAM: Monocular 3D Gaussian Splatting SLAM for Dynamic Environments
Jun 06, 2025Current Simultaneous Localization and Mapping (SLAM) methods based on Neural Radiance Fields (NeRF) or 3D Gaussian Splatting excel in reconstructing static 3D scenes but struggle with tracking and reconstruction in dynamic environments, such as real-world scenes with moving elements. Existing NeRF-based SLAM approaches addressing dynamic challenges typically rely on RGB-D inputs, with few methods accommodating pure RGB input. To overcome these limitations, we propose Dy3DGS-SLAM, the first 3D Gaussian Splatting (3DGS) SLAM method for dynamic scenes using monocular RGB input. To address dynamic interference, we fuse optical flow masks and depth masks through a probabilistic model to obtain a fused dynamic mask. With only a single network iteration, this can constrain tracking scales and refine rendered geometry. Based on the fused dynamic mask, we designed a novel motion loss to constrain the pose estimation network for tracking. In mapping, we use the rendering loss of dynamic pixels, color, and depth to eliminate transient interference and occlusion caused by dynamic objects. Experimental results demonstrate that Dy3DGS-SLAM achieves state-of-the-art tracking and rendering in dynamic environments, outperforming or matching existing RGB-D methods.
LLGS: Unsupervised Gaussian Splatting for Image Enhancement and Reconstruction in Pure Dark Environment
Mar 24, 20253D Gaussian Splatting has shown remarkable capabilities in novel view rendering tasks and exhibits significant potential for multi-view optimization.However, the original 3D Gaussian Splatting lacks color representation for inputs in low-light environments. Simply using enhanced images as inputs would lead to issues with multi-view consistency, and current single-view enhancement systems rely on pre-trained data, lacking scene generalization. These problems limit the application of 3D Gaussian Splatting in low-light conditions in the field of robotics, including high-fidelity modeling and feature matching. To address these challenges, we propose an unsupervised multi-view stereoscopic system based on Gaussian Splatting, called Low-Light Gaussian Splatting (LLGS). This system aims to enhance images in low-light environments while reconstructing the scene. Our method introduces a decomposable Gaussian representation called M-Color, which separately characterizes color information for targeted enhancement. Furthermore, we propose an unsupervised optimization method with zero-knowledge priors, using direction-based enhancement to ensure multi-view consistency. Experiments conducted on real-world datasets demonstrate that our system outperforms state-of-the-art methods in both low-light enhancement and 3D Gaussian Splatting.
DenseSplat: Densifying Gaussian Splatting SLAM with Neural Radiance Prior
Feb 13, 2025Gaussian SLAM systems excel in real-time rendering and fine-grained reconstruction compared to NeRF-based systems. However, their reliance on extensive keyframes is impractical for deployment in real-world robotic systems, which typically operate under sparse-view conditions that can result in substantial holes in the map. To address these challenges, we introduce DenseSplat, the first SLAM system that effectively combines the advantages of NeRF and 3DGS. DenseSplat utilizes sparse keyframes and NeRF priors for initializing primitives that densely populate maps and seamlessly fill gaps. It also implements geometry-aware primitive sampling and pruning strategies to manage granularity and enhance rendering efficiency. Moreover, DenseSplat integrates loop closure and bundle adjustment, significantly enhancing frame-to-frame tracking accuracy. Extensive experiments on multiple large-scale datasets demonstrate that DenseSplat achieves superior performance in tracking and mapping compared to current state-of-the-art methods.
GARAD-SLAM: 3D GAussian splatting for Real-time Anti Dynamic SLAM
Feb 05, 2025



The 3D Gaussian Splatting (3DGS)-based SLAM system has garnered widespread attention due to its excellent performance in real-time high-fidelity rendering. However, in real-world environments with dynamic objects, existing 3DGS-based SLAM systems often face mapping errors and tracking drift issues. To address these problems, we propose GARAD-SLAM, a real-time 3DGS-based SLAM system tailored for dynamic scenes. In terms of tracking, unlike traditional methods, we directly perform dynamic segmentation on Gaussians and map them back to the front-end to obtain dynamic point labels through a Gaussian pyramid network, achieving precise dynamic removal and robust tracking. For mapping, we impose rendering penalties on dynamically labeled Gaussians, which are updated through the network, to avoid irreversible erroneous removal caused by simple pruning. Our results on real-world datasets demonstrate that our method is competitive in tracking compared to baseline methods, generating fewer artifacts and higher-quality reconstructions in rendering.
DeRainGS: Gaussian Splatting for Enhanced Scene Reconstruction in Rainy Environments
Aug 22, 2024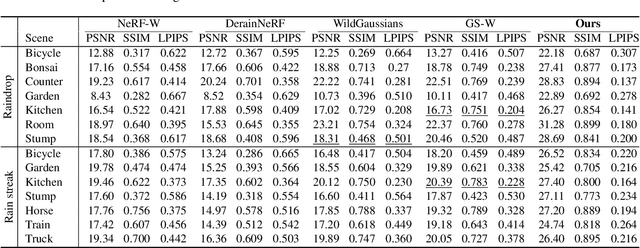


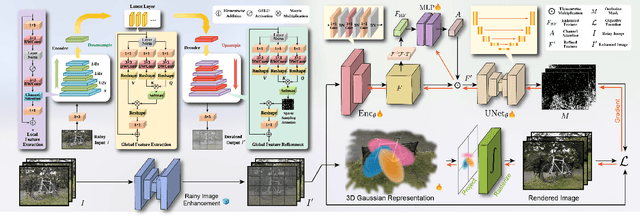
Reconstruction under adverse rainy conditions poses significant challenges due to reduced visibility and the distortion of visual perception. These conditions can severely impair the quality of geometric maps, which is essential for applications ranging from autonomous planning to environmental monitoring. In response to these challenges, this study introduces the novel task of 3D Reconstruction in Rainy Environments (3DRRE), specifically designed to address the complexities of reconstructing 3D scenes under rainy conditions. To benchmark this task, we construct the HydroViews dataset that comprises a diverse collection of both synthesized and real-world scene images characterized by various intensities of rain streaks and raindrops. Furthermore, we propose DeRainGS, the first 3DGS method tailored for reconstruction in adverse rainy environments. Extensive experiments across a wide range of rain scenarios demonstrate that our method delivers state-of-the-art performance, remarkably outperforming existing occlusion-free methods.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Structure Gaussian SLAM with Manhattan World Hypothesis
May 30, 2024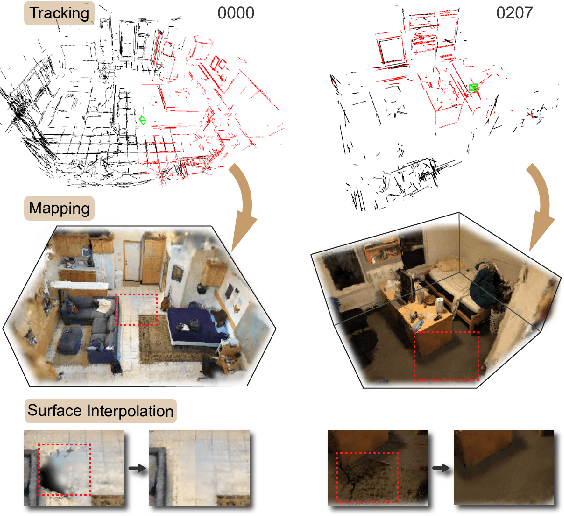


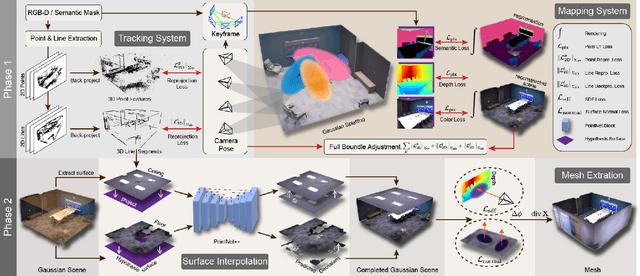
Gaussian SLAM systems have made significant advancements in improving the efficiency and fidelity of real-time reconstructions. However, these systems often encounter incomplete reconstructions in complex indoor environments, characterized by substantial holes due to unobserved geometry caused by obstacles or limited view angles. To address this challenge, we present Manhattan Gaussian SLAM (MG-SLAM), an RGB-D system that leverages the Manhattan World hypothesis to enhance geometric accuracy and completeness. By seamlessly integrating fused line segments derived from structured scenes, MG-SLAM ensures robust tracking in textureless indoor areas. Moreover, The extracted lines and planar surface assumption allow strategic interpolation of new Gaussians in regions of missing geometry, enabling efficient scene completion. Extensive experiments conducted on both synthetic and real-world scenes demonstrate that these advancements enable our method to achieve state-of-the-art performance, marking a substantial improvement in the capabilities of Gaussian SLAM systems.
Multi-Modal UAV Detection, Classification and Tracking Algorithm -- Technical Report for CVPR 2024 UG2 Challenge
May 26, 2024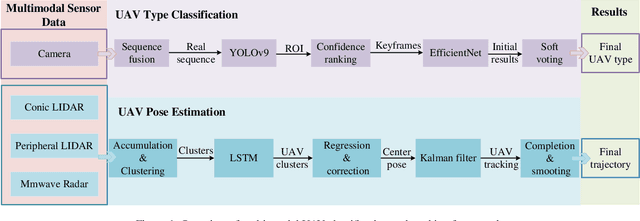
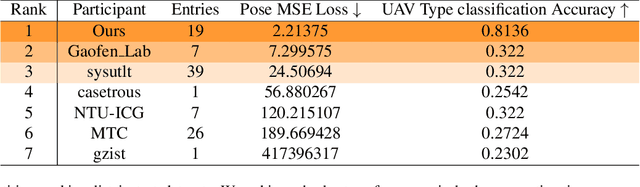
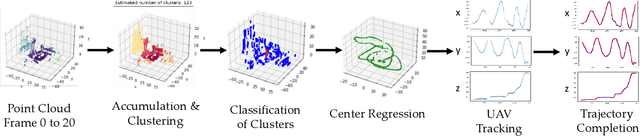
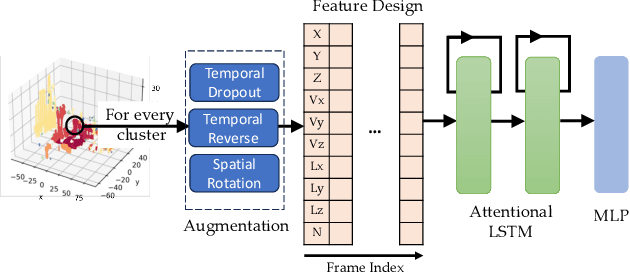
This technical report presents the 1st winning model for UG2+, a task in CVPR 2024 UAV Tracking and Pose-Estimation Challenge. This challenge faces difficulties in drone detection, UAV-type classification and 2D/3D trajectory estimation in extreme weather conditions with multi-modal sensor information, including stereo vision, various Lidars, Radars, and audio arrays. Leveraging this information, we propose a multi-modal UAV detection, classification, and 3D tracking method for accurate UAV classification and tracking. A novel classification pipeline which incorporates sequence fusion, region of interest (ROI) cropping, and keyframe selection is proposed. Our system integrates cutting-edge classification techniques and sophisticated post-processing steps to boost accuracy and robustness. The designed pose estimation pipeline incorporates three modules: dynamic points analysis, a multi-object tracker, and trajectory completion techniques. Extensive experiments have validated the effectiveness and precision of our approach. In addition, we also propose a novel dataset pre-processing method and conduct a comprehensive ablation study for our design. We finally achieved the best performance in the classification and tracking of the MMUAD dataset. The code and configuration of our method are available at https://github.com/dtc111111/Multi-Modal-UAV.
NGM-SLAM: Gaussian Splatting SLAM with Radiance Field Submap
May 09, 2024Gaussian Splatting has garnered widespread attention due to its exceptional performance. Consequently, SLAM systems based on Gaussian Splatting have emerged, leveraging its capabilities for rapid real-time rendering and high-fidelity mapping. However, current Gaussian Splatting SLAM systems usually struggle with large scene representation and lack effective loop closure adjustments and scene generalization capabilities. To address these issues, we introduce NGM-SLAM, the first GS-SLAM system that utilizes neural radiance field submaps for progressive scene expression, effectively integrating the strengths of neural radiance fields and 3D Gaussian Splatting. We have developed neural implicit submaps as supervision and achieve high-quality scene expression and online loop closure adjustments through Gaussian rendering of fused submaps. Our results on multiple real-world scenes and large-scale scene datasets demonstrate that our method can achieve accurate gap filling and high-quality scene expression, supporting both monocular, stereo, and RGB-D inputs, and achieving state-of-the-art scene reconstruction and tracking performance.