 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep reflective reasoning in interdependence constrained structured data extraction from clinical notes for digital health
Mar 20, 2026Extracting structured information from clinical notes requires navigating a dense web of interdependent variables where the value of one attribute logically constrains others. Existing Large Language Model (LLM)-based extraction pipelines often struggle to capture these dependencies, leading to clinically inconsistent outputs. We propose deep reflective reasoning, a large language model agent framework that iteratively self-critiques and revises structured outputs by checking consistency among variables, the input text, and retrieved domain knowledge, stopping when outputs converge. We extensively evaluate the proposed method in three diverse oncology applications: (1) On colorectal cancer synoptic reporting from gross descriptions (n=217), reflective reasoning improved average F1 across eight categorical synoptic variables from 0.828 to 0.911 and increased mean correct rate across four numeric variables from 0.806 to 0.895; (2) On Ewing sarcoma CD99 immunostaining pattern identification (n=200), the accuracy improved from 0.870 to 0.927; (3) On lung cancer tumor staging (n=100), tumor stage accuracy improved from 0.680 to 0.833 (pT: 0.842 -> 0.884; pN: 0.885 -> 0.948). The results demonstrate that deep reflective reasoning can systematically improve the reliability of LLM-based structured data extraction under interdependence constraints, enabling more consistent machine-operable clinical datasets and facilitating knowledge discovery with machine learning and data science towards digital health.
ArtLLM: Generating Articulated Assets via 3D LLM
Mar 01, 2026Creating interactive digital environments for gaming, robotics, and simulation relies on articulated 3D objects whose functionality emerges from their part geometry and kinematic structure. However, existing approaches remain fundamentally limited: optimization-based reconstruction methods require slow, per-object joint fitting and typically handle only simple, single-joint objects, while retrieval-based methods assemble parts from a fixed library, leading to repetitive geometry and poor generalization. To address these challenges, we introduce ArtLLM, a novel framework for generating high-quality articulated assets directly from complete 3D meshes. At its core is a 3D multimodal large language model trained on a large-scale articulation dataset curated from both existing articulation datasets and procedurally generated objects. Unlike prior work, ArtLLM autoregressively predicts a variable number of parts and joints, inferring their kinematic structure in a unified manner from the object's point cloud. This articulation-aware layout then conditions a 3D generative model to synthesize high-fidelity part geometries. Experiments on the PartNet-Mobility dataset show that ArtLLM significantly outperforms state-of-the-art methods in both part layout accuracy and joint prediction, while generalizing robustly to real-world objects. Finally, we demonstrate its utility in constructing digital twins, highlighting its potential for scalable robot learning.
HY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
LLGS: Unsupervised Gaussian Splatting for Image Enhancement and Reconstruction in Pure Dark Environment
Mar 24, 20253D Gaussian Splatting has shown remarkable capabilities in novel view rendering tasks and exhibits significant potential for multi-view optimization.However, the original 3D Gaussian Splatting lacks color representation for inputs in low-light environments. Simply using enhanced images as inputs would lead to issues with multi-view consistency, and current single-view enhancement systems rely on pre-trained data, lacking scene generalization. These problems limit the application of 3D Gaussian Splatting in low-light conditions in the field of robotics, including high-fidelity modeling and feature matching. To address these challenges, we propose an unsupervised multi-view stereoscopic system based on Gaussian Splatting, called Low-Light Gaussian Splatting (LLGS). This system aims to enhance images in low-light environments while reconstructing the scene. Our method introduces a decomposable Gaussian representation called M-Color, which separately characterizes color information for targeted enhancement. Furthermore, we propose an unsupervised optimization method with zero-knowledge priors, using direction-based enhancement to ensure multi-view consistency. Experiments conducted on real-world datasets demonstrate that our system outperforms state-of-the-art methods in both low-light enhancement and 3D Gaussian Splatting.
MaRI: Material Retrieval Integration across Domains
Mar 11, 2025Accurate material retrieval is critical for creating realistic 3D assets. Existing methods rely on datasets that capture shape-invariant and lighting-varied representations of materials, which are scarce and face challenges due to limited diversity and inadequate real-world generalization. Most current approaches adopt traditional image search techniques. They fall short in capturing the unique properties of material spaces, leading to suboptimal performance in retrieval tasks. Addressing these challenges, we introduce MaRI, a framework designed to bridge the feature space gap between synthetic and real-world materials. MaRI constructs a shared embedding space that harmonizes visual and material attributes through a contrastive learning strategy by jointly training an image and a material encoder, bringing similar materials and images closer while separating dissimilar pairs within the feature space. To support this, we construct a comprehensive dataset comprising high-quality synthetic materials rendered with controlled shape variations and diverse lighting conditions, along with real-world materials processed and standardized using material transfer techniques. Extensive experiments demonstrate the superior performance, accuracy, and generalization capabilities of MaRI across diverse and complex material retrieval tasks, outperforming existing methods.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Large language models enabled multiagent ensemble method for efficient EHR data labeling
Oct 21, 2024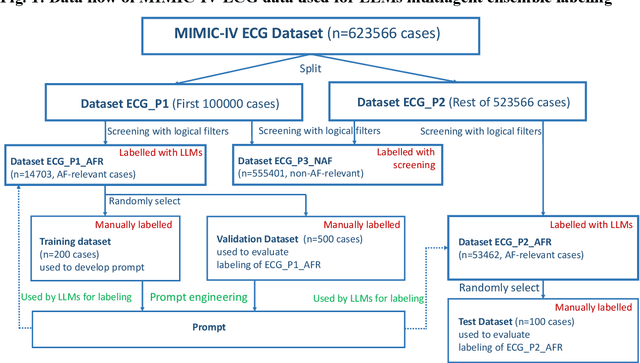
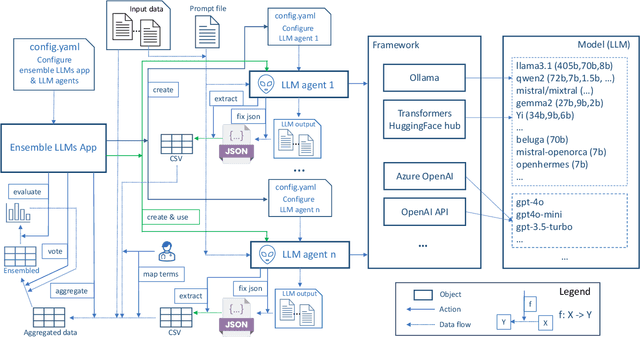
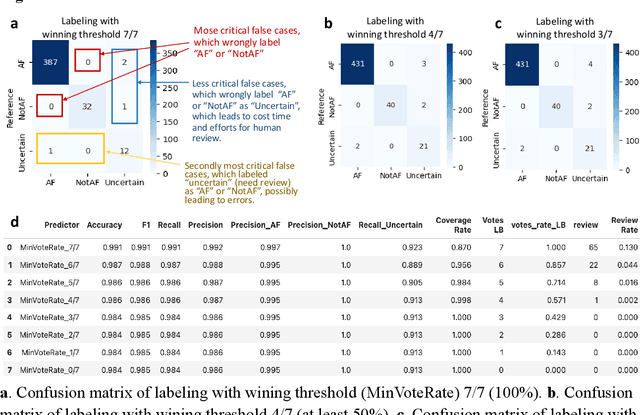
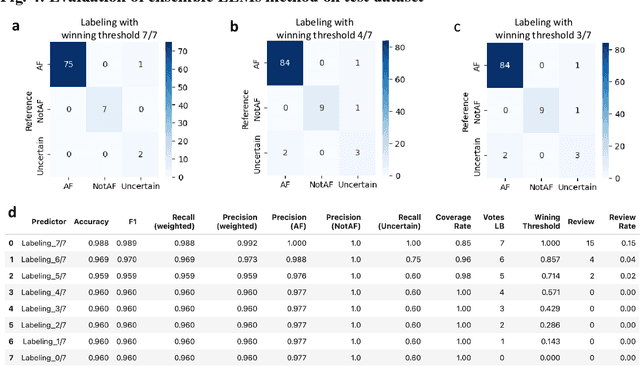
This study introduces a novel multiagent ensemble method powered by LLMs to address a key challenge in ML - data labeling, particularly in large-scale EHR datasets. Manual labeling of such datasets requires domain expertise and is labor-intensive, time-consuming, expensive, and error-prone. To overcome this bottleneck, we developed an ensemble LLMs method and demonstrated its effectiveness in two real-world tasks: (1) labeling a large-scale unlabeled ECG dataset in MIMIC-IV; (2) identifying social determinants of health (SDOH) from the clinical notes of EHR. Trading off benefits and cost, we selected a pool of diverse open source LLMs with satisfactory performance. We treat each LLM's prediction as a vote and apply a mechanism of majority voting with minimal winning threshold for ensemble. We implemented an ensemble LLMs application for EHR data labeling tasks. By using the ensemble LLMs and natural language processing, we labeled MIMIC-IV ECG dataset of 623,566 ECG reports with an estimated accuracy of 98.2%. We applied the ensemble LLMs method to identify SDOH from social history sections of 1,405 EHR clinical notes, also achieving competitive performance. Our experiments show that the ensemble LLMs can outperform individual LLM even the best commercial one, and the method reduces hallucination errors. From the research, we found that (1) the ensemble LLMs method significantly reduces the time and effort required for labeling large-scale EHR data, automating the process with high accuracy and quality; (2) the method generalizes well to other text data labeling tasks, as shown by its application to SDOH identification; (3) the ensemble of a group of diverse LLMs can outperform or match the performance of the best individual LLM; and (4) the ensemble method substantially reduces hallucination errors. This approach provides a scalable and efficient solution to data-labeling challenges.
NGP-RT: Fusing Multi-Level Hash Features with Lightweight Attention for Real-Time Novel View Synthesis
Jul 15, 2024



This paper presents NGP-RT, a novel approach for enhancing the rendering speed of Instant-NGP to achieve real-time novel view synthesis. As a classic NeRF-based method, Instant-NGP stores implicit features in multi-level grids or hash tables and applies a shallow MLP to convert the implicit features into explicit colors and densities. Although it achieves fast training speed, there is still a lot of room for improvement in its rendering speed due to the per-point MLP executions for implicit multi-level feature aggregation, especially for real-time applications. To address this challenge, our proposed NGP-RT explicitly stores colors and densities as hash features, and leverages a lightweight attention mechanism to disambiguate the hash collisions instead of using computationally intensive MLP. At the rendering stage, NGP-RT incorporates a pre-computed occupancy distance grid into the ray marching strategy to inform the distance to the nearest occupied voxel, thereby reducing the number of marching points and global memory access. Experimental results show that on the challenging Mip-NeRF360 dataset, NGP-RT achieves better rendering quality than previous NeRF-based methods, achieving 108 fps at 1080p resolution on a single Nvidia RTX 3090 GPU. Our approach is promising for NeRF-based real-time applications that require efficient and high-quality rendering.