 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointer-CAD: Unifying B-Rep and Command Sequences via Pointer-based Edges & Faces Selection
Mar 04, 2026Constructing computer-aided design (CAD) models is labor-intensive but essential for engineering and manufacturing. Recent advances in Large Language Models (LLMs) have inspired the LLM-based CAD generation by representing CAD as command sequences. But these methods struggle in practical scenarios because command sequence representation does not support entity selection (e.g. faces or edges), limiting its ability to support complex editing operations such as chamfer or fillet. Further, the discretization of a continuous variable during sketch and extrude operations may result in topological errors. To address these limitations, we present Pointer-CAD, a novel LLM-based CAD generation framework that leverages a pointer-based command sequence representation to explicitly incorporate the geometric information of B-rep models into sequential modeling. In particular, Pointer-CAD decomposes CAD model generation into steps, conditioning the generation of each subsequent step on both the textual description and the B-rep generated from previous steps. Whenever an operation requires the selection of a specific geometric entity, the LLM predicts a Pointer that selects the most feature-consistent candidate from the available set. Such a selection operation also reduces the quantization error in the command sequence-based representation. To support the training of Pointer-CAD, we develop a data annotation pipeline that produces expert-level natural language descriptions and apply it to build a dataset of approximately 575K CAD models. Extensive experimental results demonstrate that Pointer-CAD effectively supports the generation of complex geometric structures and reduces segmentation error to an extremely low level, achieving a significant improvement over prior command sequence methods, thereby significantly mitigating the topological inaccuracies introduced by quantization error.
HY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
The Two-Stage Decision-Sampling Hypothesis: Understanding the Emergence of Self-Reflection in RL-Trained LLMs
Jan 04, 2026Self-reflection capabilities emerge in Large Language Models after RL post-training, with multi-turn RL achieving substantial gains over SFT counterparts. Yet the mechanism of how a unified optimization objective gives rise to functionally distinct capabilities of generating solutions and evaluating when to revise them remains opaque. To address this question, we introduce the Gradient Attribution Property to characterize how reward gradients distribute across policy components, formalized through the Two-Stage Decision-Sampling (DS) Hypothesis, which decomposes the policy into sampling ($π_{sample}$) for generation and decision ($π_{d}$) for verification. We prove that surrogate rewards exhibit Balanced Gradient Attribution, while SFT and KL penalties exhibit Unbalanced Gradient Attribution, with length-weighting creating asymmetric regularization that constrains $π_{sample}$ while leaving $π_{d}$ under-optimized, providing an theoretical explanation of why RL succeeds where SFT fails. We also empirically validate our theoretical predictions on arithmetic reasoning demonstrates that RL's superior generalization stems primarily from improved decision-making ($π_{d}$) rather than sampling capabilities, providing a first-principles mechanistic explanation for self-correction in thinking models.
CUPID: Pose-Grounded Generative 3D Reconstruction from a Single Image
Oct 23, 2025This work proposes a new generation-based 3D reconstruction method, named Cupid, that accurately infers the camera pose, 3D shape, and texture of an object from a single 2D image. Cupid casts 3D reconstruction as a conditional sampling process from a learned distribution of 3D objects, and it jointly generates voxels and pixel-voxel correspondences, enabling robust pose and shape estimation under a unified generative framework. By representing both input camera poses and 3D shape as a distribution in a shared 3D latent space, Cupid adopts a two-stage flow matching pipeline: (1) a coarse stage that produces initial 3D geometry with associated 2D projections for pose recovery; and (2) a refinement stage that integrates pose-aligned image features to enhance structural fidelity and appearance details. Extensive experiments demonstrate Cupid outperforms leading 3D reconstruction methods with an over 3 dB PSNR gain and an over 10% Chamfer Distance reduction, while matching monocular estimators on pose accuracy and delivering superior visual fidelity over baseline 3D generative models. For an immersive view of the 3D results generated by Cupid, please visit cupid3d.github.io.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
X-Part: high fidelity and structure coherent shape decomposition
Sep 10, 2025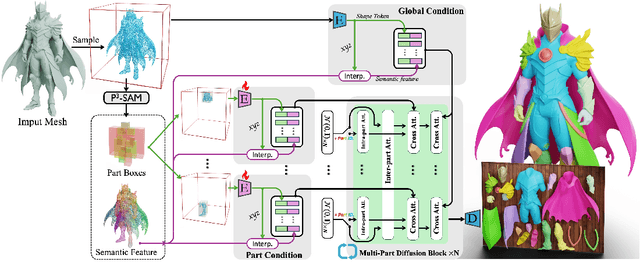
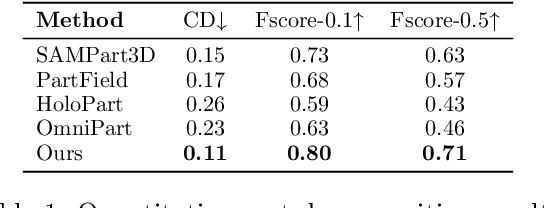

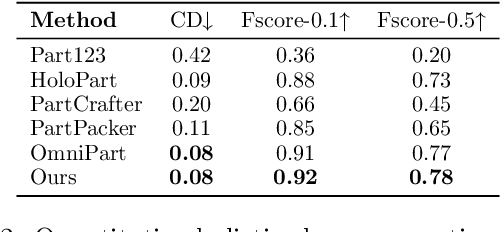
Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
Mesh Silksong: Auto-Regressive Mesh Generation as Weaving Silk
Jul 03, 2025We introduce Mesh Silksong, a compact and efficient mesh representation tailored to generate the polygon mesh in an auto-regressive manner akin to silk weaving. Existing mesh tokenization methods always produce token sequences with repeated vertex tokens, wasting the network capability. Therefore, our approach tokenizes mesh vertices by accessing each mesh vertice only once, reduces the token sequence's redundancy by 50\%, and achieves a state-of-the-art compression rate of approximately 22\%. Furthermore, Mesh Silksong produces polygon meshes with superior geometric properties, including manifold topology, watertight detection, and consistent face normals, which are critical for practical applications. Experimental results demonstrate the effectiveness of our approach, showcasing not only intricate mesh generation but also significantly improved geometric integrity.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
FreeMesh: Boosting Mesh Generation with Coordinates Merging
May 19, 2025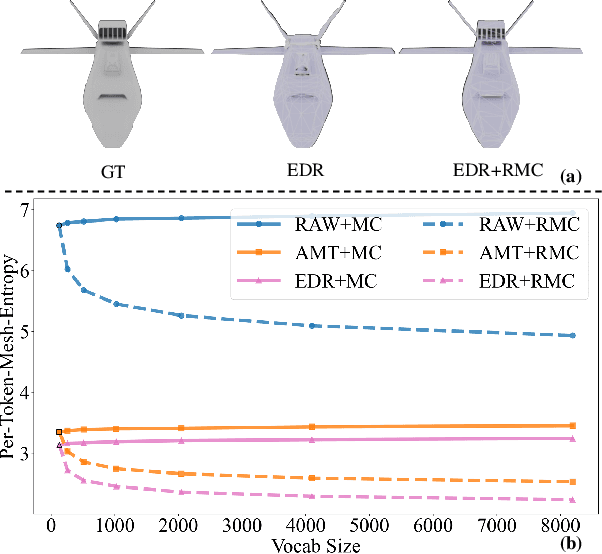
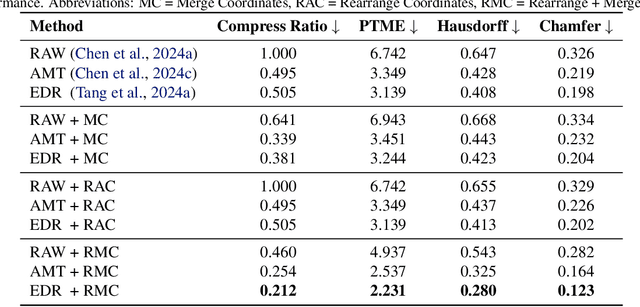
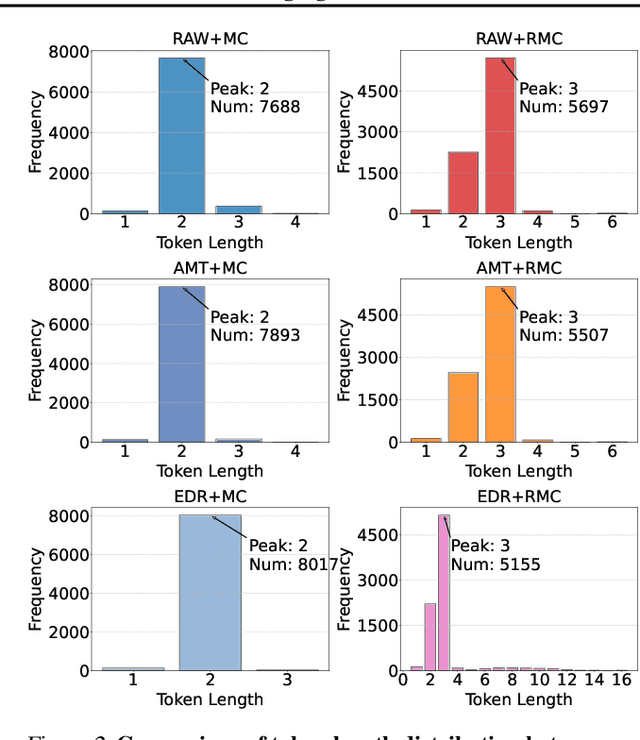
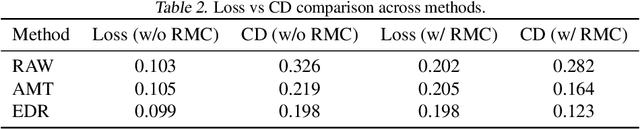
The next-coordinate prediction paradigm has emerged as the de facto standard in current auto-regressive mesh generation methods. Despite their effectiveness, there is no efficient measurement for the various tokenizers that serialize meshes into sequences. In this paper, we introduce a new metric Per-Token-Mesh-Entropy (PTME) to evaluate the existing mesh tokenizers theoretically without any training. Building upon PTME, we propose a plug-and-play tokenization technique called coordinate merging. It further improves the compression ratios of existing tokenizers by rearranging and merging the most frequent patterns of coordinates. Through experiments on various tokenization methods like MeshXL, MeshAnything V2, and Edgerunner, we further validate the performance of our method. We hope that the proposed PTME and coordinate merging can enhance the existing mesh tokenizers and guide the further development of native mesh generation.
RomanTex: Decoupling 3D-aware Rotary Positional Embedded Multi-Attention Network for Texture Synthesis
Mar 24, 2025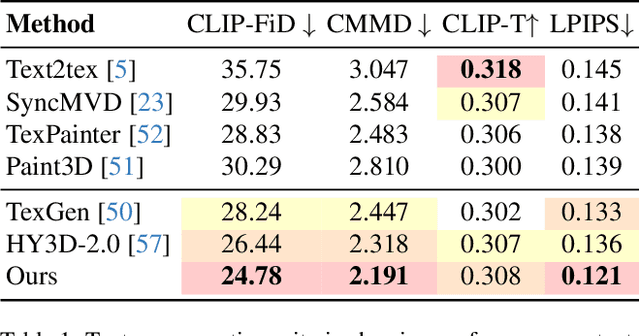

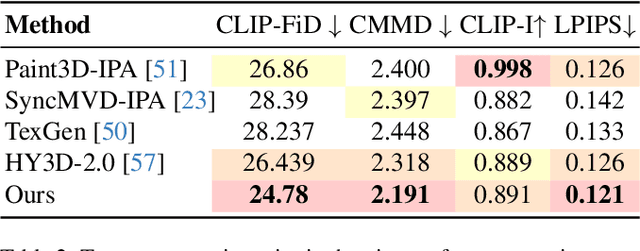

Painting textures for existing geometries is a critical yet labor-intensive process in 3D asset generation. Recent advancements in text-to-image (T2I) models have led to significant progress in texture generation. Most existing research approaches this task by first generating images in 2D spaces using image diffusion models, followed by a texture baking process to achieve UV texture. However, these methods often struggle to produce high-quality textures due to inconsistencies among the generated multi-view images, resulting in seams and ghosting artifacts. In contrast, 3D-based texture synthesis methods aim to address these inconsistencies, but they often neglect 2D diffusion model priors, making them challenging to apply to real-world objects To overcome these limitations, we propose RomanTex, a multiview-based texture generation framework that integrates a multi-attention network with an underlying 3D representation, facilitated by our novel 3D-aware Rotary Positional Embedding. Additionally, we incorporate a decoupling characteristic in the multi-attention block to enhance the model's robustness in image-to-texture task, enabling semantically-correct back-view synthesis. Furthermore, we introduce a geometry-related Classifier-Free Guidance (CFG) mechanism to further improve the alignment with both geometries and images. Quantitative and qualitative evaluations, along with comprehensive user studies, demonstrate that our method achieves state-of-the-art results in texture quality and consistency.