 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating the Seemingly Unrelated: Principled Understanding of Generalization for Generative Models in Arithmetic Reasoning Tasks
Paper and Code

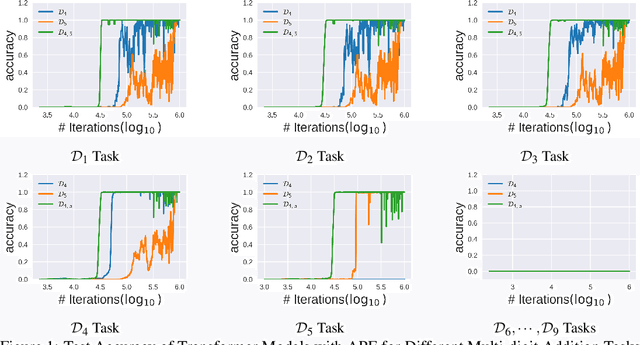
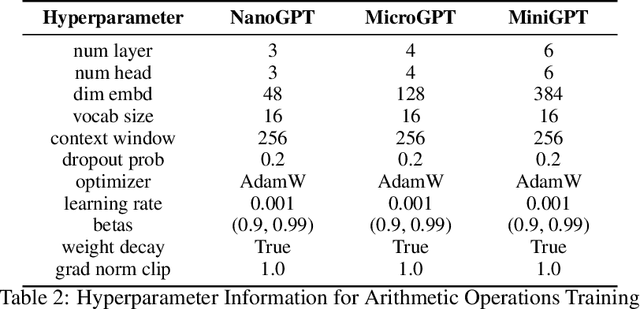
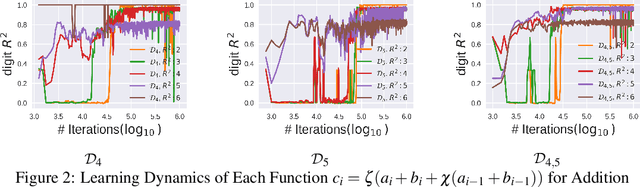
Large language models (LLMs) have demonstrated impressive versatility across numerous tasks, yet their generalization capabilities remain poorly understood. To investigate these behaviors, arithmetic tasks serve as important venues. In previous studies, seemingly unrelated mysteries still exist -- (1) models with appropriate positional embeddings can correctly perform longer unseen arithmetic operations such as addition, but their effectiveness varies in more complex tasks like multiplication; (2) models perform well for longer unseen cases in modular addition under specific moduli (e.g., modulo 100) but struggle under very close moduli (e.g., modulo 101), regardless of the positional encoding used. We believe previous studies have been treating the symptoms rather than addressing the root cause -- they have paid excessive attention to improving model components, while overlooking the differences in task properties that may be the real drivers. This is confirmed by our unified theoretical framework for different arithmetic scenarios. For example, unlike multiplication, the digital addition task has the property of translation invariance which naturally aligns with the relative positional encoding, and this combination leads to successful generalization of addition to unseen longer domains. The discrepancy in operations modulo 100 and 101 arises from the base. Modulo 100, unlike 101, is compatible with the decimal system (base 10), such that unseen information in digits beyond the units digit and the tens digit is actually not needed for the task. Extensive experiments with GPT-like models validate our theoretical predictions. These findings deepen our understanding of the generalization mechanisms, and facilitate more data-efficient model training and objective-oriented AI alignment.