 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMHCL: Multi-Modal Hypergraph Contrastive Learning for Recommendation
Apr 23, 2025The burgeoning presence of multimodal content-sharing platforms propels the development of personalized recommender systems. Previous works usually suffer from data sparsity and cold-start problems, and may fail to adequately explore semantic user-product associations from multimodal data. To address these issues, we propose a novel Multi-Modal Hypergraph Contrastive Learning (MMHCL) framework for user recommendation. For a comprehensive information exploration from user-product relations, we construct two hypergraphs, i.e. a user-to-user (u2u) hypergraph and an item-to-item (i2i) hypergraph, to mine shared preferences among users and intricate multimodal semantic resemblance among items, respectively. This process yields denser second-order semantics that are fused with first-order user-item interaction as complementary to alleviate the data sparsity issue. Then, we design a contrastive feature enhancement paradigm by applying synergistic contrastive learning. By maximizing/minimizing the mutual information between second-order (e.g. shared preference pattern for users) and first-order (information of selected items for users) embeddings of the same/different users and items, the feature distinguishability can be effectively enhanced. Compared with using sparse primary user-item interaction only, our MMHCL obtains denser second-order hypergraphs and excavates more abundant shared attributes to explore the user-product associations, which to a certain extent alleviates the problems of data sparsity and cold-start. Extensive experiments have comprehensively demonstrated the effectiveness of our method. Our code is publicly available at: https://github.com/Xu107/MMHCL.
Multi-Modal Hypergraph Enhanced LLM Learning for Recommendation
Apr 13, 2025



The burgeoning presence of Large Language Models (LLM) is propelling the development of personalized recommender systems. Most existing LLM-based methods fail to sufficiently explore the multi-view graph structure correlations inherent in recommendation scenarios. To this end, we propose a novel framework, Hypergraph Enhanced LLM Learning for multimodal Recommendation (HeLLM), designed to equip LLMs with the capability to capture intricate higher-order semantic correlations by fusing graph-level contextual signals with sequence-level behavioral patterns. In the recommender pre-training phase, we design a user hypergraph to uncover shared interest preferences among users and an item hypergraph to capture correlations within multimodal similarities among items. The hypergraph convolution and synergistic contrastive learning mechanism are introduced to enhance the distinguishability of learned representations. In the LLM fine-tuning phase, we inject the learned graph-structured embeddings directly into the LLM's architecture and integrate sequential features capturing each user's chronological behavior. This process enables hypergraphs to leverage graph-structured information as global context, enhancing the LLM's ability to perceive complex relational patterns and integrate multimodal information, while also modeling local temporal dynamics. Extensive experiments demonstrate the superiority of our proposed method over state-of-the-art baselines, confirming the advantages of fusing hypergraph-based context with sequential user behavior in LLMs for recommendation.
Unleashing Vecset Diffusion Model for Fast Shape Generation
Mar 20, 20253D shape generation has greatly flourished through the development of so-called "native" 3D diffusion, particularly through the Vecset Diffusion Model (VDM). While recent advancements have shown promising results in generating high-resolution 3D shapes, VDM still struggles with high-speed generation. Challenges exist because of difficulties not only in accelerating diffusion sampling but also VAE decoding in VDM, areas under-explored in previous works. To address these challenges, we present FlashVDM, a systematic framework for accelerating both VAE and DiT in VDM. For DiT, FlashVDM enables flexible diffusion sampling with as few as 5 inference steps and comparable quality, which is made possible by stabilizing consistency distillation with our newly introduced Progressive Flow Distillation. For VAE, we introduce a lightning vecset decoder equipped with Adaptive KV Selection, Hierarchical Volume Decoding, and Efficient Network Design. By exploiting the locality of the vecset and the sparsity of shape surface in the volume, our decoder drastically lowers FLOPs, minimizing the overall decoding overhead. We apply FlashVDM to Hunyuan3D-2 to obtain Hunyuan3D-2 Turbo. Through systematic evaluation, we show that our model significantly outperforms existing fast 3D generation methods, achieving comparable performance to the state-of-the-art while reducing inference time by over 45x for reconstruction and 32x for generation. Code and models are available at https://github.com/Tencent/FlashVDM.
Distribution Prototype Diffusion Learning for Open-set Supervised Anomaly Detection
Feb 28, 2025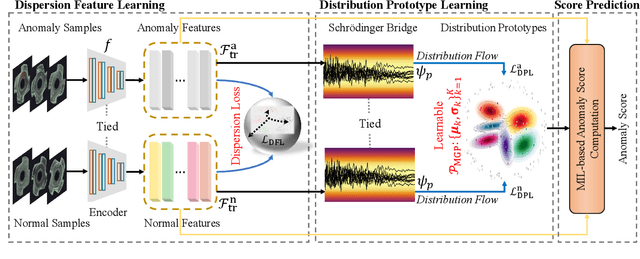
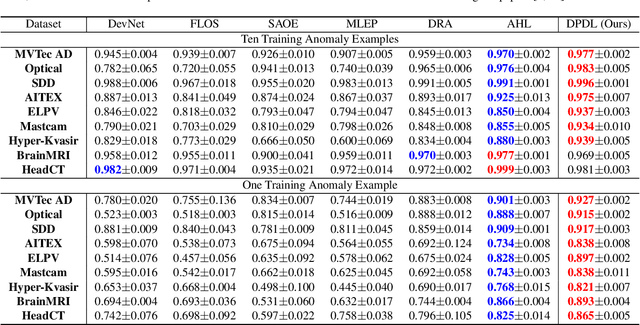
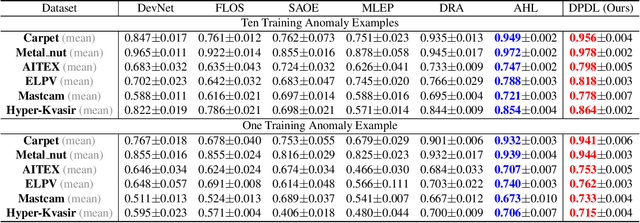
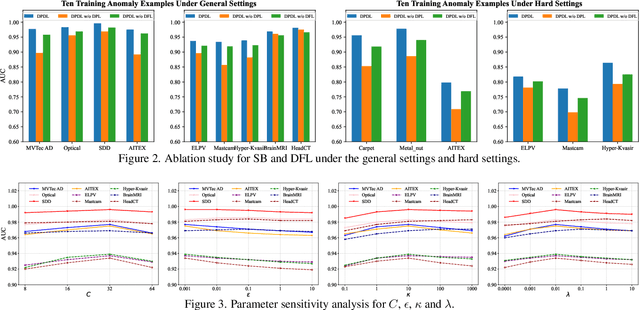
In Open-set Supervised Anomaly Detection (OSAD), the existing methods typically generate pseudo anomalies to compensate for the scarcity of observed anomaly samples, while overlooking critical priors of normal samples, leading to less effective discriminative boundaries. To address this issue, we propose a Distribution Prototype Diffusion Learning (DPDL) method aimed at enclosing normal samples within a compact and discriminative distribution space. Specifically, we construct multiple learnable Gaussian prototypes to create a latent representation space for abundant and diverse normal samples and learn a Schr\"odinger bridge to facilitate a diffusive transition toward these prototypes for normal samples while steering anomaly samples away. Moreover, to enhance inter-sample separation, we design a dispersion feature learning way in hyperspherical space, which benefits the identification of out-of-distribution anomalies. Experimental results demonstrate the effectiveness and superiority of our proposed DPDL, achieving state-of-the-art performance on 9 public datasets.
MMM-RS: A Multi-modal, Multi-GSD, Multi-scene Remote Sensing Dataset and Benchmark for Text-to-Image Generation
Oct 26, 2024



Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS images across various modalities, scenes, weather conditions, and GSD. The dataset is available at https://github.com/ljl5261/MMM-RS.
MPDS: A Movie Posters Dataset for Image Generation with Diffusion Model
Oct 22, 2024



Movie posters are vital for captivating audiences, conveying themes, and driving market competition in the film industry. While traditional designs are laborious, intelligent generation technology offers efficiency gains and design enhancements. Despite exciting progress in image generation, current models often fall short in producing satisfactory poster results. The primary issue lies in the absence of specialized poster datasets for targeted model training. In this work, we propose a Movie Posters DataSet (MPDS), tailored for text-to-image generation models to revolutionize poster production. As dedicated to posters, MPDS stands out as the first image-text pair dataset to our knowledge, composing of 373k+ image-text pairs and 8k+ actor images (covering 4k+ actors). Detailed poster descriptions, such as movie titles, genres, casts, and synopses, are meticulously organized and standardized based on public movie synopsis, also named movie-synopsis prompt. To bolster poster descriptions as well as reduce differences from movie synopsis, further, we leverage a large-scale vision-language model to automatically produce vision-perceptive prompts for each poster, then perform manual rectification and integration with movie-synopsis prompt. In addition, we introduce a prompt of poster captions to exhibit text elements in posters like actor names and movie titles. For movie poster generation, we develop a multi-condition diffusion framework that takes poster prompt, poster caption, and actor image (for personalization) as inputs, yielding excellent results through the learning of a diffusion model. Experiments demonstrate the valuable role of our proposed MPDS dataset in advancing personalized movie poster generation. MPDS is available at https://anonymous.4open.science/r/MPDS-373k-BD3B.
Contrastive Multi-Level Graph Neural Networks for Session-based Recommendation
Nov 06, 2023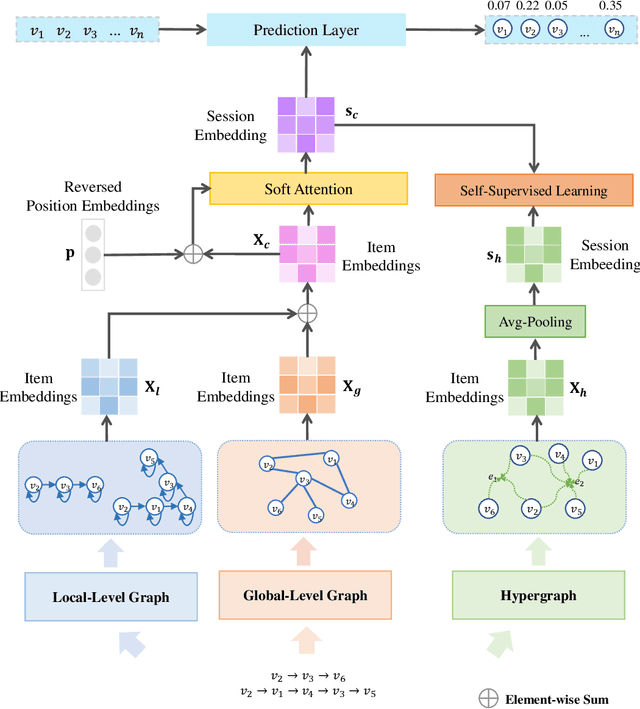
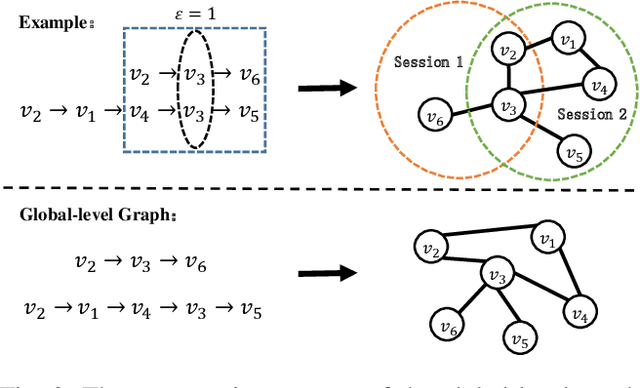
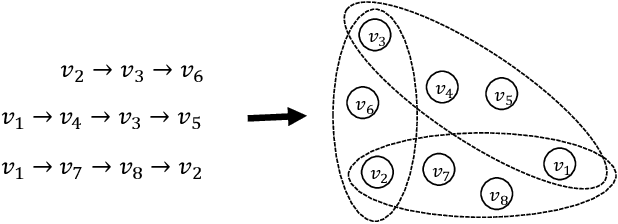

Session-based recommendation (SBR) aims to predict the next item at a certain time point based on anonymous user behavior sequences. Existing methods typically model session representation based on simple item transition information. However, since session-based data consists of limited users' short-term interactions, modeling session representation by capturing fixed item transition information from a single dimension suffers from data sparsity. In this paper, we propose a novel contrastive multi-level graph neural networks (CM-GNN) to better exploit complex and high-order item transition information. Specifically, CM-GNN applies local-level graph convolutional network (L-GCN) and global-level network (G-GCN) on the current session and all the sessions respectively, to effectively capture pairwise relations over all the sessions by aggregation strategy. Meanwhile, CM-GNN applies hyper-level graph convolutional network (H-GCN) to capture high-order information among all the item transitions. CM-GNN further introduces an attention-based fusion module to learn pairwise relation-based session representation by fusing the item representations generated by L-GCN and G-GCN. CM-GNN averages the item representations obtained by H-GCN to obtain high-order relation-based session representation. Moreover, to convert the high-order item transition information into the pairwise relation-based session representation, CM-GNN maximizes the mutual information between the representations derived from the fusion module and the average pool layer by contrastive learning paradigm. We conduct extensive experiments on multiple widely used benchmark datasets to validate the efficacy of the proposed method. The encouraging results demonstrate that our proposed method outperforms the state-of-the-art SBR techniques.