 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithfulFaces: Pose-Faithful Facial Identity Preservation for Text-to-Video Generation
May 06, 2026Identity-preserving text-to-video generation (IPT2V) empowers users to produce diverse and imaginative videos with consistent human facial identity. Despite recent progress, existing methods often suffer from significant identity distortion under large facial pose variations or facial occlusions. In this paper, we propose \textit{FaithfulFaces}, a pose-faithful facial identity preservation learning framework to improve IPT2V in complex dynamic scenes. The key of FaithfulFaces is a pose-shared identity aligner that refines and aligns facial poses across distinct views via a pose-shared dictionary and a pose variation-identity invariance constraint. By mapping single-view inputs into a global facial pose representation with explicit Euler angle embeddings, FaithfulFaces provides a pose-faithful facial prior that guides generative foundations toward robust identity-preserving generation. In particular, we develop a specialized pipeline to curate a high-quality video dataset featuring substantial facial pose diversity. Extensive experiments demonstrate that FaithfulFaces achieves state-of-the-art performance, maintaining superior identity consistency and structural clarity even as pose changes and occlusions occur.
Mixture Prototype Flow Matching for Open-Set Supervised Anomaly Detection
May 04, 2026Open-set supervised anomaly detection (OSAD) aims to identify unseen anomalies using limited anomalous supervision. However, existing prototype-based methods typically model normal data via a unimodal Gaussian prior, failing to capture inherent multi-modality and resulting in blurred decision boundaries. To address this, we propose Mixture Prototype Flow Matching (MPFM), a framework that learns a continuous transformation from normal feature distributions to a structured Gaussian mixture prototype space. Departing from traditional flow-based approaches that rely on a single velocity vector, MPFM explicitly models the velocity field as a Gaussian mixture prior where each component corresponds to a distinct normal class. This design facilitates mode-aware and semantically coherent distribution transport. Furthermore, we introduce a Mutual Information Maximization Regularizer (MIMR) to prevent prototype collapse and maximize normal-anomaly separability. Extensive experiments demonstrate that MPFM achieves state-of-the-art performance across diverse benchmarks under both single- and multi-anomaly settings.
Anomaly-Preference Image Generation
May 04, 2026Synthesizing realistic and diverse anomalous samples from limited data is vital for robust model generalization. However, existing methods struggle to reconcile fidelity and diversity, often hampered by distribution misalignment and overfitting, respectively.To mitigate this, we introduce Anomaly Preference Optimization,a novel paradigm that reformulates anomaly generation as a preference learning problem.Central to our approach is an implicit preference alignment mechanism that leverages real anomalies as positive references, deriving optimization signals directly from denoising trajectory deviations without requiring costly human annotation. Furthermore, we propose a Time-Aware Capacity Allocation module that dynamically distributes model capacity along the diffusion timeline,prioritizing structural diversity during highnoise phases while enhancing fine-grained fidelity in low-noise stages. During inference, a hierarchical sampling strategy modulates the coherencealignment trade-off, enabling precise control over generation. Extensive experiments demonstrate that significantly outperforms existing baselines,achieving state-of-the-art performance in both realism and diversity.
Decoupled Hierarchical Distillation for Multimodal Emotion Recognition
Feb 04, 2026Human multimodal emotion recognition (MER) seeks to infer human emotions by integrating information from language, visual, and acoustic modalities. Although existing MER approaches have achieved promising results, they still struggle with inherent multimodal heterogeneities and varying contributions from different modalities. To address these challenges, we propose a novel framework, Decoupled Hierarchical Multimodal Distillation (DHMD). DHMD decouples each modality's features into modality-irrelevant (homogeneous) and modality-exclusive (heterogeneous) components using a self-regression mechanism. The framework employs a two-stage knowledge distillation (KD) strategy: (1) coarse-grained KD via a Graph Distillation Unit (GD-Unit) in each decoupled feature space, where a dynamic graph facilitates adaptive distillation among modalities, and (2) fine-grained KD through a cross-modal dictionary matching mechanism, which aligns semantic granularities across modalities to produce more discriminative MER representations. This hierarchical distillation approach enables flexible knowledge transfer and effectively improves cross-modal feature alignment. Experimental results demonstrate that DHMD consistently outperforms state-of-the-art MER methods, achieving 1.3\%/2.4\% (ACC$_7$), 1.3\%/1.9\% (ACC$_2$) and 1.9\%/1.8\% (F1) relative improvement on CMU-MOSI/CMU-MOSEI dataset, respectively. Meanwhile, visualization results reveal that both the graph edges and dictionary activations in DHMD exhibit meaningful distribution patterns across modality-irrelevant/-exclusive feature spaces.
* arXiv admin note: text overlap with arXiv:2303.13802
Multi-Modal Hypergraph Enhanced LLM Learning for Recommendation
Apr 13, 2025



The burgeoning presence of Large Language Models (LLM) is propelling the development of personalized recommender systems. Most existing LLM-based methods fail to sufficiently explore the multi-view graph structure correlations inherent in recommendation scenarios. To this end, we propose a novel framework, Hypergraph Enhanced LLM Learning for multimodal Recommendation (HeLLM), designed to equip LLMs with the capability to capture intricate higher-order semantic correlations by fusing graph-level contextual signals with sequence-level behavioral patterns. In the recommender pre-training phase, we design a user hypergraph to uncover shared interest preferences among users and an item hypergraph to capture correlations within multimodal similarities among items. The hypergraph convolution and synergistic contrastive learning mechanism are introduced to enhance the distinguishability of learned representations. In the LLM fine-tuning phase, we inject the learned graph-structured embeddings directly into the LLM's architecture and integrate sequential features capturing each user's chronological behavior. This process enables hypergraphs to leverage graph-structured information as global context, enhancing the LLM's ability to perceive complex relational patterns and integrate multimodal information, while also modeling local temporal dynamics. Extensive experiments demonstrate the superiority of our proposed method over state-of-the-art baselines, confirming the advantages of fusing hypergraph-based context with sequential user behavior in LLMs for recommendation.
Distribution Prototype Diffusion Learning for Open-set Supervised Anomaly Detection
Feb 28, 2025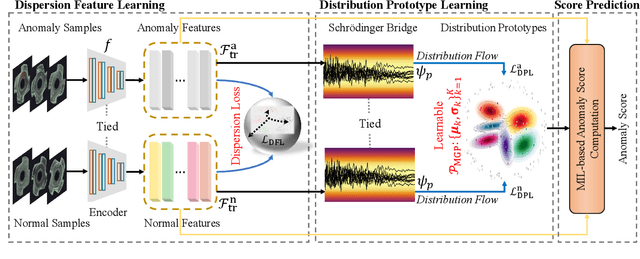
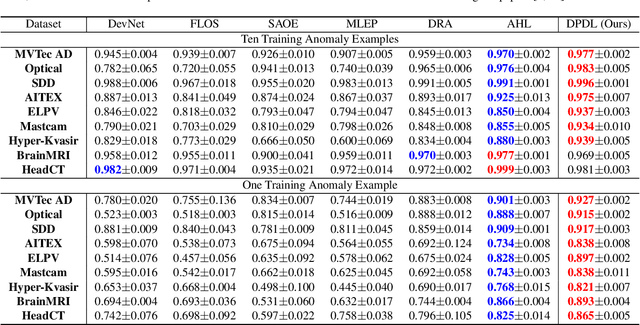
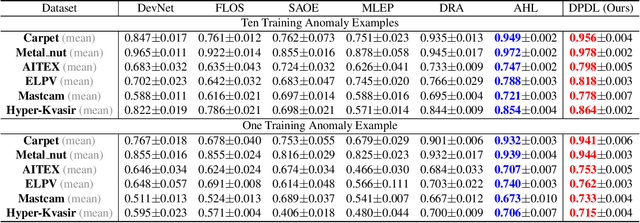
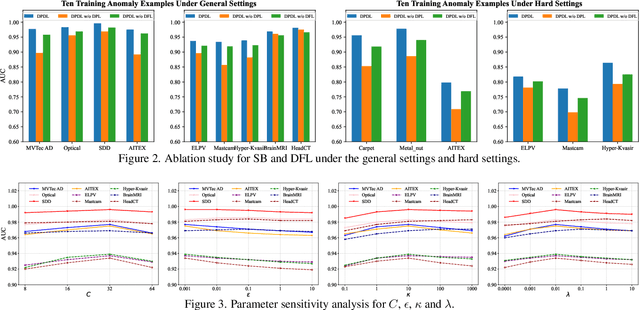
In Open-set Supervised Anomaly Detection (OSAD), the existing methods typically generate pseudo anomalies to compensate for the scarcity of observed anomaly samples, while overlooking critical priors of normal samples, leading to less effective discriminative boundaries. To address this issue, we propose a Distribution Prototype Diffusion Learning (DPDL) method aimed at enclosing normal samples within a compact and discriminative distribution space. Specifically, we construct multiple learnable Gaussian prototypes to create a latent representation space for abundant and diverse normal samples and learn a Schr\"odinger bridge to facilitate a diffusive transition toward these prototypes for normal samples while steering anomaly samples away. Moreover, to enhance inter-sample separation, we design a dispersion feature learning way in hyperspherical space, which benefits the identification of out-of-distribution anomalies. Experimental results demonstrate the effectiveness and superiority of our proposed DPDL, achieving state-of-the-art performance on 9 public datasets.
Re-Attentional Controllable Video Diffusion Editing
Dec 16, 2024Editing videos with textual guidance has garnered popularity due to its streamlined process which mandates users to solely edit the text prompt corresponding to the source video. Recent studies have explored and exploited large-scale text-to-image diffusion models for text-guided video editing, resulting in remarkable video editing capabilities. However, they may still suffer from some limitations such as mislocated objects, incorrect number of objects. Therefore, the controllability of video editing remains a formidable challenge. In this paper, we aim to challenge the above limitations by proposing a Re-Attentional Controllable Video Diffusion Editing (ReAtCo) method. Specially, to align the spatial placement of the target objects with the edited text prompt in a training-free manner, we propose a Re-Attentional Diffusion (RAD) to refocus the cross-attention activation responses between the edited text prompt and the target video during the denoising stage, resulting in a spatially location-aligned and semantically high-fidelity manipulated video. In particular, to faithfully preserve the invariant region content with less border artifacts, we propose an Invariant Region-guided Joint Sampling (IRJS) strategy to mitigate the intrinsic sampling errors w.r.t the invariant regions at each denoising timestep and constrain the generated content to be harmonized with the invariant region content. Experimental results verify that ReAtCo consistently improves the controllability of video diffusion editing and achieves superior video editing performance.
MMM-RS: A Multi-modal, Multi-GSD, Multi-scene Remote Sensing Dataset and Benchmark for Text-to-Image Generation
Oct 26, 2024



Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS images across various modalities, scenes, weather conditions, and GSD. The dataset is available at https://github.com/ljl5261/MMM-RS.
Edit Temporal-Consistent Videos with Image Diffusion Model
Aug 17, 2023



Large-scale text-to-image (T2I) diffusion models have been extended for text-guided video editing, yielding impressive zero-shot video editing performance. Nonetheless, the generated videos usually show spatial irregularities and temporal inconsistencies as the temporal characteristics of videos have not been faithfully modeled. In this paper, we propose an elegant yet effective Temporal-Consistent Video Editing (TCVE) method, to mitigate the temporal inconsistency challenge for robust text-guided video editing. In addition to the utilization of a pretrained 2D Unet for spatial content manipulation, we establish a dedicated temporal Unet architecture to faithfully capture the temporal coherence of the input video sequences. Furthermore, to establish coherence and interrelation between the spatial-focused and temporal-focused components, a cohesive joint spatial-temporal modeling unit is formulated. This unit effectively interconnects the temporal Unet with the pretrained 2D Unet, thereby enhancing the temporal consistency of the generated video output while simultaneously preserving the capacity for video content manipulation. Quantitative experimental results and visualization results demonstrate that TCVE achieves state-of-the-art performance in both video temporal consistency and video editing capability, surpassing existing benchmarks in the field.
Decoupled Multimodal Distilling for Emotion Recognition
Mar 24, 2023



Human multimodal emotion recognition (MER) aims to perceive human emotions via language, visual and acoustic modalities. Despite the impressive performance of previous MER approaches, the inherent multimodal heterogeneities still haunt and the contribution of different modalities varies significantly. In this work, we mitigate this issue by proposing a decoupled multimodal distillation (DMD) approach that facilitates flexible and adaptive crossmodal knowledge distillation, aiming to enhance the discriminative features of each modality. Specially, the representation of each modality is decoupled into two parts, i.e., modality-irrelevant/-exclusive spaces, in a self-regression manner. DMD utilizes a graph distillation unit (GD-Unit) for each decoupled part so that each GD can be performed in a more specialized and effective manner. A GD-Unit consists of a dynamic graph where each vertice represents a modality and each edge indicates a dynamic knowledge distillation. Such GD paradigm provides a flexible knowledge transfer manner where the distillation weights can be automatically learned, thus enabling diverse crossmodal knowledge transfer patterns. Experimental results show DMD consistently obtains superior performance than state-of-the-art MER methods. Visualization results show the graph edges in DMD exhibit meaningful distributional patterns w.r.t. the modality-irrelevant/-exclusive feature spaces. Codes are released at \url{https://github.com/mdswyz/DMD}.