 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig-model Driven Few-shot Continual Learning
Sep 02, 2023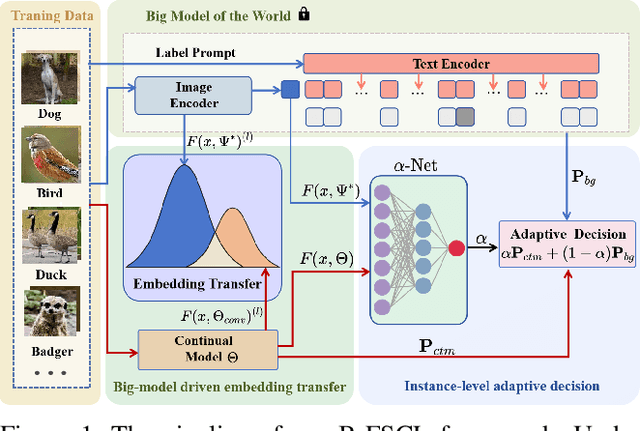
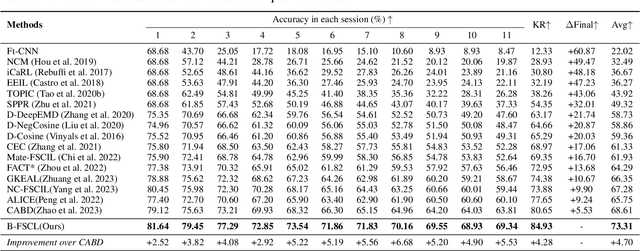
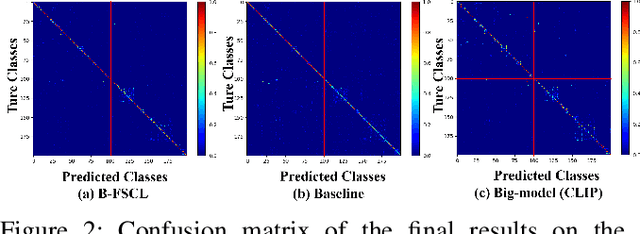
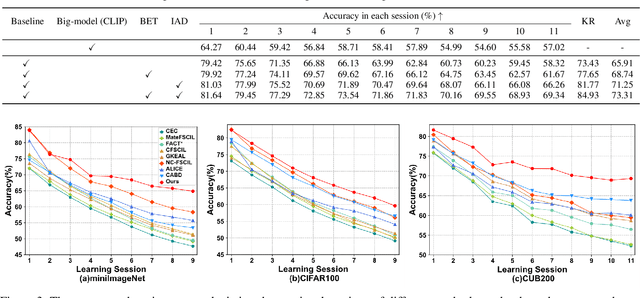
Few-shot continual learning (FSCL) has attracted intensive attention and achieved some advances in recent years, but now it is difficult to again make a big stride in accuracy due to the limitation of only few-shot incremental samples. Inspired by distinctive human cognition ability in life learning, in this work, we propose a novel Big-model driven Few-shot Continual Learning (B-FSCL) framework to gradually evolve the model under the traction of the world's big-models (like human accumulative knowledge). Specifically, we perform the big-model driven transfer learning to leverage the powerful encoding capability of these existing big-models, which can adapt the continual model to a few of newly added samples while avoiding the over-fitting problem. Considering that the big-model and the continual model may have different perceived results for the identical images, we introduce an instance-level adaptive decision mechanism to provide the high-level flexibility cognitive support adjusted to varying samples. In turn, the adaptive decision can be further adopted to optimize the parameters of the continual model, performing the adaptive distillation of big-model's knowledge information. Experimental results of our proposed B-FSCL on three popular datasets (including CIFAR100, minilmageNet and CUB200) completely surpass all state-of-the-art FSCL methods.
Dual-Stream Diffusion Net for Text-to-Video Generation
Aug 18, 2023



With the emerging diffusion models, recently, text-to-video generation has aroused increasing attention. But an important bottleneck therein is that generative videos often tend to carry some flickers and artifacts. In this work, we propose a dual-stream diffusion net (DSDN) to improve the consistency of content variations in generating videos. In particular, the designed two diffusion streams, video content and motion branches, could not only run separately in their private spaces for producing personalized video variations as well as content, but also be well-aligned between the content and motion domains through leveraging our designed cross-transformer interaction module, which would benefit the smoothness of generated videos. Besides, we also introduce motion decomposer and combiner to faciliate the operation on video motion. Qualitative and quantitative experiments demonstrate that our method could produce amazing continuous videos with fewer flickers.
Edit Temporal-Consistent Videos with Image Diffusion Model
Aug 17, 2023



Large-scale text-to-image (T2I) diffusion models have been extended for text-guided video editing, yielding impressive zero-shot video editing performance. Nonetheless, the generated videos usually show spatial irregularities and temporal inconsistencies as the temporal characteristics of videos have not been faithfully modeled. In this paper, we propose an elegant yet effective Temporal-Consistent Video Editing (TCVE) method, to mitigate the temporal inconsistency challenge for robust text-guided video editing. In addition to the utilization of a pretrained 2D Unet for spatial content manipulation, we establish a dedicated temporal Unet architecture to faithfully capture the temporal coherence of the input video sequences. Furthermore, to establish coherence and interrelation between the spatial-focused and temporal-focused components, a cohesive joint spatial-temporal modeling unit is formulated. This unit effectively interconnects the temporal Unet with the pretrained 2D Unet, thereby enhancing the temporal consistency of the generated video output while simultaneously preserving the capacity for video content manipulation. Quantitative experimental results and visualization results demonstrate that TCVE achieves state-of-the-art performance in both video temporal consistency and video editing capability, surpassing existing benchmarks in the field.