 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig-model Driven Few-shot Continual Learning
Sep 02, 2023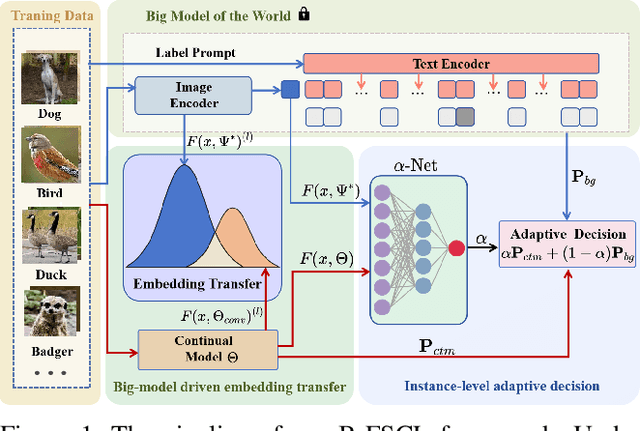
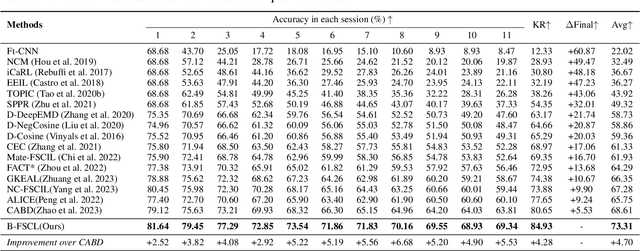
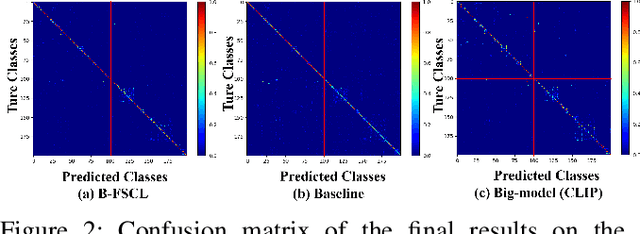
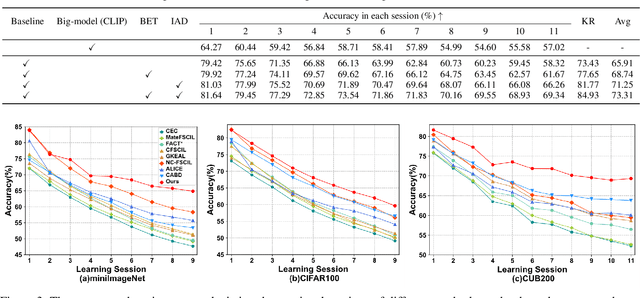
Few-shot continual learning (FSCL) has attracted intensive attention and achieved some advances in recent years, but now it is difficult to again make a big stride in accuracy due to the limitation of only few-shot incremental samples. Inspired by distinctive human cognition ability in life learning, in this work, we propose a novel Big-model driven Few-shot Continual Learning (B-FSCL) framework to gradually evolve the model under the traction of the world's big-models (like human accumulative knowledge). Specifically, we perform the big-model driven transfer learning to leverage the powerful encoding capability of these existing big-models, which can adapt the continual model to a few of newly added samples while avoiding the over-fitting problem. Considering that the big-model and the continual model may have different perceived results for the identical images, we introduce an instance-level adaptive decision mechanism to provide the high-level flexibility cognitive support adjusted to varying samples. In turn, the adaptive decision can be further adopted to optimize the parameters of the continual model, performing the adaptive distillation of big-model's knowledge information. Experimental results of our proposed B-FSCL on three popular datasets (including CIFAR100, minilmageNet and CUB200) completely surpass all state-of-the-art FSCL methods.
Federated Two-stage Learning with Sign-based Voting
Dec 10, 2021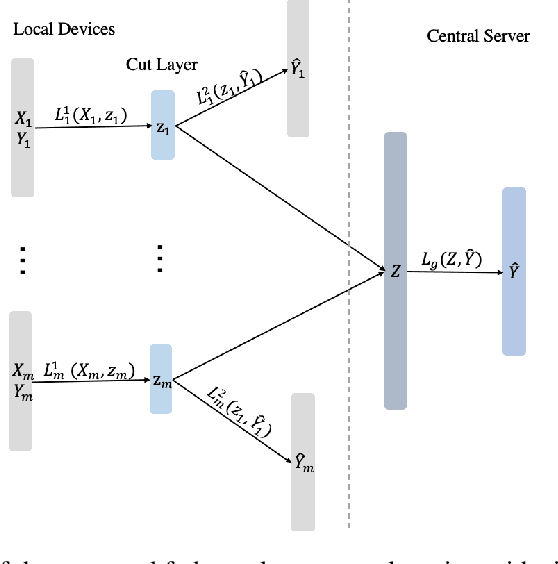
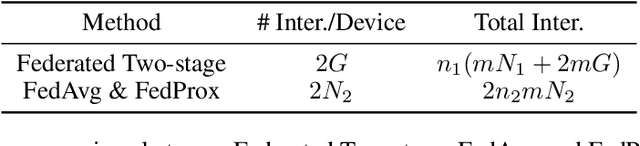
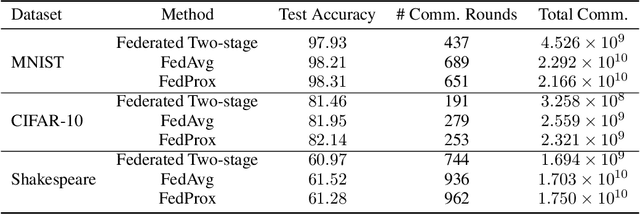
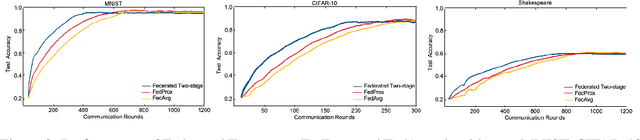
Federated learning is a distributed machine learning mechanism where local devices collaboratively train a shared global model under the orchestration of a central server, while keeping all private data decentralized. In the system, model parameters and its updates are transmitted instead of raw data, and thus the communication bottleneck has become a key challenge. Besides, recent larger and deeper machine learning models also pose more difficulties in deploying them in a federated environment. In this paper, we design a federated two-stage learning framework that augments prototypical federated learning with a cut layer on devices and uses sign-based stochastic gradient descent with the majority vote method on model updates. Cut layer on devices learns informative and low-dimension representations of raw data locally, which helps reduce global model parameters and prevents data leakage. Sign-based SGD with the majority vote method for model updates also helps alleviate communication limitations. Empirically, we show that our system is an efficient and privacy preserving federated learning scheme and suits for general application scenarios.
Towards Heterogeneous Clients with Elastic Federated Learning
Jun 17, 2021

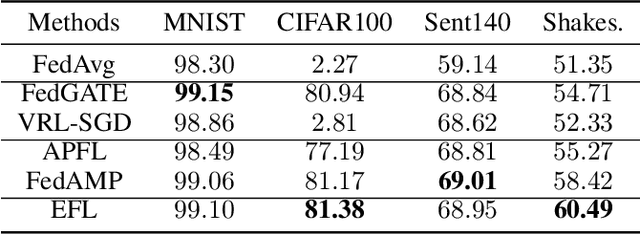

Federated learning involves training machine learning models over devices or data silos, such as edge processors or data warehouses, while keeping the data local. Training in heterogeneous and potentially massive networks introduces bias into the system, which is originated from the non-IID data and the low participation rate in reality. In this paper, we propose Elastic Federated Learning (EFL), an unbiased algorithm to tackle the heterogeneity in the system, which makes the most informative parameters less volatile during training, and utilizes the incomplete local updates. It is an efficient and effective algorithm that compresses both upstream and downstream communications. Theoretically, the algorithm has convergence guarantee when training on the non-IID data at the low participation rate. Empirical experiments corroborate the competitive performance of EFL framework on the robustness and the efficiency.