 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarCraft+: Benchmarking Multi-agent Algorithms in Adversary Paradigm
Dec 18, 2025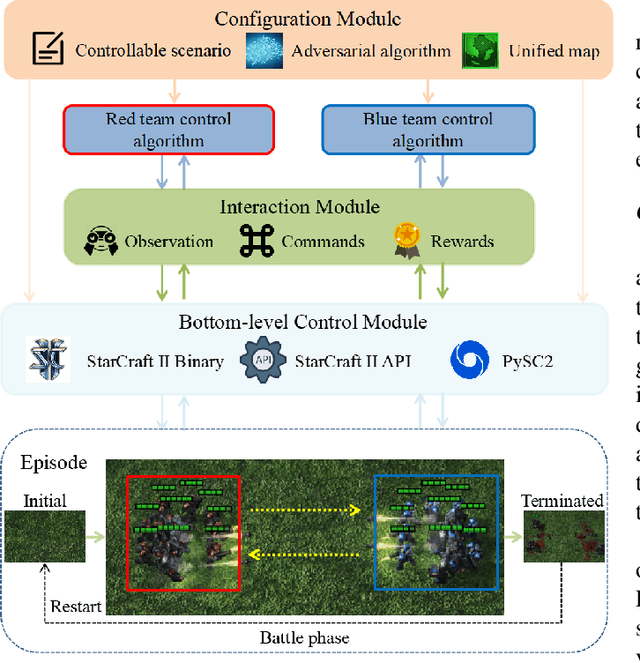
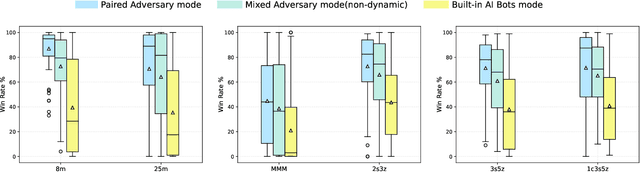
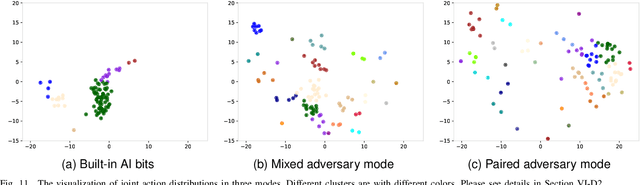
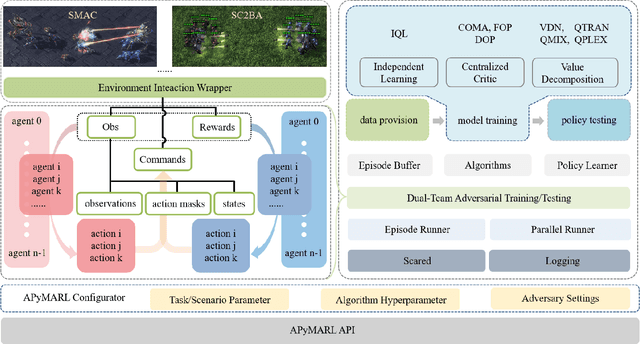
Deep multi-agent reinforcement learning (MARL) algorithms are booming in the field of collaborative intelligence, and StarCraft multi-agent challenge (SMAC) is widely-used as the benchmark therein. However, imaginary opponents of MARL algorithms are practically configured and controlled in a fixed built-in AI mode, which causes less diversity and versatility in algorithm evaluation. To address this issue, in this work, we establish a multi-agent algorithm-vs-algorithm environment, named StarCraft II battle arena (SC2BA), to refresh the benchmarking of MARL algorithms in an adversary paradigm. Taking StarCraft as infrastructure, the SC2BA environment is specifically created for inter-algorithm adversary with the consideration of fairness, usability and customizability, and meantime an adversarial PyMARL (APyMARL) library is developed with easy-to-use interfaces/modules. Grounding in SC2BA, we benchmark those classic MARL algorithms in two types of adversarial modes: dual-algorithm paired adversary and multi-algorithm mixed adversary, where the former conducts the adversary of pairwise algorithms while the latter focuses on the adversary to multiple behaviors from a group of algorithms. The extensive benchmark experiments exhibit some thought-provoking observations/problems in the effectivity, sensibility and scalability of these completed algorithms. The SC2BA environment as well as reproduced experiments are released in \href{https://github.com/dooliu/SC2BA}{Github}, and we believe that this work could mark a new step for the MARL field in the coming years.
Semantic Discrepancy-aware Detector for Image Forgery Identification
Aug 17, 2025With the rapid advancement of image generation techniques, robust forgery detection has become increasingly imperative to ensure the trustworthiness of digital media. Recent research indicates that the learned semantic concepts of pre-trained models are critical for identifying fake images. However, the misalignment between the forgery and semantic concept spaces hinders the model's forgery detection performance. To address this problem, we propose a novel Semantic Discrepancy-aware Detector (SDD) that leverages reconstruction learning to align the two spaces at a fine-grained visual level. By exploiting the conceptual knowledge embedded in the pre-trained vision language model, we specifically design a semantic token sampling module to mitigate the space shifts caused by features irrelevant to both forgery traces and semantic concepts. A concept-level forgery discrepancy learning module, built upon a visual reconstruction paradigm, is proposed to strengthen the interaction between visual semantic concepts and forgery traces, effectively capturing discrepancies under the concepts' guidance. Finally, the low-level forgery feature enhancemer integrates the learned concept level forgery discrepancies to minimize redundant forgery information. Experiments conducted on two standard image forgery datasets demonstrate the efficacy of the proposed SDD, which achieves superior results compared to existing methods. The code is available at https://github.com/wzy1111111/SSD.
MMHCL: Multi-Modal Hypergraph Contrastive Learning for Recommendation
Apr 23, 2025The burgeoning presence of multimodal content-sharing platforms propels the development of personalized recommender systems. Previous works usually suffer from data sparsity and cold-start problems, and may fail to adequately explore semantic user-product associations from multimodal data. To address these issues, we propose a novel Multi-Modal Hypergraph Contrastive Learning (MMHCL) framework for user recommendation. For a comprehensive information exploration from user-product relations, we construct two hypergraphs, i.e. a user-to-user (u2u) hypergraph and an item-to-item (i2i) hypergraph, to mine shared preferences among users and intricate multimodal semantic resemblance among items, respectively. This process yields denser second-order semantics that are fused with first-order user-item interaction as complementary to alleviate the data sparsity issue. Then, we design a contrastive feature enhancement paradigm by applying synergistic contrastive learning. By maximizing/minimizing the mutual information between second-order (e.g. shared preference pattern for users) and first-order (information of selected items for users) embeddings of the same/different users and items, the feature distinguishability can be effectively enhanced. Compared with using sparse primary user-item interaction only, our MMHCL obtains denser second-order hypergraphs and excavates more abundant shared attributes to explore the user-product associations, which to a certain extent alleviates the problems of data sparsity and cold-start. Extensive experiments have comprehensively demonstrated the effectiveness of our method. Our code is publicly available at: https://github.com/Xu107/MMHCL.
Multi-Modal Hypergraph Enhanced LLM Learning for Recommendation
Apr 13, 2025



The burgeoning presence of Large Language Models (LLM) is propelling the development of personalized recommender systems. Most existing LLM-based methods fail to sufficiently explore the multi-view graph structure correlations inherent in recommendation scenarios. To this end, we propose a novel framework, Hypergraph Enhanced LLM Learning for multimodal Recommendation (HeLLM), designed to equip LLMs with the capability to capture intricate higher-order semantic correlations by fusing graph-level contextual signals with sequence-level behavioral patterns. In the recommender pre-training phase, we design a user hypergraph to uncover shared interest preferences among users and an item hypergraph to capture correlations within multimodal similarities among items. The hypergraph convolution and synergistic contrastive learning mechanism are introduced to enhance the distinguishability of learned representations. In the LLM fine-tuning phase, we inject the learned graph-structured embeddings directly into the LLM's architecture and integrate sequential features capturing each user's chronological behavior. This process enables hypergraphs to leverage graph-structured information as global context, enhancing the LLM's ability to perceive complex relational patterns and integrate multimodal information, while also modeling local temporal dynamics. Extensive experiments demonstrate the superiority of our proposed method over state-of-the-art baselines, confirming the advantages of fusing hypergraph-based context with sequential user behavior in LLMs for recommendation.
Decoupled Doubly Contrastive Learning for Cross Domain Facial Action Unit Detection
Mar 12, 2025Despite the impressive performance of current vision-based facial action unit (AU) detection approaches, they are heavily susceptible to the variations across different domains and the cross-domain AU detection methods are under-explored. In response to this challenge, we propose a decoupled doubly contrastive adaptation (D$^2$CA) approach to learn a purified AU representation that is semantically aligned for the source and target domains. Specifically, we decompose latent representations into AU-relevant and AU-irrelevant components, with the objective of exclusively facilitating adaptation within the AU-relevant subspace. To achieve the feature decoupling, D$^2$CA is trained to disentangle AU and domain factors by assessing the quality of synthesized faces in cross-domain scenarios when either AU or domain attributes are modified. To further strengthen feature decoupling, particularly in scenarios with limited AU data diversity, D$^2$CA employs a doubly contrastive learning mechanism comprising image and feature-level contrastive learning to ensure the quality of synthesized faces and mitigate feature ambiguities. This new framework leads to an automatically learned, dedicated separation of AU-relevant and domain-relevant factors, and it enables intuitive, scale-specific control of the cross-domain facial image synthesis. Extensive experiments demonstrate the efficacy of D$^2$CA in successfully decoupling AU and domain factors, yielding visually pleasing cross-domain synthesized facial images. Meanwhile, D$^2$CA consistently outperforms state-of-the-art cross-domain AU detection approaches, achieving an average F1 score improvement of 6\%-14\% across various cross-domain scenarios.
* Accepted by IEEE Transactions on Image Processing 2025. A novel and elegant feature decoupling method for cross-domain facial action unit detection
Distribution Prototype Diffusion Learning for Open-set Supervised Anomaly Detection
Feb 28, 2025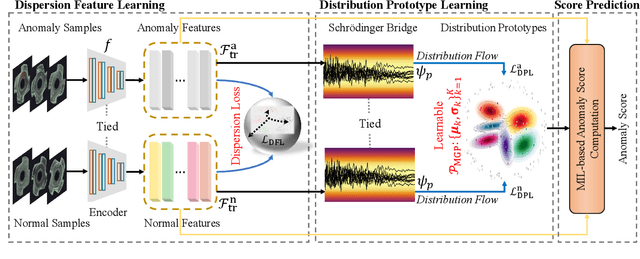
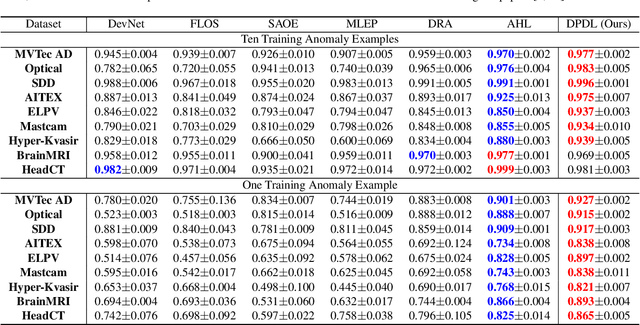
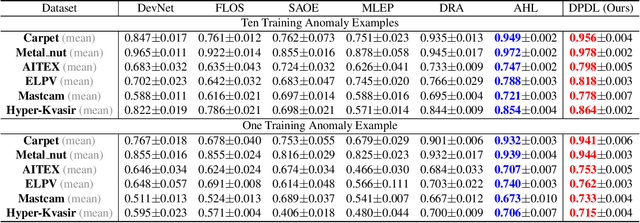
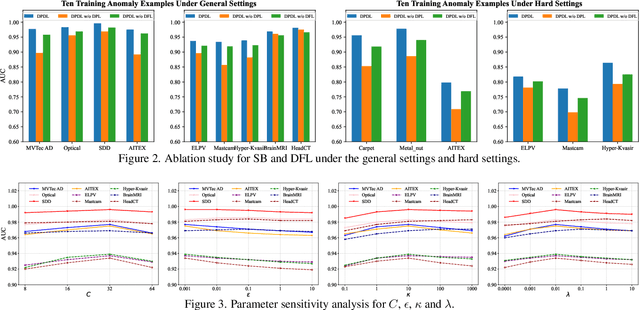
In Open-set Supervised Anomaly Detection (OSAD), the existing methods typically generate pseudo anomalies to compensate for the scarcity of observed anomaly samples, while overlooking critical priors of normal samples, leading to less effective discriminative boundaries. To address this issue, we propose a Distribution Prototype Diffusion Learning (DPDL) method aimed at enclosing normal samples within a compact and discriminative distribution space. Specifically, we construct multiple learnable Gaussian prototypes to create a latent representation space for abundant and diverse normal samples and learn a Schr\"odinger bridge to facilitate a diffusive transition toward these prototypes for normal samples while steering anomaly samples away. Moreover, to enhance inter-sample separation, we design a dispersion feature learning way in hyperspherical space, which benefits the identification of out-of-distribution anomalies. Experimental results demonstrate the effectiveness and superiority of our proposed DPDL, achieving state-of-the-art performance on 9 public datasets.
Multi-level Attention-guided Graph Neural Network for Image Restoration
Feb 26, 2025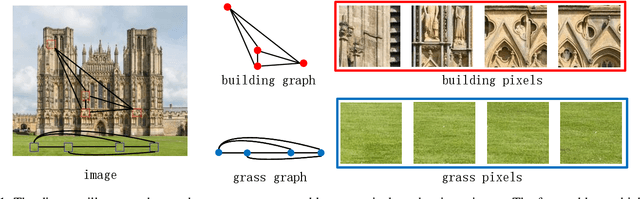
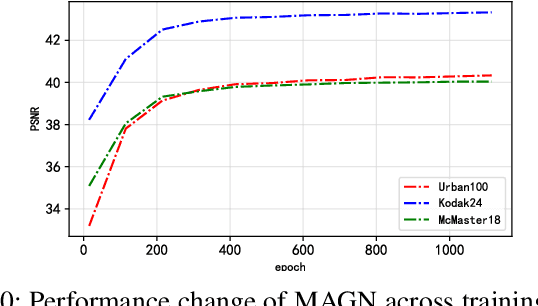
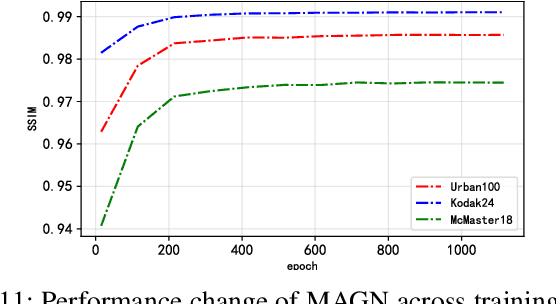

In recent years, deep learning has achieved remarkable success in the field of image restoration. However, most convolutional neural network-based methods typically focus on a single scale, neglecting the incorporation of multi-scale information. In image restoration tasks, local features of an image are often insufficient, necessitating the integration of global features to complement them. Although recent neural network algorithms have made significant strides in feature extraction, many models do not explicitly model global features or consider the relationship between global and local features. This paper proposes multi-level attention-guided graph neural network. The proposed network explicitly constructs element block graphs and element graphs within feature maps using multi-attention mechanisms to extract both local structural features and global representation information of the image. Since the network struggles to effectively extract global information during image degradation, the structural information of local feature blocks can be used to correct and supplement the global information. Similarly, when element block information in the feature map is missing, it can be refined using global element representation information. The graph within the network learns real-time dynamic connections through the multi-attention mechanism, and information is propagated and aggregated via graph convolution algorithms. By combining local element block information and global element representation information from the feature map, the algorithm can more effectively restore missing information in the image. Experimental results on several classic image restoration tasks demonstrate the effectiveness of the proposed method, achieving state-of-the-art performance.
Re-Attentional Controllable Video Diffusion Editing
Dec 16, 2024Editing videos with textual guidance has garnered popularity due to its streamlined process which mandates users to solely edit the text prompt corresponding to the source video. Recent studies have explored and exploited large-scale text-to-image diffusion models for text-guided video editing, resulting in remarkable video editing capabilities. However, they may still suffer from some limitations such as mislocated objects, incorrect number of objects. Therefore, the controllability of video editing remains a formidable challenge. In this paper, we aim to challenge the above limitations by proposing a Re-Attentional Controllable Video Diffusion Editing (ReAtCo) method. Specially, to align the spatial placement of the target objects with the edited text prompt in a training-free manner, we propose a Re-Attentional Diffusion (RAD) to refocus the cross-attention activation responses between the edited text prompt and the target video during the denoising stage, resulting in a spatially location-aligned and semantically high-fidelity manipulated video. In particular, to faithfully preserve the invariant region content with less border artifacts, we propose an Invariant Region-guided Joint Sampling (IRJS) strategy to mitigate the intrinsic sampling errors w.r.t the invariant regions at each denoising timestep and constrain the generated content to be harmonized with the invariant region content. Experimental results verify that ReAtCo consistently improves the controllability of video diffusion editing and achieves superior video editing performance.
MMM-RS: A Multi-modal, Multi-GSD, Multi-scene Remote Sensing Dataset and Benchmark for Text-to-Image Generation
Oct 26, 2024



Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS images across various modalities, scenes, weather conditions, and GSD. The dataset is available at https://github.com/ljl5261/MMM-RS.
MPDS: A Movie Posters Dataset for Image Generation with Diffusion Model
Oct 22, 2024



Movie posters are vital for captivating audiences, conveying themes, and driving market competition in the film industry. While traditional designs are laborious, intelligent generation technology offers efficiency gains and design enhancements. Despite exciting progress in image generation, current models often fall short in producing satisfactory poster results. The primary issue lies in the absence of specialized poster datasets for targeted model training. In this work, we propose a Movie Posters DataSet (MPDS), tailored for text-to-image generation models to revolutionize poster production. As dedicated to posters, MPDS stands out as the first image-text pair dataset to our knowledge, composing of 373k+ image-text pairs and 8k+ actor images (covering 4k+ actors). Detailed poster descriptions, such as movie titles, genres, casts, and synopses, are meticulously organized and standardized based on public movie synopsis, also named movie-synopsis prompt. To bolster poster descriptions as well as reduce differences from movie synopsis, further, we leverage a large-scale vision-language model to automatically produce vision-perceptive prompts for each poster, then perform manual rectification and integration with movie-synopsis prompt. In addition, we introduce a prompt of poster captions to exhibit text elements in posters like actor names and movie titles. For movie poster generation, we develop a multi-condition diffusion framework that takes poster prompt, poster caption, and actor image (for personalization) as inputs, yielding excellent results through the learning of a diffusion model. Experiments demonstrate the valuable role of our proposed MPDS dataset in advancing personalized movie poster generation. MPDS is available at https://anonymous.4open.science/r/MPDS-373k-BD3B.