 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Prototype Diffusion Learning for Open-set Supervised Anomaly Detection
Feb 28, 2025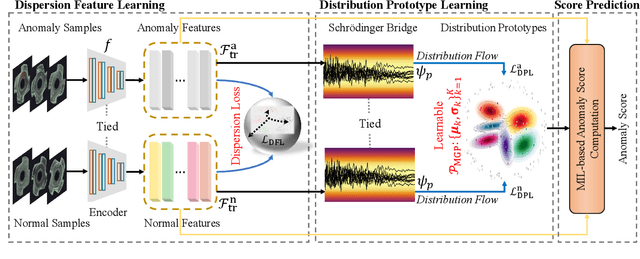
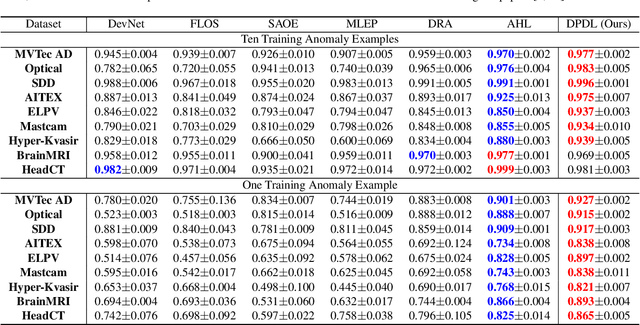
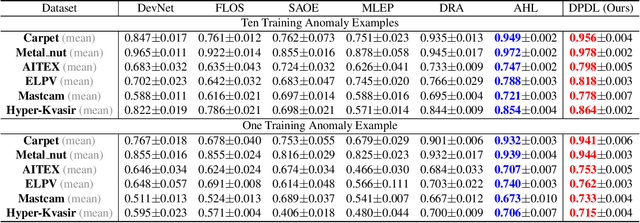
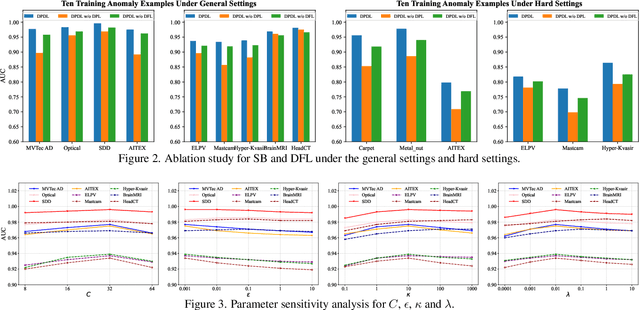
In Open-set Supervised Anomaly Detection (OSAD), the existing methods typically generate pseudo anomalies to compensate for the scarcity of observed anomaly samples, while overlooking critical priors of normal samples, leading to less effective discriminative boundaries. To address this issue, we propose a Distribution Prototype Diffusion Learning (DPDL) method aimed at enclosing normal samples within a compact and discriminative distribution space. Specifically, we construct multiple learnable Gaussian prototypes to create a latent representation space for abundant and diverse normal samples and learn a Schr\"odinger bridge to facilitate a diffusive transition toward these prototypes for normal samples while steering anomaly samples away. Moreover, to enhance inter-sample separation, we design a dispersion feature learning way in hyperspherical space, which benefits the identification of out-of-distribution anomalies. Experimental results demonstrate the effectiveness and superiority of our proposed DPDL, achieving state-of-the-art performance on 9 public datasets.
MMM-RS: A Multi-modal, Multi-GSD, Multi-scene Remote Sensing Dataset and Benchmark for Text-to-Image Generation
Oct 26, 2024



Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS images across various modalities, scenes, weather conditions, and GSD. The dataset is available at https://github.com/ljl5261/MMM-RS.
UniKG: A Benchmark and Universal Embedding for Large-Scale Knowledge Graphs
Sep 11, 2023



Irregular data in real-world are usually organized as heterogeneous graphs (HGs) consisting of multiple types of nodes and edges. To explore useful knowledge from real-world data, both the large-scale encyclopedic HG datasets and corresponding effective learning methods are crucial, but haven't been well investigated. In this paper, we construct a large-scale HG benchmark dataset named UniKG from Wikidata to facilitate knowledge mining and heterogeneous graph representation learning. Overall, UniKG contains more than 77 million multi-attribute entities and 2000 diverse association types, which significantly surpasses the scale of existing HG datasets. To perform effective learning on the large-scale UniKG, two key measures are taken, including (i) the semantic alignment strategy for multi-attribute entities, which projects the feature description of multi-attribute nodes into a common embedding space to facilitate node aggregation in a large receptive field; (ii) proposing a novel plug-and-play anisotropy propagation module (APM) to learn effective multi-hop anisotropy propagation kernels, which extends methods of large-scale homogeneous graphs to heterogeneous graphs. These two strategies enable efficient information propagation among a tremendous number of multi-attribute entities and meantimes adaptively mine multi-attribute association through the multi-hop aggregation in large-scale HGs. We set up a node classification task on our UniKG dataset, and evaluate multiple baseline methods which are constructed by embedding our APM into large-scale homogenous graph learning methods. Our UniKG dataset and the baseline codes have been released at https://github.com/Yide-Qiu/UniKG.