 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPWOOD: Sparse Partial Weakly-Supervised Oriented Object Detection
Feb 03, 2026A consistent trend throughout the research of oriented object detection has been the pursuit of maintaining comparable performance with fewer and weaker annotations. This is particularly crucial in the remote sensing domain, where the dense object distribution and a wide variety of categories contribute to prohibitively high costs. Based on the supervision level, existing oriented object detection algorithms can be broadly grouped into fully supervised, semi-supervised, and weakly supervised methods. Within the scope of this work, we further categorize them to include sparsely supervised and partially weakly-supervised methods. To address the challenges of large-scale labeling, we introduce the first Sparse Partial Weakly-Supervised Oriented Object Detection framework, designed to efficiently leverage only a few sparse weakly-labeled data and plenty of unlabeled data. Our framework incorporates three key innovations: (1) We design a Sparse-annotation-Orientation-and-Scale-aware Student (SOS-Student) model to separate unlabeled objects from the background in a sparsely-labeled setting, and learn orientation and scale information from orientation-agnostic or scale-agnostic weak annotations. (2) We construct a novel Multi-level Pseudo-label Filtering strategy that leverages the distribution of model predictions, which is informed by the model's multi-layer predictions. (3) We propose a unique sparse partitioning approach, ensuring equal treatment for each category. Extensive experiments on the DOTA and DIOR datasets show that our framework achieves a significant performance gain over traditional oriented object detection methods mentioned above, offering a highly cost-effective solution. Our code is publicly available at https://github.com/VisionXLab/SPWOOD.
Semantic Discrepancy-aware Detector for Image Forgery Identification
Aug 17, 2025With the rapid advancement of image generation techniques, robust forgery detection has become increasingly imperative to ensure the trustworthiness of digital media. Recent research indicates that the learned semantic concepts of pre-trained models are critical for identifying fake images. However, the misalignment between the forgery and semantic concept spaces hinders the model's forgery detection performance. To address this problem, we propose a novel Semantic Discrepancy-aware Detector (SDD) that leverages reconstruction learning to align the two spaces at a fine-grained visual level. By exploiting the conceptual knowledge embedded in the pre-trained vision language model, we specifically design a semantic token sampling module to mitigate the space shifts caused by features irrelevant to both forgery traces and semantic concepts. A concept-level forgery discrepancy learning module, built upon a visual reconstruction paradigm, is proposed to strengthen the interaction between visual semantic concepts and forgery traces, effectively capturing discrepancies under the concepts' guidance. Finally, the low-level forgery feature enhancemer integrates the learned concept level forgery discrepancies to minimize redundant forgery information. Experiments conducted on two standard image forgery datasets demonstrate the efficacy of the proposed SDD, which achieves superior results compared to existing methods. The code is available at https://github.com/wzy1111111/SSD.
Multi-level Attention-guided Graph Neural Network for Image Restoration
Feb 26, 2025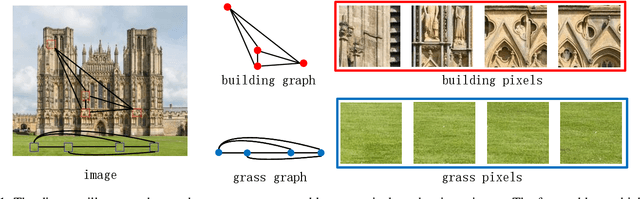
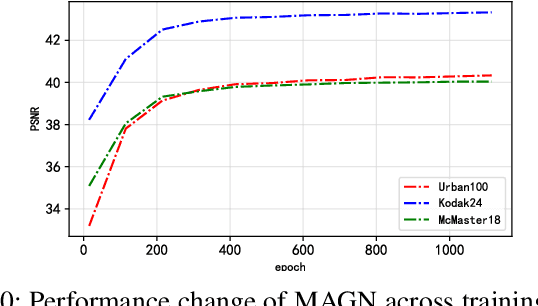
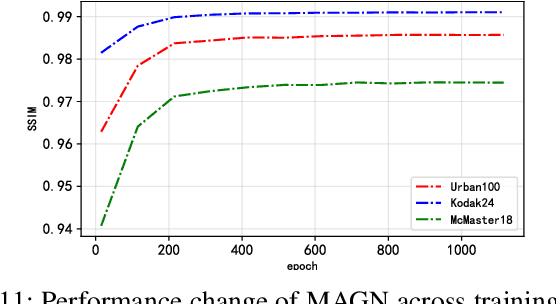

In recent years, deep learning has achieved remarkable success in the field of image restoration. However, most convolutional neural network-based methods typically focus on a single scale, neglecting the incorporation of multi-scale information. In image restoration tasks, local features of an image are often insufficient, necessitating the integration of global features to complement them. Although recent neural network algorithms have made significant strides in feature extraction, many models do not explicitly model global features or consider the relationship between global and local features. This paper proposes multi-level attention-guided graph neural network. The proposed network explicitly constructs element block graphs and element graphs within feature maps using multi-attention mechanisms to extract both local structural features and global representation information of the image. Since the network struggles to effectively extract global information during image degradation, the structural information of local feature blocks can be used to correct and supplement the global information. Similarly, when element block information in the feature map is missing, it can be refined using global element representation information. The graph within the network learns real-time dynamic connections through the multi-attention mechanism, and information is propagated and aggregated via graph convolution algorithms. By combining local element block information and global element representation information from the feature map, the algorithm can more effectively restore missing information in the image. Experimental results on several classic image restoration tasks demonstrate the effectiveness of the proposed method, achieving state-of-the-art performance.
MMM-RS: A Multi-modal, Multi-GSD, Multi-scene Remote Sensing Dataset and Benchmark for Text-to-Image Generation
Oct 26, 2024



Recently, the diffusion-based generative paradigm has achieved impressive general image generation capabilities with text prompts due to its accurate distribution modeling and stable training process. However, generating diverse remote sensing (RS) images that are tremendously different from general images in terms of scale and perspective remains a formidable challenge due to the lack of a comprehensive remote sensing image generation dataset with various modalities, ground sample distances (GSD), and scenes. In this paper, we propose a Multi-modal, Multi-GSD, Multi-scene Remote Sensing (MMM-RS) dataset and benchmark for text-to-image generation in diverse remote sensing scenarios. Specifically, we first collect nine publicly available RS datasets and conduct standardization for all samples. To bridge RS images to textual semantic information, we utilize a large-scale pretrained vision-language model to automatically output text prompts and perform hand-crafted rectification, resulting in information-rich text-image pairs (including multi-modal images). In particular, we design some methods to obtain the images with different GSD and various environments (e.g., low-light, foggy) in a single sample. With extensive manual screening and refining annotations, we ultimately obtain a MMM-RS dataset that comprises approximately 2.1 million text-image pairs. Extensive experimental results verify that our proposed MMM-RS dataset allows off-the-shelf diffusion models to generate diverse RS images across various modalities, scenes, weather conditions, and GSD. The dataset is available at https://github.com/ljl5261/MMM-RS.
Frequency-Spatial Entanglement Learning for Camouflaged Object Detection
Sep 03, 2024



Camouflaged object detection has attracted a lot of attention in computer vision. The main challenge lies in the high degree of similarity between camouflaged objects and their surroundings in the spatial domain, making identification difficult. Existing methods attempt to reduce the impact of pixel similarity by maximizing the distinguishing ability of spatial features with complicated design, but often ignore the sensitivity and locality of features in the spatial domain, leading to sub-optimal results. In this paper, we propose a new approach to address this issue by jointly exploring the representation in the frequency and spatial domains, introducing the Frequency-Spatial Entanglement Learning (FSEL) method. This method consists of a series of well-designed Entanglement Transformer Blocks (ETB) for representation learning, a Joint Domain Perception Module for semantic enhancement, and a Dual-domain Reverse Parser for feature integration in the frequency and spatial domains. Specifically, the ETB utilizes frequency self-attention to effectively characterize the relationship between different frequency bands, while the entanglement feed-forward network facilitates information interaction between features of different domains through entanglement learning. Our extensive experiments demonstrate the superiority of our FSEL over 21 state-of-the-art methods, through comprehensive quantitative and qualitative comparisons in three widely-used datasets. The source code is available at: https://github.com/CSYSI/FSEL.
Multi-clue Consistency Learning to Bridge Gaps Between General and Oriented Object in Semi-supervised Detection
Jul 08, 2024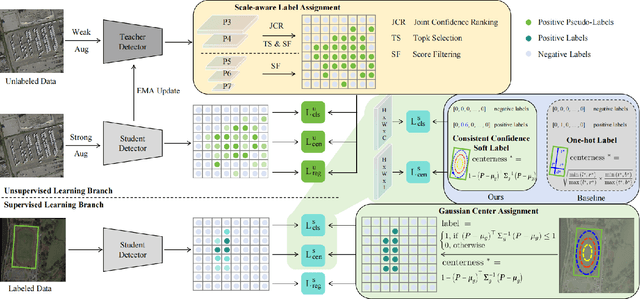
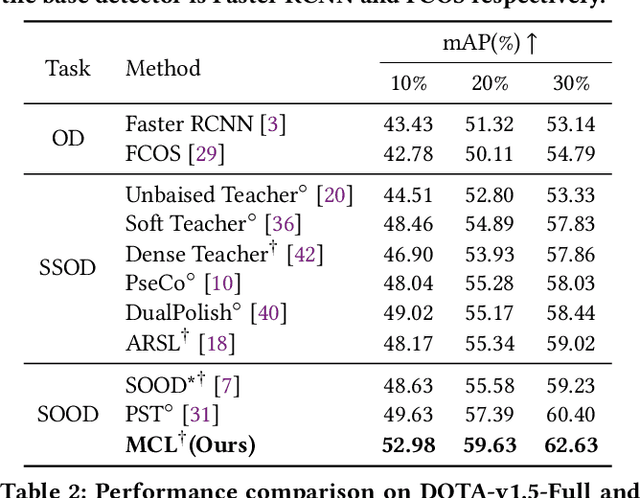
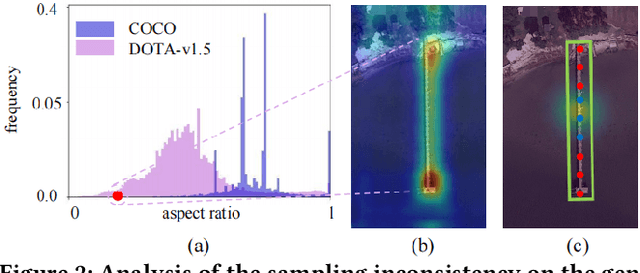

While existing semi-supervised object detection (SSOD) methods perform well in general scenes, they encounter challenges in handling oriented objects in aerial images. We experimentally find three gaps between general and oriented object detection in semi-supervised learning: 1) Sampling inconsistency: the common center sampling is not suitable for oriented objects with larger aspect ratios when selecting positive labels from labeled data. 2) Assignment inconsistency: balancing the precision and localization quality of oriented pseudo-boxes poses greater challenges which introduces more noise when selecting positive labels from unlabeled data. 3) Confidence inconsistency: there exists more mismatch between the predicted classification and localization qualities when considering oriented objects, affecting the selection of pseudo-labels. Therefore, we propose a Multi-clue Consistency Learning (MCL) framework to bridge gaps between general and oriented objects in semi-supervised detection. Specifically, considering various shapes of rotated objects, the Gaussian Center Assignment is specially designed to select the pixel-level positive labels from labeled data. We then introduce the Scale-aware Label Assignment to select pixel-level pseudo-labels instead of unreliable pseudo-boxes, which is a divide-and-rule strategy suited for objects with various scales. The Consistent Confidence Soft Label is adopted to further boost the detector by maintaining the alignment of the predicted results. Comprehensive experiments on DOTA-v1.5 and DOTA-v1.0 benchmarks demonstrate that our proposed MCL can achieve state-of-the-art performance in the semi-supervised oriented object detection task.
Big-model Driven Few-shot Continual Learning
Sep 02, 2023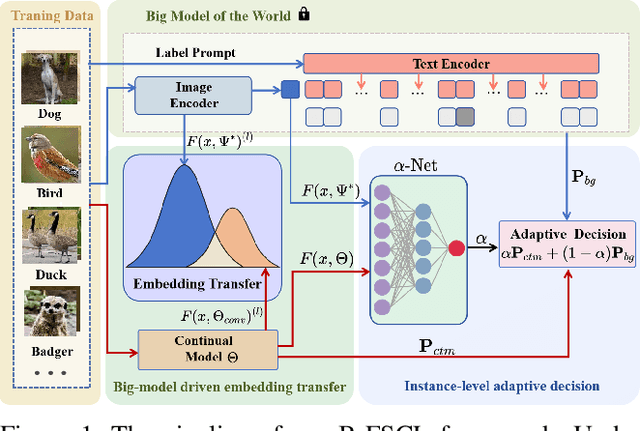
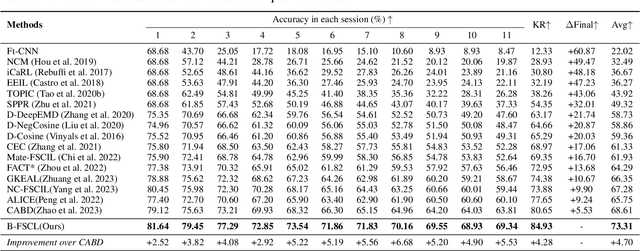
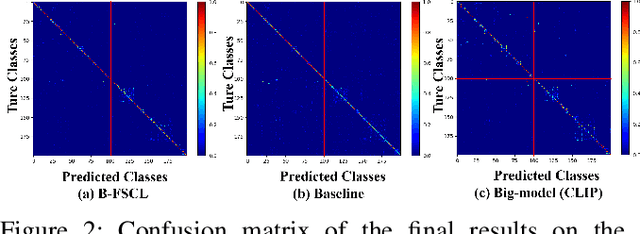
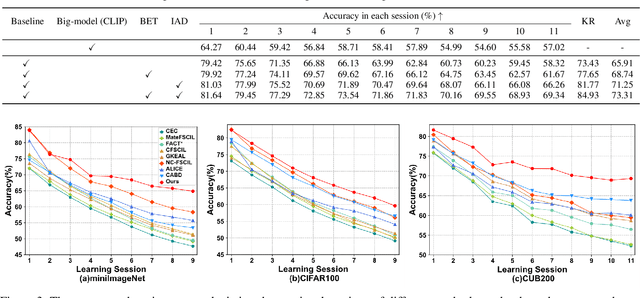
Few-shot continual learning (FSCL) has attracted intensive attention and achieved some advances in recent years, but now it is difficult to again make a big stride in accuracy due to the limitation of only few-shot incremental samples. Inspired by distinctive human cognition ability in life learning, in this work, we propose a novel Big-model driven Few-shot Continual Learning (B-FSCL) framework to gradually evolve the model under the traction of the world's big-models (like human accumulative knowledge). Specifically, we perform the big-model driven transfer learning to leverage the powerful encoding capability of these existing big-models, which can adapt the continual model to a few of newly added samples while avoiding the over-fitting problem. Considering that the big-model and the continual model may have different perceived results for the identical images, we introduce an instance-level adaptive decision mechanism to provide the high-level flexibility cognitive support adjusted to varying samples. In turn, the adaptive decision can be further adopted to optimize the parameters of the continual model, performing the adaptive distillation of big-model's knowledge information. Experimental results of our proposed B-FSCL on three popular datasets (including CIFAR100, minilmageNet and CUB200) completely surpass all state-of-the-art FSCL methods.
Learning Normal Dynamics in Videos with Meta Prototype Network
May 10, 2021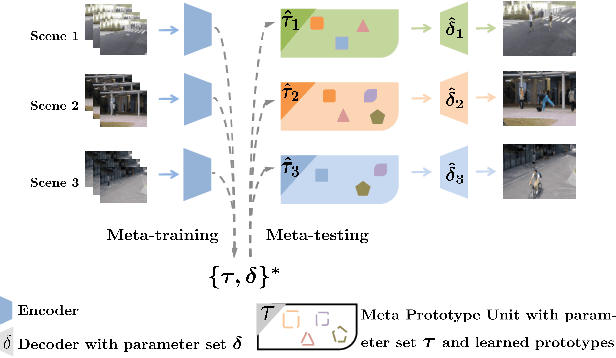
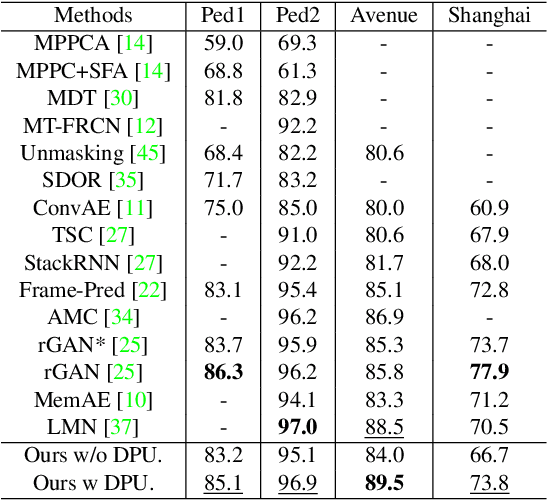
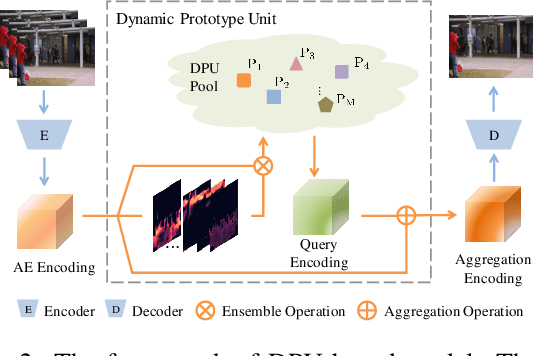
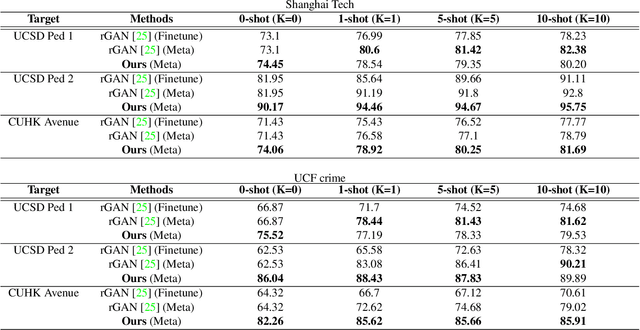
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory-consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a dynamic prototype unit (DPU) to encode the normal dynamics as prototypes in real time, free from extra memory cost. In addition, we introduce meta-learning to our DPU to form a novel few-shot normalcy learner, namely Meta-Prototype Unit (MPU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method.
Global Information Guided Video Anomaly Detection
Apr 14, 2021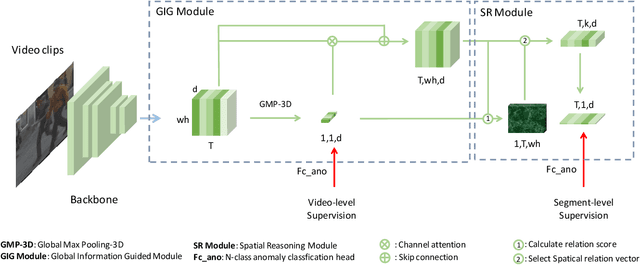
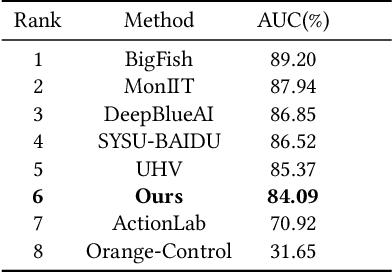
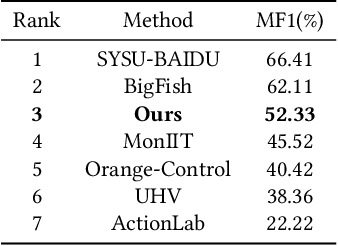
Video anomaly detection (VAD) is currently a challenging task due to the complexity of anomaly as well as the lack of labor-intensive temporal annotations. In this paper, we propose an end-to-end Global Information Guided (GIG) anomaly detection framework for anomaly detection using the video-level annotations (i.e., weak labels). We propose to first mine the global pattern cues by leveraging the weak labels in a GIG module. Then we build a spatial reasoning module to measure the relevance between vectors in spatial domain with the global cue vectors, and select the most related feature vectors for temporal anomaly detection. The experimental results on the CityScene challenge demonstrate the effectiveness of our model.
Spatial-Temporal Tensor Graph Convolutional Network for Traffic Prediction
Mar 10, 2021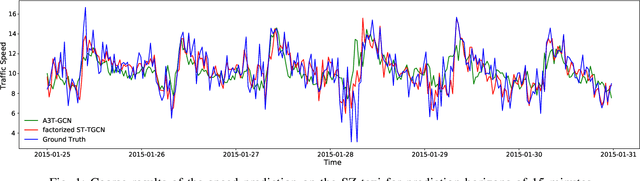
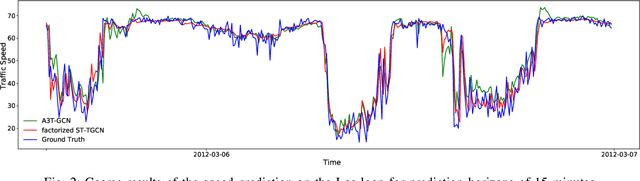
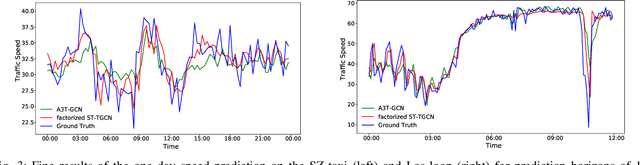

Accurate traffic prediction is crucial to the guidance and management of urban traffics. However, most of the existing traffic prediction models do not consider the computational burden and memory space when they capture spatial-temporal dependence among traffic data. In this work, we propose a factorized Spatial-Temporal Tensor Graph Convolutional Network to deal with traffic speed prediction. Traffic networks are modeled and unified into a graph that integrates spatial and temporal information simultaneously. We further extend graph convolution into tensor space and propose a tensor graph convolution network to extract more discriminating features from spatial-temporal graph data. To reduce the computational burden, we take Tucker tensor decomposition and derive factorized a tensor convolution, which performs separate filtering in small-scale space, time, and feature modes. Besides, we can benefit from noise suppression of traffic data when discarding those trivial components in the process of tensor decomposition. Extensive experiments on two real-world traffic speed datasets demonstrate our method is more effective than those traditional traffic prediction methods, and meantime achieves state-of-the-art performance.