 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Anomaly Detection and Explanation via Large Language Models
Jan 11, 2024Video Anomaly Detection (VAD) aims to localize abnormal events on the timeline of long-range surveillance videos. Anomaly-scoring-based methods have been prevailing for years but suffer from the high complexity of thresholding and low explanability of detection results. In this paper, we conduct pioneer research on equipping video-based large language models (VLLMs) in the framework of VAD, making the VAD model free from thresholds and able to explain the reasons for the detected anomalies. We introduce a novel network module Long-Term Context (LTC) to mitigate the incapability of VLLMs in long-range context modeling. We design a three-phase training method to improve the efficiency of fine-tuning VLLMs by substantially minimizing the requirements for VAD data and lowering the costs of annotating instruction-tuning data. Our trained model achieves the top performance on the anomaly videos of the UCF-Crime and TAD benchmarks, with the AUC improvements of +3.86\% and +4.96\%, respectively. More impressively, our approach can provide textual explanations for detected anomalies.
Unbiased Multiple Instance Learning for Weakly Supervised Video Anomaly Detection
Mar 22, 2023Weakly Supervised Video Anomaly Detection (WSVAD) is challenging because the binary anomaly label is only given on the video level, but the output requires snippet-level predictions. So, Multiple Instance Learning (MIL) is prevailing in WSVAD. However, MIL is notoriously known to suffer from many false alarms because the snippet-level detector is easily biased towards the abnormal snippets with simple context, confused by the normality with the same bias, and missing the anomaly with a different pattern. To this end, we propose a new MIL framework: Unbiased MIL (UMIL), to learn unbiased anomaly features that improve WSVAD. At each MIL training iteration, we use the current detector to divide the samples into two groups with different context biases: the most confident abnormal/normal snippets and the rest ambiguous ones. Then, by seeking the invariant features across the two sample groups, we can remove the variant context biases. Extensive experiments on benchmarks UCF-Crime and TAD demonstrate the effectiveness of our UMIL. Our code is provided at https://github.com/ktr-hubrt/UMIL.
Spatio-Temporal Relation Learning for Video Anomaly Detection
Sep 27, 2022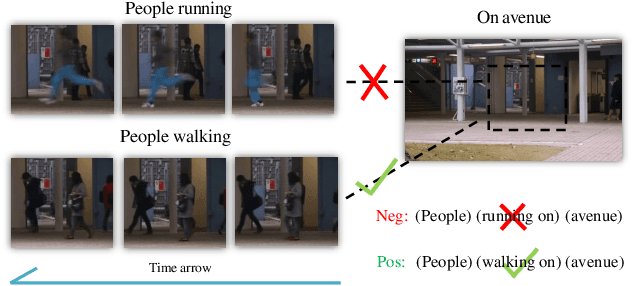
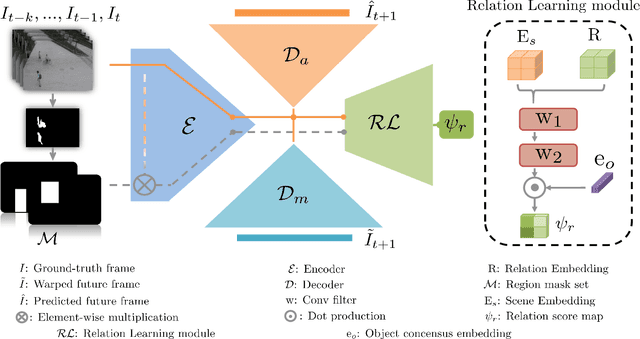
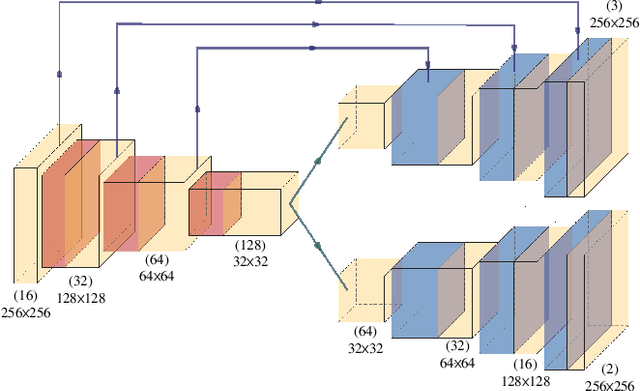
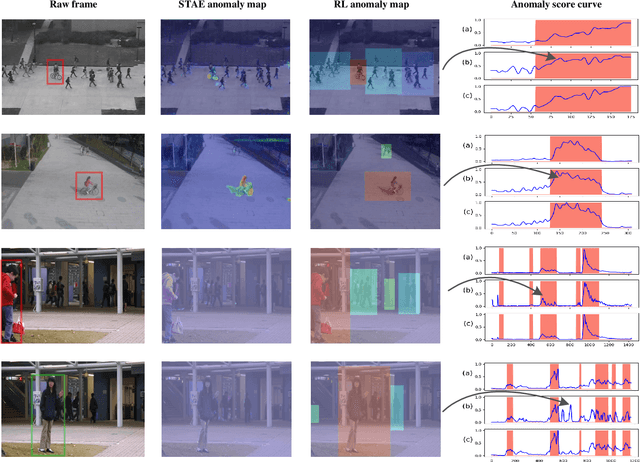
Anomaly identification is highly dependent on the relationship between the object and the scene, as different/same object actions in same/different scenes may lead to various degrees of normality and anomaly. Therefore, object-scene relation actually plays a crucial role in anomaly detection but is inadequately explored in previous works. In this paper, we propose a Spatial-Temporal Relation Learning (STRL) framework to tackle the video anomaly detection task. First, considering dynamic characteristics of the objects as well as scene areas, we construct a Spatio-Temporal Auto-Encoder (STAE) to jointly exploit spatial and temporal evolution patterns for representation learning. For better pattern extraction, two decoding branches are designed in the STAE module, i.e. an appearance branch capturing spatial cues by directly predicting the next frame, and a motion branch focusing on modeling the dynamics via optical flow prediction. Then, to well concretize the object-scene relation, a Relation Learning (RL) module is devised to analyze and summarize the normal relations by introducing the Knowledge Graph Embedding methodology. Specifically in this process, the plausibility of object-scene relation is measured by jointly modeling object/scene features and optimizable object-scene relation maps. Extensive experiments are conducted on three public datasets, and the superior performance over the state-of-the-art methods demonstrates the effectiveness of our method.
Learning Normal Dynamics in Videos with Meta Prototype Network
May 10, 2021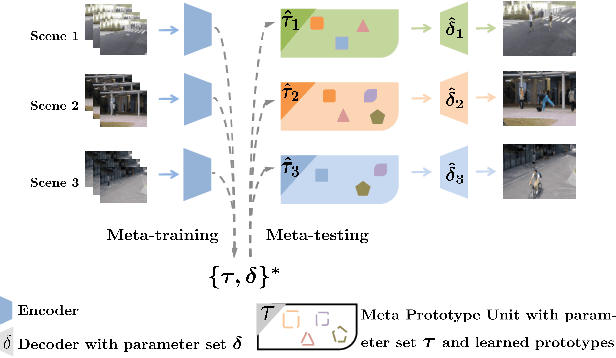
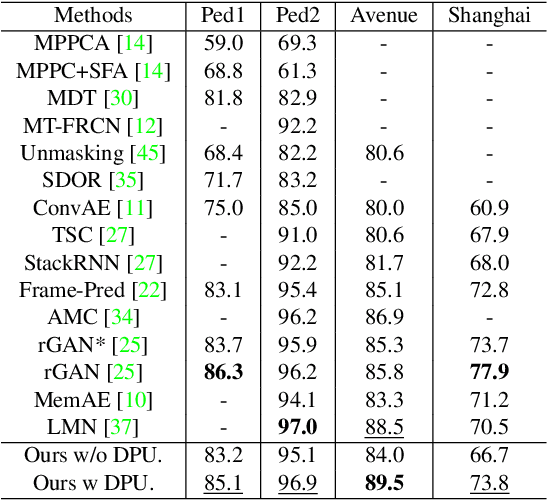
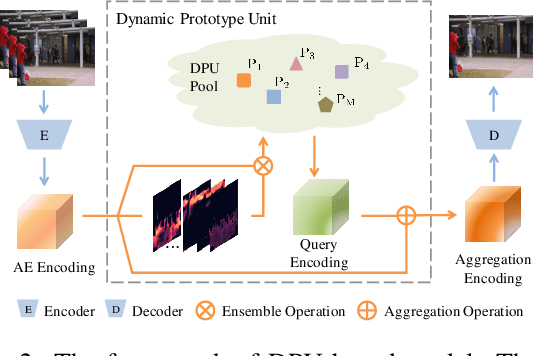
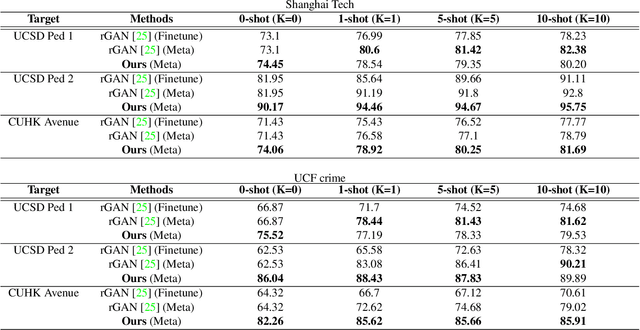
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory-consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a dynamic prototype unit (DPU) to encode the normal dynamics as prototypes in real time, free from extra memory cost. In addition, we introduce meta-learning to our DPU to form a novel few-shot normalcy learner, namely Meta-Prototype Unit (MPU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method.
Global Information Guided Video Anomaly Detection
Apr 14, 2021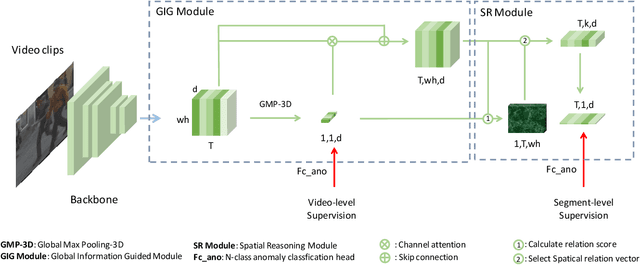
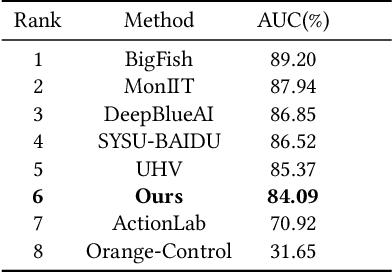
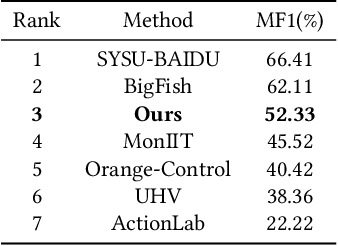
Video anomaly detection (VAD) is currently a challenging task due to the complexity of anomaly as well as the lack of labor-intensive temporal annotations. In this paper, we propose an end-to-end Global Information Guided (GIG) anomaly detection framework for anomaly detection using the video-level annotations (i.e., weak labels). We propose to first mine the global pattern cues by leveraging the weak labels in a GIG module. Then we build a spatial reasoning module to measure the relevance between vectors in spatial domain with the global cue vectors, and select the most related feature vectors for temporal anomaly detection. The experimental results on the CityScene challenge demonstrate the effectiveness of our model.
Localizing Anomalies from Weakly-Labeled Videos
Aug 20, 2020
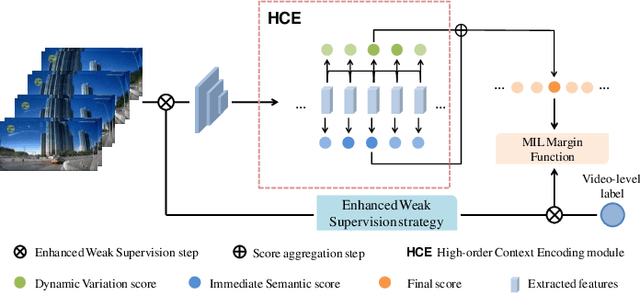


Video anomaly detection under video-level labels is currently a challenging task. Previous works have made progresses on discriminating whether a video sequencecontains anomalies. However, most of them fail to accurately localize the anomalous events within videos in the temporal domain. In this paper, we propose a Weakly Supervised Anomaly Localization (WSAL) method focusing on temporally localizing anomalous segments within anomalous videos. Inspired by the appearance difference in anomalous videos, the evolution of adjacent temporal segments is evaluated for the localization of anomalous segments. To this end, a high-order context encoding model is proposed to not only extract semantic representations but also measure the dynamic variations so that the temporal context could be effectively utilized. In addition, in order to fully utilize the spatial context information, the immediate semantics are directly derived from the segment representations. The dynamic variations as well as the immediate semantics, are efficiently aggregated to obtain the final anomaly scores. An enhancement strategy is further proposed to deal with noise interference and the absence of localization guidance in anomaly detection. Moreover, to facilitate the diversity requirement for anomaly detection benchmarks, we also collect a new traffic anomaly (TAD) dataset which specifies in the traffic conditions, differing greatly from the current popular anomaly detection evaluation benchmarks.Extensive experiments are conducted to verify the effectiveness of different components, and our proposed method achieves new state-of-the-art performance on the UCF-Crime and TAD datasets.