 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention
Feb 05, 2026While humans perceive the world through diverse modalities that operate synergistically to support a holistic understanding of their surroundings, existing omnivideo models still face substantial challenges on audio-visual understanding tasks. In this paper, we propose OmniVideo-R1, a novel reinforced framework that improves mixed-modality reasoning. OmniVideo-R1 empowers models to "think with omnimodal cues" by two key strategies: (1) query-intensive grounding based on self-supervised learning paradigms; and (2) modality-attentive fusion built upon contrastive learning paradigms. Extensive experiments on multiple benchmarks demonstrate that OmniVideo-R1 consistently outperforms strong baselines, highlighting its effectiveness and robust generalization capabilities.
RISE-T2V: Rephrasing and Injecting Semantics with LLM for Expansive Text-to-Video Generation
Nov 06, 2025Most text-to-video(T2V) diffusion models depend on pre-trained text encoders for semantic alignment, yet they often fail to maintain video quality when provided with concise prompts rather than well-designed ones. The primary issue lies in their limited textual semantics understanding. Moreover, these text encoders cannot rephrase prompts online to better align with user intentions, which limits both the scalability and usability of the models, To address these challenges, we introduce RISE-T2V, which uniquely integrates the processes of prompt rephrasing and semantic feature extraction into a single and seamless step instead of two separate steps. RISE-T2V is universal and can be applied to various pre-trained LLMs and video diffusion models(VDMs), significantly enhancing their capabilities for T2V tasks. We propose an innovative module called the Rephrasing Adapter, enabling diffusion models to utilize text hidden states during the next token prediction of the LLM as a condition for video generation. By employing a Rephrasing Adapter, the video generation model can implicitly rephrase basic prompts into more comprehensive representations that better match the user's intent. Furthermore, we leverage the powerful capabilities of LLMs to enable video generation models to accomplish a broader range of T2V tasks. Extensive experiments demonstrate that RISE-T2V is a versatile framework applicable to different video diffusion model architectures, significantly enhancing the ability of T2V models to generate high-quality videos that align with user intent. Visual results are available on the webpage at https://rise-t2v.github.io.
Developing Trajectory Planning with Behavioral Cloning and Proximal Policy Optimization for Path-Tracking and Static Obstacle Nudging
Sep 09, 2024



End-to-end approaches with Reinforcement Learning (RL) and Imitation Learning (IL) have gained increasing popularity in autonomous driving. However, they do not involve explicit reasoning like classic robotics workflow, nor planning with horizons, leading strategies implicit and myopic. In this paper, we introduce our trajectory planning method that uses Behavioral Cloning (BC) for path-tracking and Proximal Policy Optimization (PPO) bootstrapped by BC for static obstacle nudging. It outputs lateral offset values to adjust the given reference trajectory, and performs modified path for different controllers. Our experimental results show that the algorithm can do path-tracking that mimics the expert performance, and avoiding collision to fixed obstacles by trial and errors. This method makes a good attempt at planning with learning-based methods in trajectory planning problems of autonomous driving.
Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights
Jul 28, 2024



Despite the recognized potential of multimodal data to improve model accuracy, many large-scale industrial recommendation systems, including Taobao display advertising system, predominantly depend on sparse ID features in their models. In this work, we explore approaches to leverage multimodal data to enhance the recommendation accuracy. We start from identifying the key challenges in adopting multimodal data in a manner that is both effective and cost-efficient for industrial systems. To address these challenges, we introduce a two-phase framework, including: 1) the pre-training of multimodal representations to capture semantic similarity, and 2) the integration of these representations with existing ID-based models. Furthermore, we detail the architecture of our production system, which is designed to facilitate the deployment of multimodal representations. Since the integration of multimodal representations in mid-2023, we have observed significant performance improvements in Taobao display advertising system. We believe that the insights we have gathered will serve as a valuable resource for practitioners seeking to leverage multimodal data in their systems.
PersonificationNet: Making customized subject act like a person
Jul 12, 2024



Recently customized generation has significant potential, which uses as few as 3-5 user-provided images to train a model to synthesize new images of a specified subject. Though subsequent applications enhance the flexibility and diversity of customized generation, fine-grained control over the given subject acting like the person's pose is still lack of study. In this paper, we propose a PersonificationNet, which can control the specified subject such as a cartoon character or plush toy to act the same pose as a given referenced person's image. It contains a customized branch, a pose condition branch and a structure alignment module. Specifically, first, the customized branch mimics specified subject appearance. Second, the pose condition branch transfers the body structure information from the human to variant instances. Last, the structure alignment module bridges the structure gap between human and specified subject in the inference stage. Experimental results show our proposed PersonificationNet outperforms the state-of-the-art methods.
Image-Conditional Diffusion Transformer for Underwater Image Enhancement
Jul 07, 2024



Underwater image enhancement (UIE) has attracted much attention owing to its importance for underwater operation and marine engineering. Motivated by the recent advance in generative models, we propose a novel UIE method based on image-conditional diffusion transformer (ICDT). Our method takes the degraded underwater image as the conditional input and converts it into latent space where ICDT is applied. ICDT replaces the conventional U-Net backbone in a denoising diffusion probabilistic model (DDPM) with a transformer, and thus inherits favorable properties such as scalability from transformers. Furthermore, we train ICDT with a hybrid loss function involving variances to achieve better log-likelihoods, which meanwhile significantly accelerates the sampling process. We experimentally assess the scalability of ICDTs and compare with prior works in UIE on the Underwater ImageNet dataset. Besides good scaling properties, our largest model, ICDT-XL/2, outperforms all comparison methods, achieving state-of-the-art (SOTA) quality of image enhancement.
Classification of Power Quality Disturbances Using Resnet with Channel Attention Mechanism
Jul 02, 2024
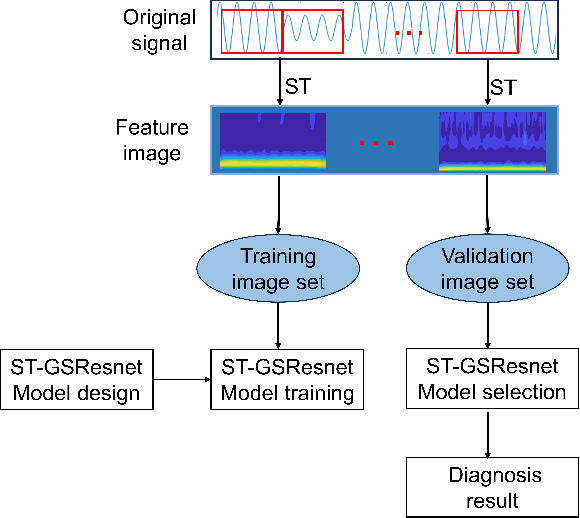
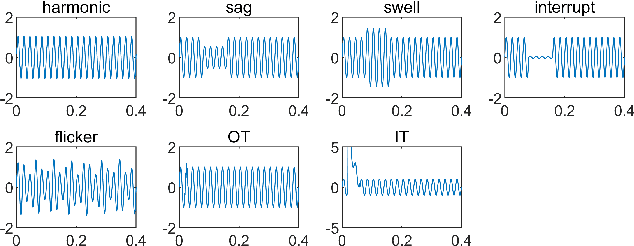
The detection and classification of power quality disturbances (PQDs) carries significant importance for power systems. In response to this imperative, numerous intelligent diagnostic methods have been developed. However, existing identification methods usually concentrate on single-type signals or on complex signals with two types, rendering them susceptible to noisy labels and environmental effects. This study proposes a novel method for the classification of PQDs, termed ST-GSResNet, which utilizes the S-Transform and an improved residual neural network (ResNet) with a channel attention mechanism. The ST-GSResNet approach initially uses the S-Transform to transform a time-series signal into a 2D time-frequency image for feature enhancement. Then, an improved ResNet model is introduced, which employs grouped convolution instead of the traditional convolution operation. This improvement aims to facilitate learning with a block-diagonal structured sparsity on the channel dimension, the highly-correlated filters are learned in a more structured way in the networks with filter groups. By reducing the number of parameters in the network in this significant manner, the model becomes less prone to overfitting. Furthermore, the SE module concentrates on primary components, which enhances the model's robustness in recognition and immunity to noise. Experimental results demonstrate that, compared to existing deep learning models, our approach has advantages in computational efficiency and classification accuracy.
AtomoVideo: High Fidelity Image-to-Video Generation
Mar 05, 2024



Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high fidelity framework for image-to-video generation, named AtomoVideo. Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation. Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website: https://atomo-video.github.io/.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024



Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.
Underwater motions analysis and control of a coupling-tiltable unmanned aerial-aquatic quadrotor
Dec 12, 2023
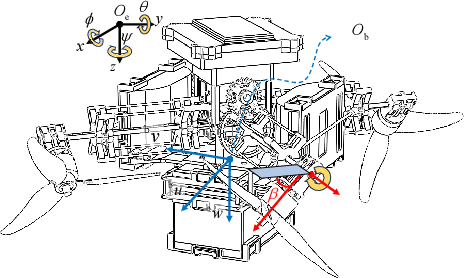
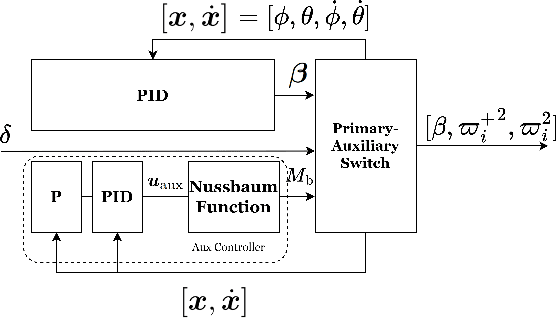
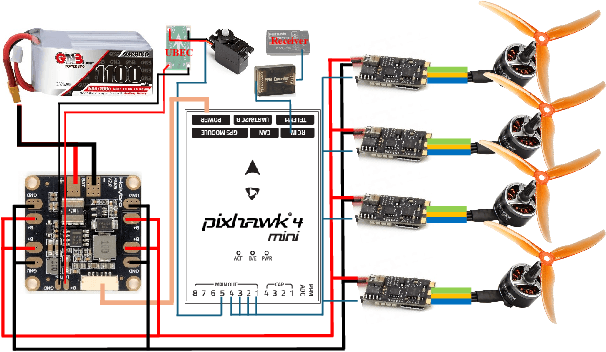
This paper proposes a method for analyzing a series of potential motions in a coupling-tiltable aerial-aquatic quadrotor based on its nonlinear dynamics. Some characteristics and constraints derived by this method are specified as Singular Thrust Tilt Angles (STTAs), utilizing to generate motions including planar motions. A switch-based control scheme addresses issues of control direction uncertainty inherent to the mechanical structure by incorporating a saturated Nussbaum function. A high-fidelity simulation environment incorporating a comprehensive hydrodynamic model is built based on a Hardware-In-The-Loop (HITL) setup with Gazebo and a flight control board. The experiments validate the effectiveness of the absolute and quasi planar motions, which cannot be achieved by conventional quadrotors, and demonstrate stable performance when the pitch or roll angle is activated in the auxiliary control channel.