 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
Jul 03, 2025Process Reinforcement Learning~(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models~(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5\% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.
Efficient Token Compression for Vision Transformer with Spatial Information Preserved
Mar 30, 2025



Token compression is essential for reducing the computational and memory requirements of transformer models, enabling their deployment in resource-constrained environments. In this work, we propose an efficient and hardware-compatible token compression method called Prune and Merge. Our approach integrates token pruning and merging operations within transformer models to achieve layer-wise token compression. By introducing trainable merge and reconstruct matrices and utilizing shortcut connections, we efficiently merge tokens while preserving important information and enabling the restoration of pruned tokens. Additionally, we introduce a novel gradient-weighted attention scoring mechanism that computes token importance scores during the training phase, eliminating the need for separate computations during inference and enhancing compression efficiency. We also leverage gradient information to capture the global impact of tokens and automatically identify optimal compression structures. Extensive experiments on the ImageNet-1k and ADE20K datasets validate the effectiveness of our approach, achieving significant speed-ups with minimal accuracy degradation compared to state-of-the-art methods. For instance, on DeiT-Small, we achieve a 1.64$\times$ speed-up with only a 0.2\% drop in accuracy on ImageNet-1k. Moreover, by compressing segmenter models and comparing with existing methods, we demonstrate the superior performance of our approach in terms of efficiency and effectiveness. Code and models have been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/prune_and_merge.
PersonificationNet: Making customized subject act like a person
Jul 12, 2024



Recently customized generation has significant potential, which uses as few as 3-5 user-provided images to train a model to synthesize new images of a specified subject. Though subsequent applications enhance the flexibility and diversity of customized generation, fine-grained control over the given subject acting like the person's pose is still lack of study. In this paper, we propose a PersonificationNet, which can control the specified subject such as a cartoon character or plush toy to act the same pose as a given referenced person's image. It contains a customized branch, a pose condition branch and a structure alignment module. Specifically, first, the customized branch mimics specified subject appearance. Second, the pose condition branch transfers the body structure information from the human to variant instances. Last, the structure alignment module bridges the structure gap between human and specified subject in the inference stage. Experimental results show our proposed PersonificationNet outperforms the state-of-the-art methods.
Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution
Dec 03, 2022



In contrast to fully supervised methods using pixel-wise mask labels, box-supervised instance segmentation takes advantage of simple box annotations, which has recently attracted increasing research attention. This paper presents a novel single-shot instance segmentation approach, namely Box2Mask, which integrates the classical level-set evolution model into deep neural network learning to achieve accurate mask prediction with only bounding box supervision. Specifically, both the input image and its deep features are employed to evolve the level-set curves implicitly, and a local consistency module based on a pixel affinity kernel is used to mine the local context and spatial relations. Two types of single-stage frameworks, i.e., CNN-based and transformer-based frameworks, are developed to empower the level-set evolution for box-supervised instance segmentation, and each framework consists of three essential components: instance-aware decoder, box-level matching assignment and level-set evolution. By minimizing the level-set energy function, the mask map of each instance can be iteratively optimized within its bounding box annotation. The experimental results on five challenging testbeds, covering general scenes, remote sensing, medical and scene text images, demonstrate the outstanding performance of our proposed Box2Mask approach for box-supervised instance segmentation. In particular, with the Swin-Transformer large backbone, our Box2Mask obtains 42.4% mask AP on COCO, which is on par with the recently developed fully mask-supervised methods. The code is available at: https://github.com/LiWentomng/boxlevelset.
Box-supervised Instance Segmentation with Level Set Evolution
Jul 19, 2022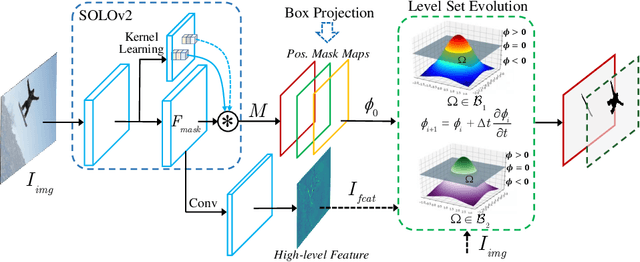
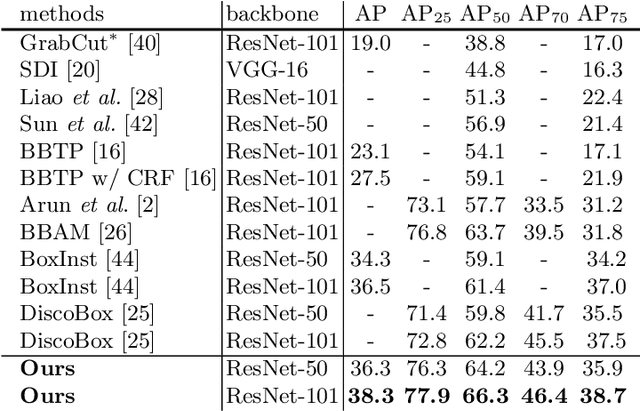
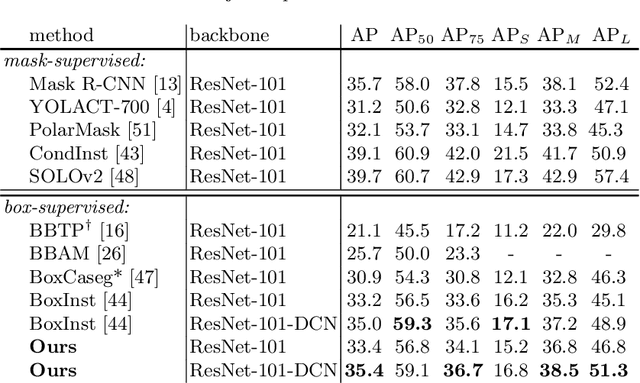

In contrast to the fully supervised methods using pixel-wise mask labels, box-supervised instance segmentation takes advantage of the simple box annotations, which has recently attracted a lot of research attentions. In this paper, we propose a novel single-shot box-supervised instance segmentation approach, which integrates the classical level set model with deep neural network delicately. Specifically, our proposed method iteratively learns a series of level sets through a continuous Chan-Vese energy-based function in an end-to-end fashion. A simple mask supervised SOLOv2 model is adapted to predict the instance-aware mask map as the level set for each instance. Both the input image and its deep features are employed as the input data to evolve the level set curves, where a box projection function is employed to obtain the initial boundary. By minimizing the fully differentiable energy function, the level set for each instance is iteratively optimized within its corresponding bounding box annotation. The experimental results on four challenging benchmarks demonstrate the leading performance of our proposed approach to robust instance segmentation in various scenarios. The code is available at: https://github.com/LiWentomng/boxlevelset.
SP-ViT: Learning 2D Spatial Priors for Vision Transformers
Jun 15, 2022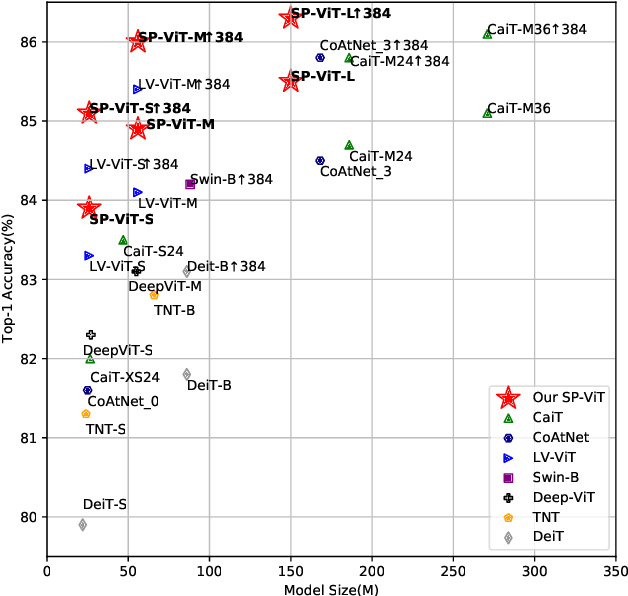
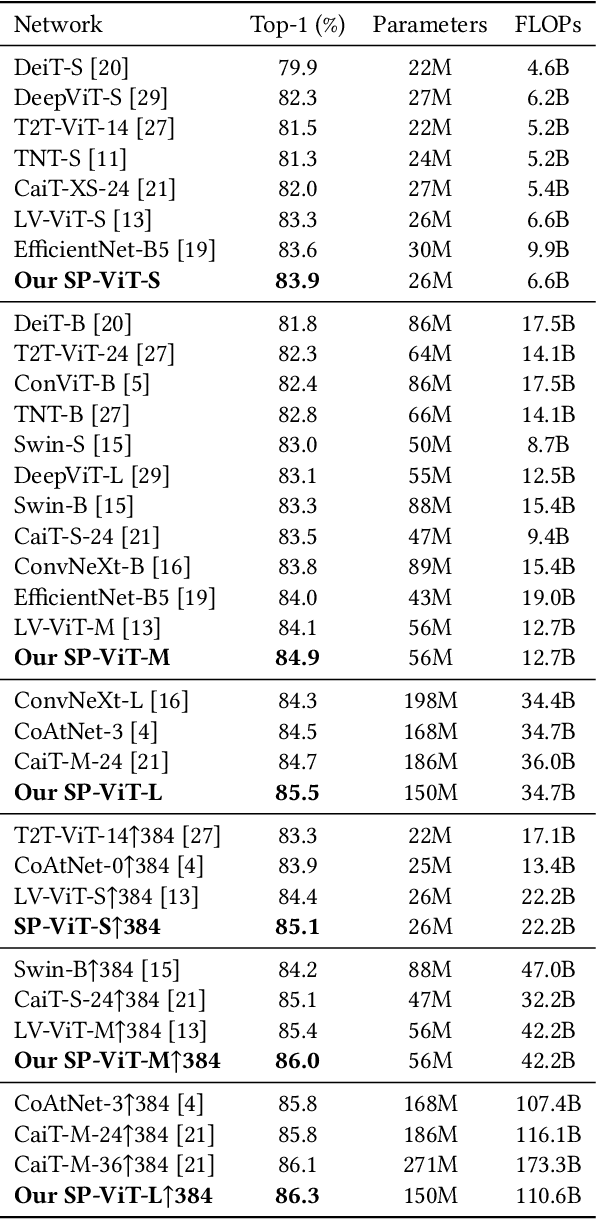
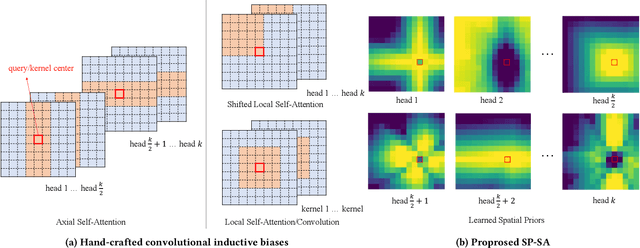

Recently, transformers have shown great potential in image classification and established state-of-the-art results on the ImageNet benchmark. However, compared to CNNs, transformers converge slowly and are prone to overfitting in low-data regimes due to the lack of spatial inductive biases. Such spatial inductive biases can be especially beneficial since the 2D structure of an input image is not well preserved in transformers. In this work, we present Spatial Prior-enhanced Self-Attention (SP-SA), a novel variant of vanilla Self-Attention (SA) tailored for vision transformers. Spatial Priors (SPs) are our proposed family of inductive biases that highlight certain groups of spatial relations. Unlike convolutional inductive biases, which are forced to focus exclusively on hard-coded local regions, our proposed SPs are learned by the model itself and take a variety of spatial relations into account. Specifically, the attention score is calculated with emphasis on certain kinds of spatial relations at each head, and such learned spatial foci can be complementary to each other. Based on SP-SA we propose the SP-ViT family, which consistently outperforms other ViT models with similar GFlops or parameters. Our largest model SP-ViT-L achieves a record-breaking 86.3% Top-1 accuracy with a reduction in the number of parameters by almost 50% compared to previous state-of-the-art model (150M for SP-ViT-L vs 271M for CaiT-M-36) among all ImageNet-1K models trained on 224x224 and fine-tuned on 384x384 resolution w/o extra data.
Online Convolutional Re-parameterization
Apr 02, 2022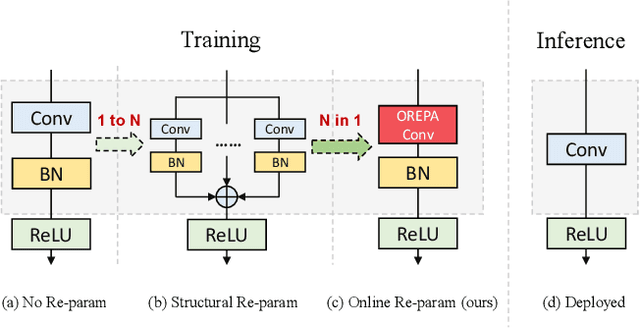
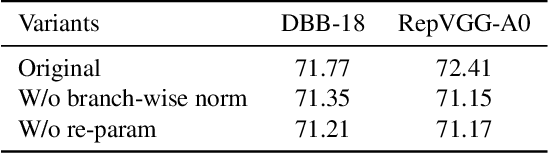
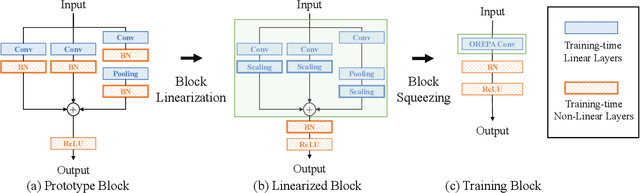
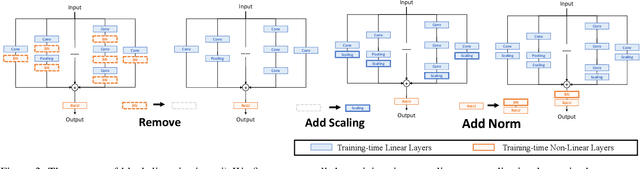
Structural re-parameterization has drawn increasing attention in various computer vision tasks. It aims at improving the performance of deep models without introducing any inference-time cost. Though efficient during inference, such models rely heavily on the complicated training-time blocks to achieve high accuracy, leading to large extra training cost. In this paper, we present online convolutional re-parameterization (OREPA), a two-stage pipeline, aiming to reduce the huge training overhead by squeezing the complex training-time block into a single convolution. To achieve this goal, we introduce a linear scaling layer for better optimizing the online blocks. Assisted with the reduced training cost, we also explore some more effective re-param components. Compared with the state-of-the-art re-param models, OREPA is able to save the training-time memory cost by about 70% and accelerate the training speed by around 2x. Meanwhile, equipped with OREPA, the models outperform previous methods on ImageNet by up to +0.6%.We also conduct experiments on object detection and semantic segmentation and show consistent improvements on the downstream tasks. Codes are available at https://github.com/JUGGHM/OREPA_CVPR2022 .
Beyond a Video Frame Interpolator: A Space Decoupled Learning Approach to Continuous Image Transition
Mar 18, 2022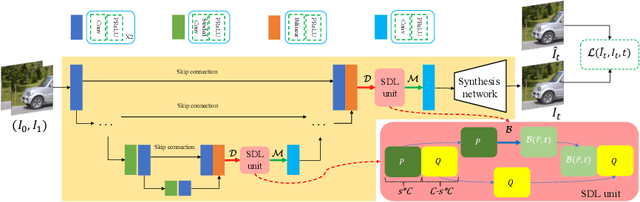
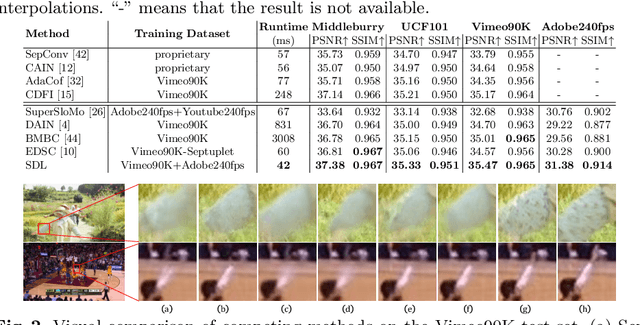


Video frame interpolation (VFI) aims to improve the temporal resolution of a video sequence. Most of the existing deep learning based VFI methods adopt off-the-shelf optical flow algorithms to estimate the bidirectional flows and interpolate the missing frames accordingly. Though having achieved a great success, these methods require much human experience to tune the bidirectional flows and often generate unpleasant results when the estimated flows are not accurate. In this work, we rethink the VFI problem and formulate it as a continuous image transition (CIT) task, whose key issue is to transition an image from one space to another space continuously. More specifically, we learn to implicitly decouple the images into a translatable flow space and a non-translatable feature space. The former depicts the translatable states between the given images, while the later aims to reconstruct the intermediate features that cannot be directly translated. In this way, we can easily perform image interpolation in the flow space and intermediate image synthesis in the feature space, obtaining a CIT model. The proposed space decoupled learning (SDL) approach is simple to implement, while it provides an effective framework to a variety of CIT problems beyond VFI, such as style transfer and image morphing. Our extensive experiments on a variety of CIT tasks demonstrate the superiority of SDL to existing methods. The source code and models can be found at \url{https://github.com/yangxy/SDL}.
PANet: Perspective-Aware Network with Dynamic Receptive Fields and Self-Distilling Supervision for Crowd Counting
Oct 31, 2021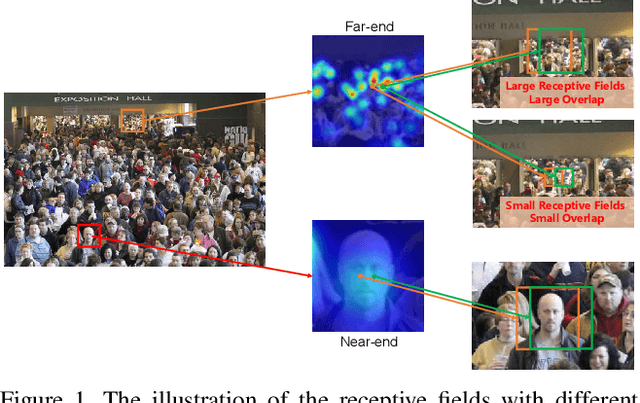
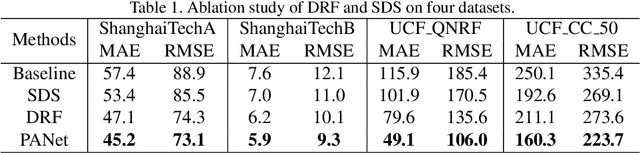
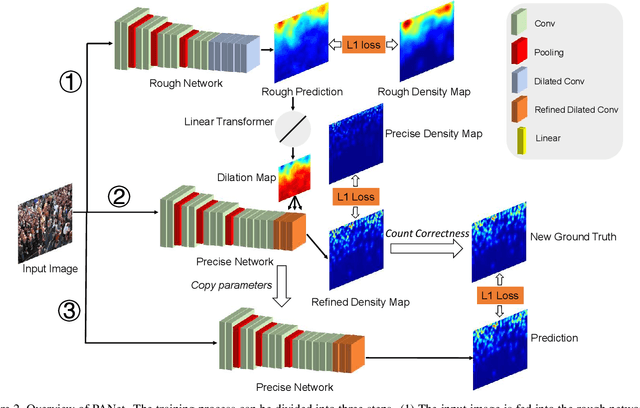

Crowd counting aims to learn the crowd density distributions and estimate the number of objects (e.g. persons) in images. The perspective effect, which significantly influences the distribution of data points, plays an important role in crowd counting. In this paper, we propose a novel perspective-aware approach called PANet to address the perspective problem. Based on the observation that the size of the objects varies greatly in one image due to the perspective effect, we propose the dynamic receptive fields (DRF) framework. The framework is able to adjust the receptive field by the dilated convolution parameters according to the input image, which helps the model to extract more discriminative features for each local region. Different from most previous works which use Gaussian kernels to generate the density map as the supervised information, we propose the self-distilling supervision (SDS) training method. The ground-truth density maps are refined from the first training stage and the perspective information is distilled to the model in the second stage. The experimental results on ShanghaiTech Part_A and Part_B, UCF_QNRF, and UCF_CC_50 datasets demonstrate that our proposed PANet outperforms the state-of-the-art methods by a large margin.
Discriminative-Generative Dual Memory Video Anomaly Detection
Apr 29, 2021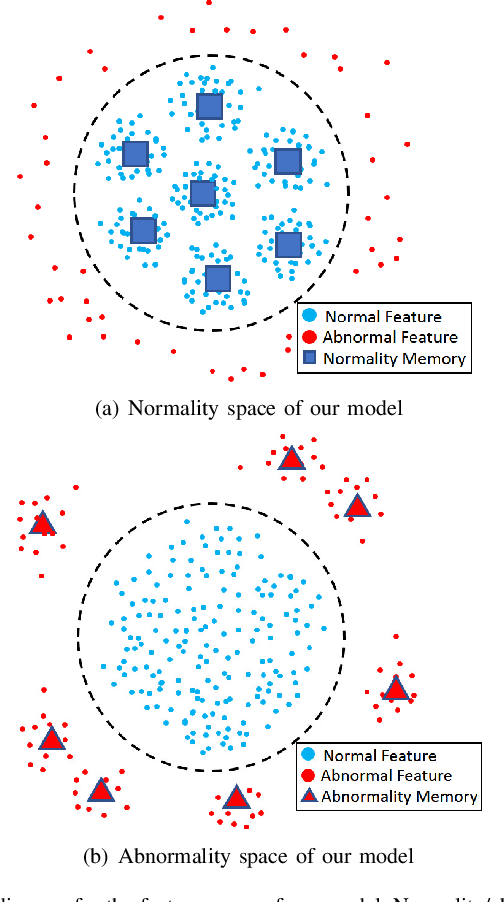
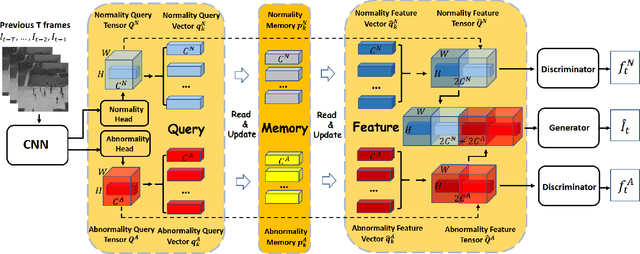
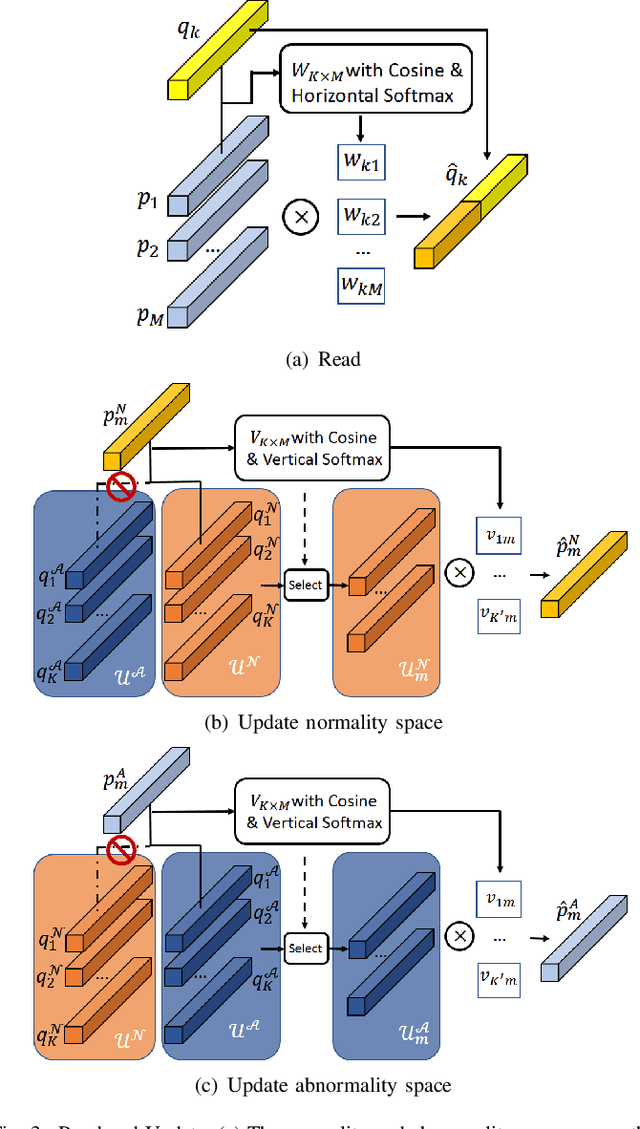
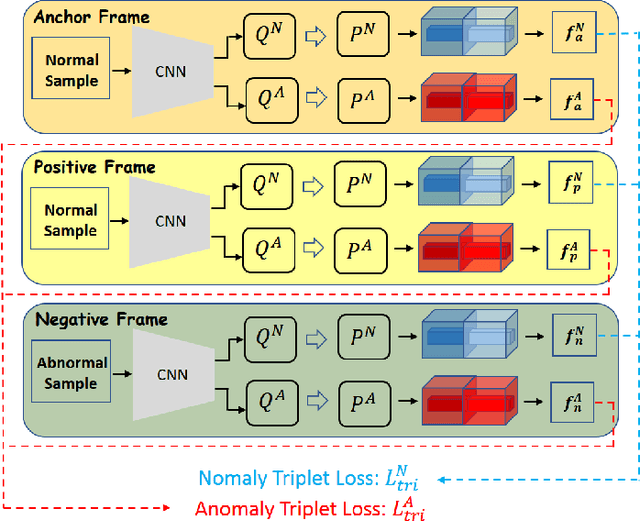
Recently, people tried to use a few anomalies for video anomaly detection (VAD) instead of only normal data during the training process. A side effect of data imbalance occurs when a few abnormal data face a vast number of normal data. The latest VAD works use triplet loss or data re-sampling strategy to lessen this problem. However, there is still no elaborately designed structure for discriminative VAD with a few anomalies. In this paper, we propose a DiscRiminative-gEnerative duAl Memory (DREAM) anomaly detection model to take advantage of a few anomalies and solve data imbalance. We use two shallow discriminators to tighten the normal feature distribution boundary along with a generator for the next frame prediction. Further, we propose a dual memory module to obtain a sparse feature representation in both normality and abnormality space. As a result, DREAM not only solves the data imbalance problem but also learn a reasonable feature space. Further theoretical analysis shows that our DREAM also works for the unknown anomalies. Comparing with the previous methods on UCSD Ped1, UCSD Ped2, CUHK Avenue, and ShanghaiTech, our model outperforms all the baselines with no extra parameters. The ablation study demonstrates the effectiveness of our dual memory module and discriminative-generative network.