 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image
Mar 18, 2024
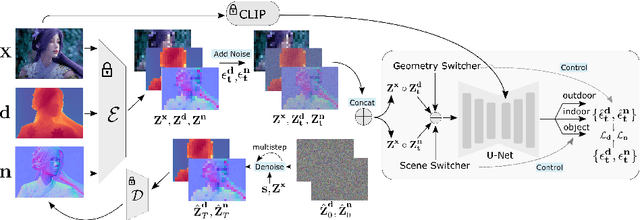


We introduce GeoWizard, a new generative foundation model designed for estimating geometric attributes, e.g., depth and normals, from single images. While significant research has already been conducted in this area, the progress has been substantially limited by the low diversity and poor quality of publicly available datasets. As a result, the prior works either are constrained to limited scenarios or suffer from the inability to capture geometric details. In this paper, we demonstrate that generative models, as opposed to traditional discriminative models (e.g., CNNs and Transformers), can effectively address the inherently ill-posed problem. We further show that leveraging diffusion priors can markedly improve generalization, detail preservation, and efficiency in resource usage. Specifically, we extend the original stable diffusion model to jointly predict depth and normal, allowing mutual information exchange and high consistency between the two representations. More importantly, we propose a simple yet effective strategy to segregate the complex data distribution of various scenes into distinct sub-distributions. This strategy enables our model to recognize different scene layouts, capturing 3D geometry with remarkable fidelity. GeoWizard sets new benchmarks for zero-shot depth and normal prediction, significantly enhancing many downstream applications such as 3D reconstruction, 2D content creation, and novel viewpoint synthesis.
Online Convolutional Re-parameterization
Apr 02, 2022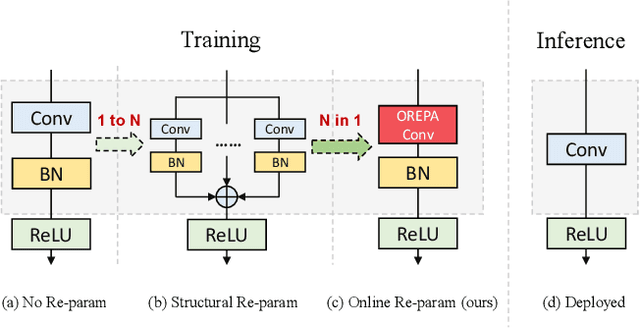
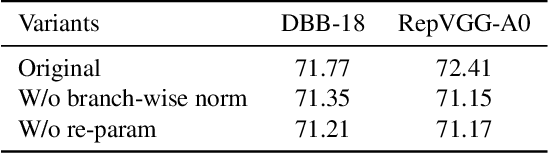
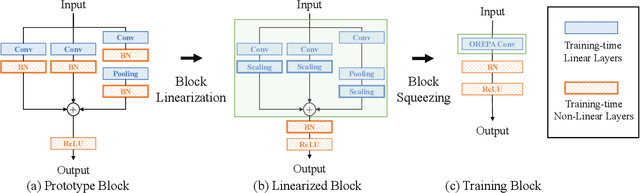
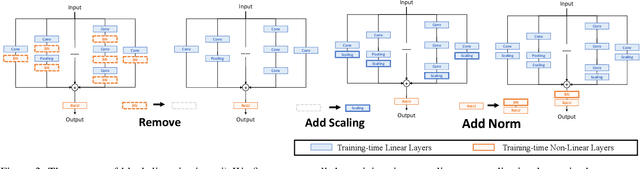
Structural re-parameterization has drawn increasing attention in various computer vision tasks. It aims at improving the performance of deep models without introducing any inference-time cost. Though efficient during inference, such models rely heavily on the complicated training-time blocks to achieve high accuracy, leading to large extra training cost. In this paper, we present online convolutional re-parameterization (OREPA), a two-stage pipeline, aiming to reduce the huge training overhead by squeezing the complex training-time block into a single convolution. To achieve this goal, we introduce a linear scaling layer for better optimizing the online blocks. Assisted with the reduced training cost, we also explore some more effective re-param components. Compared with the state-of-the-art re-param models, OREPA is able to save the training-time memory cost by about 70% and accelerate the training speed by around 2x. Meanwhile, equipped with OREPA, the models outperform previous methods on ImageNet by up to +0.6%.We also conduct experiments on object detection and semantic segmentation and show consistent improvements on the downstream tasks. Codes are available at https://github.com/JUGGHM/OREPA_CVPR2022 .
An Attention-Aided Deep Learning Framework for Massive MIMO Channel Estimation
Aug 21, 2021

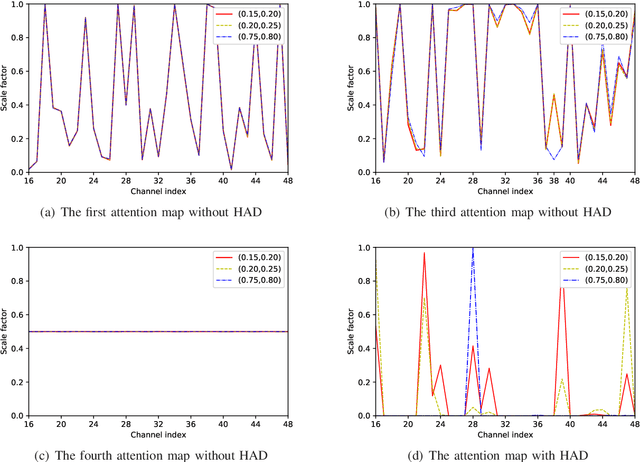
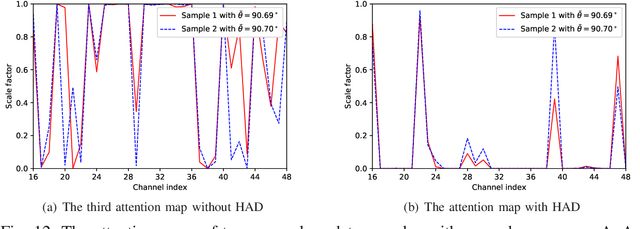
Channel estimation is one of the key issues in practical massive multiple-input multiple-output (MIMO) systems. Compared with conventional estimation algorithms, deep learning (DL) based ones have exhibited great potential in terms of performance and complexity. In this paper, an attention mechanism, exploiting the channel distribution characteristics, is proposed to improve the estimation accuracy of highly separable channels with narrow angular spread by realizing the "divide-and-conquer" policy. Specifically, we introduce a novel attention-aided DL channel estimation framework for conventional massive MIMO systems and devise an embedding method to effectively integrate the attention mechanism into the fully connected neural network for the hybrid analog-digital (HAD) architecture. Simulation results show that in both scenarios, the channel estimation performance is significantly improved with the aid of attention at the cost of small complexity overhead. Furthermore, strong robustness under different system and channel parameters can be achieved by the proposed approach, which further strengthens its practical value. We also investigate the distributions of learned attention maps to reveal the role of attention, which endows the proposed approach with a certain degree of interpretability.
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 18, 2021
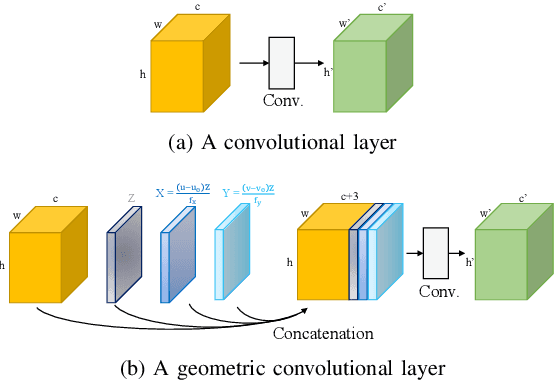

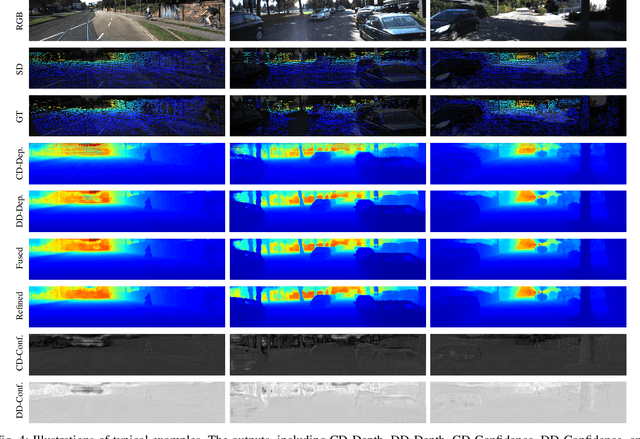
Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work is available at https://github.com/JUGGHM/PENet_ICRA2021.
Self-supervised Visual-LiDAR Odometry with Flip Consistency
Jan 05, 2021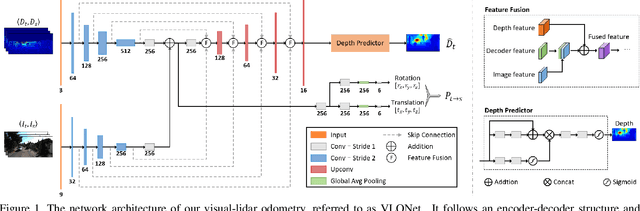



Most learning-based methods estimate ego-motion by utilizing visual sensors, which suffer from dramatic lighting variations and textureless scenarios. In this paper, we incorporate sparse but accurate depth measurements obtained from lidars to overcome the limitation of visual methods. To this end, we design a self-supervised visual-lidar odometry (Self-VLO) framework. It takes both monocular images and sparse depth maps projected from 3D lidar points as input, and produces pose and depth estimations in an end-to-end learning manner, without using any ground truth labels. To effectively fuse two modalities, we design a two-pathway encoder to extract features from visual and depth images and fuse the encoded features with those in decoders at multiple scales by our fusion module. We also adopt a siamese architecture and design an adaptively weighted flip consistency loss to facilitate the self-supervised learning of our VLO. Experiments on the KITTI odometry benchmark show that the proposed approach outperforms all self-supervised visual or lidar odometries. It also performs better than fully supervised VOs, demonstrating the power of fusion.