 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Aware Bias Mitigation and Invariance Learning for Unsupervised Visible-Infrared Person Re-Identification
Dec 08, 2025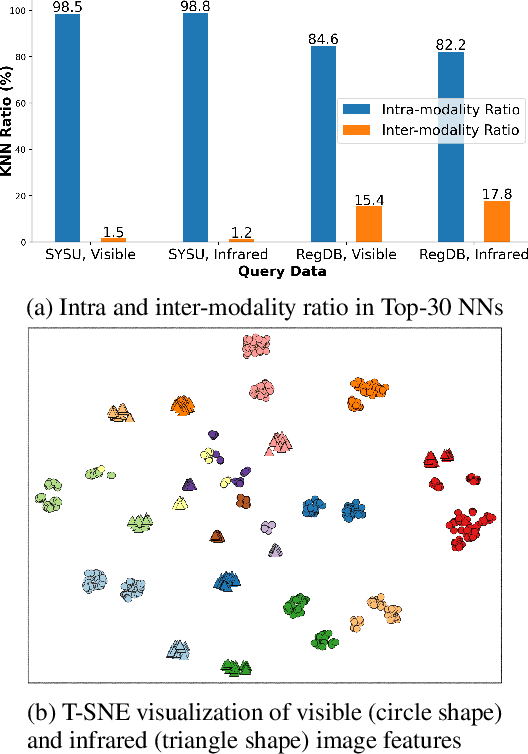
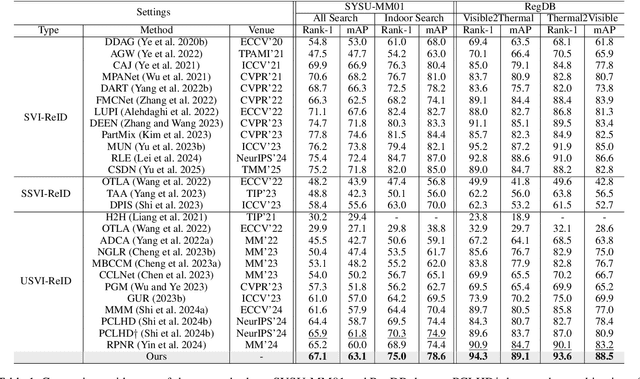
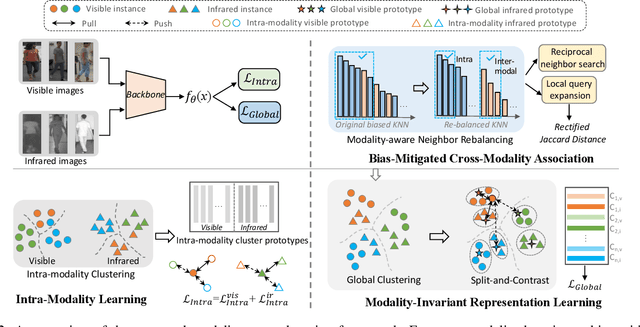
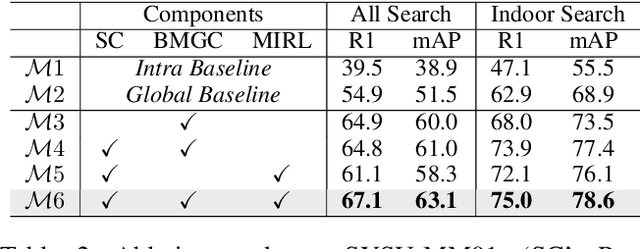
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match individuals across visible and infrared cameras without relying on any annotation. Given the significant gap across visible and infrared modality, estimating reliable cross-modality association becomes a major challenge in USVI-ReID. Existing methods usually adopt optimal transport to associate the intra-modality clusters, which is prone to propagating the local cluster errors, and also overlooks global instance-level relations. By mining and attending to the visible-infrared modality bias, this paper focuses on addressing cross-modality learning from two aspects: bias-mitigated global association and modality-invariant representation learning. Motivated by the camera-aware distance rectification in single-modality re-ID, we propose modality-aware Jaccard distance to mitigate the distance bias caused by modality discrepancy, so that more reliable cross-modality associations can be estimated through global clustering. To further improve cross-modality representation learning, a `split-and-contrast' strategy is designed to obtain modality-specific global prototypes. By explicitly aligning these prototypes under global association guidance, modality-invariant yet ID-discriminative representation learning can be achieved. While conceptually simple, our method obtains state-of-the-art performance on benchmark VI-ReID datasets and outperforms existing methods by a significant margin, validating its effectiveness.
Prior-Constrained Association Learning for Fine-Grained Generalized Category Discovery
Feb 13, 2025



This paper addresses generalized category discovery (GCD), the task of clustering unlabeled data from potentially known or unknown categories with the help of labeled instances from each known category. Compared to traditional semi-supervised learning, GCD is more challenging because unlabeled data could be from novel categories not appearing in labeled data. Current state-of-the-art methods typically learn a parametric classifier assisted by self-distillation. While being effective, these methods do not make use of cross-instance similarity to discover class-specific semantics which are essential for representation learning and category discovery. In this paper, we revisit the association-based paradigm and propose a Prior-constrained Association Learning method to capture and learn the semantic relations within data. In particular, the labeled data from known categories provides a unique prior for the association of unlabeled data. Unlike previous methods that only adopts the prior as a pre or post-clustering refinement, we fully incorporate the prior into the association process, and let it constrain the association towards a reliable grouping outcome. The estimated semantic groups are utilized through non-parametric prototypical contrast to enhance the representation learning. A further combination of both parametric and non-parametric classification complements each other and leads to a model that outperforms existing methods by a significant margin. On multiple GCD benchmarks, we perform extensive experiments and validate the effectiveness of our proposed method.
Unleashing the Potential of Pre-Trained Diffusion Models for Generalizable Person Re-Identification
Feb 10, 2025



Domain-generalizable re-identification (DG Re-ID) aims to train a model on one or more source domains and evaluate its performance on unseen target domains, a task that has attracted growing attention due to its practical relevance. While numerous methods have been proposed, most rely on discriminative or contrastive learning frameworks to learn generalizable feature representations. However, these approaches often fail to mitigate shortcut learning, leading to suboptimal performance. In this work, we propose a novel method called diffusion model-assisted representation learning with a correlation-aware conditioning scheme (DCAC) to enhance DG Re-ID. Our method integrates a discriminative and contrastive Re-ID model with a pre-trained diffusion model through a correlation-aware conditioning scheme. By incorporating ID classification probabilities generated from the Re-ID model with a set of learnable ID-wise prompts, the conditioning scheme injects dark knowledge that captures ID correlations to guide the diffusion process. Simultaneously, feedback from the diffusion model is back-propagated through the conditioning scheme to the Re-ID model, effectively improving the generalization capability of Re-ID features. Extensive experiments on both single-source and multi-source DG Re-ID tasks demonstrate that our method achieves state-of-the-art performance. Comprehensive ablation studies further validate the effectiveness of the proposed approach, providing insights into its robustness. Codes will be available at https://github.com/RikoLi/DCAC.
Tuning-free Universally-Supervised Semantic Segmentation
May 23, 2024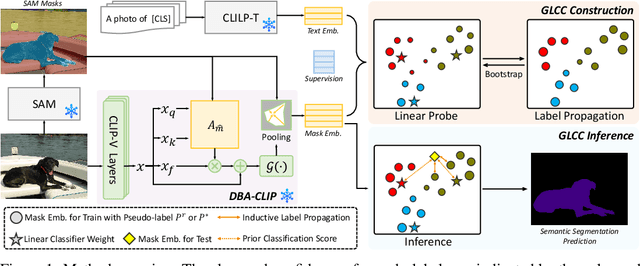
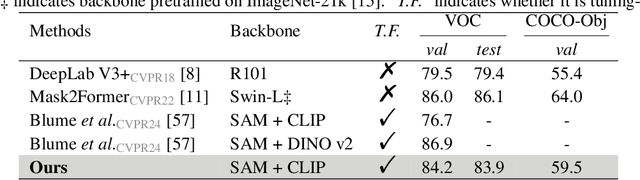
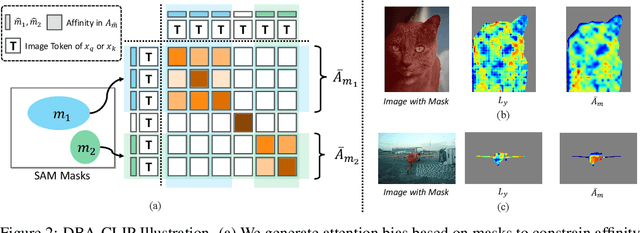
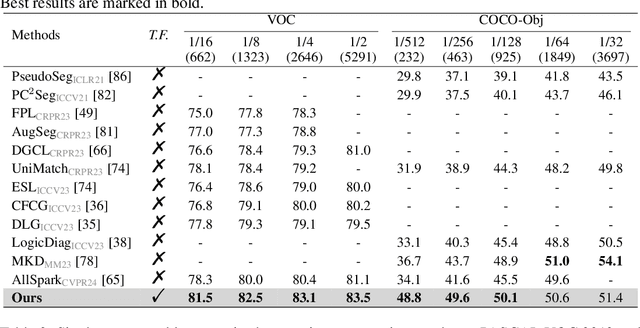
This work presents a tuning-free semantic segmentation framework based on classifying SAM masks by CLIP, which is universally applicable to various types of supervision. Initially, we utilize CLIP's zero-shot classification ability to generate pseudo-labels or perform open-vocabulary segmentation. However, the misalignment between mask and CLIP text embeddings leads to suboptimal results. To address this issue, we propose discrimination-bias aligned CLIP to closely align mask and text embedding, offering an overhead-free performance gain. We then construct a global-local consistent classifier to classify SAM masks, which reveals the intrinsic structure of high-quality embeddings produced by DBA-CLIP and demonstrates robustness against noisy pseudo-labels. Extensive experiments validate the efficiency and effectiveness of our method, and we achieve state-of-the-art (SOTA) or competitive performance across various datasets and supervision types.
Multi-scale Bottleneck Transformer for Weakly Supervised Multimodal Violence Detection
May 08, 2024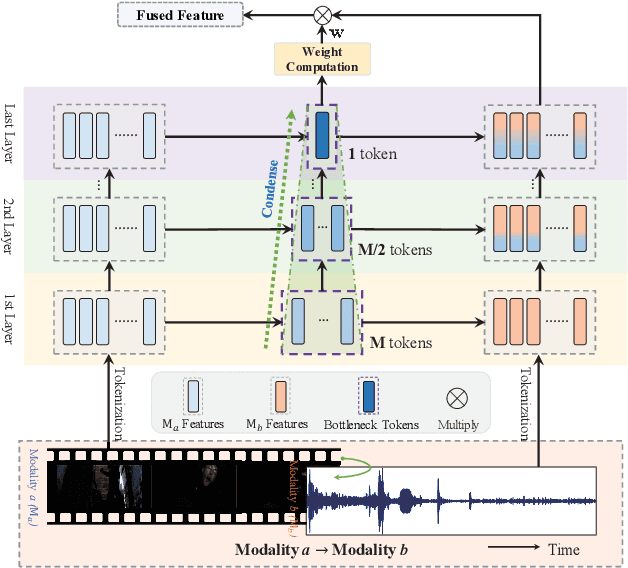
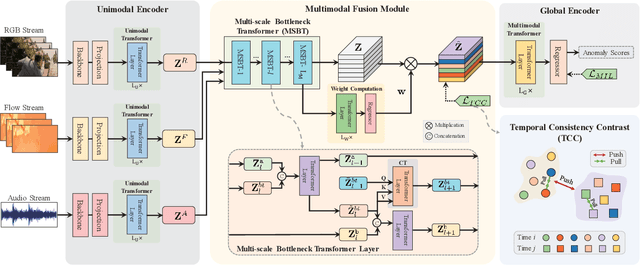

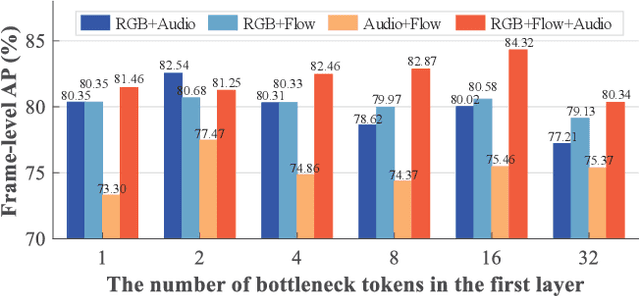
Weakly supervised multimodal violence detection aims to learn a violence detection model by leveraging multiple modalities such as RGB, optical flow, and audio, while only video-level annotations are available. In the pursuit of effective multimodal violence detection (MVD), information redundancy, modality imbalance, and modality asynchrony are identified as three key challenges. In this work, we propose a new weakly supervised MVD method that explicitly addresses these challenges. Specifically, we introduce a multi-scale bottleneck transformer (MSBT) based fusion module that employs a reduced number of bottleneck tokens to gradually condense information and fuse each pair of modalities and utilizes a bottleneck token-based weighting scheme to highlight more important fused features. Furthermore, we propose a temporal consistency contrast loss to semantically align pairwise fused features. Experiments on the largest-scale XD-Violence dataset demonstrate that the proposed method achieves state-of-the-art performance. Code is available at https://github.com/shengyangsun/MSBT.
Foundation Model Assisted Weakly Supervised Semantic Segmentation
Dec 10, 2023This work aims to leverage pre-trained foundation models, such as contrastive language-image pre-training (CLIP) and segment anything model (SAM), to address weakly supervised semantic segmentation (WSSS) using image-level labels. To this end, we propose a coarse-to-fine framework based on CLIP and SAM for generating high-quality segmentation seeds. Specifically, we construct an image classification task and a seed segmentation task, which are jointly performed by CLIP with frozen weights and two sets of learnable task-specific prompts. A SAM-based seeding (SAMS) module is designed and applied to each task to produce either coarse or fine seed maps. Moreover, we design a multi-label contrastive loss supervised by image-level labels and a CAM activation loss supervised by the generated coarse seed map. These losses are used to learn the prompts, which are the only parts need to be learned in our framework. Once the prompts are learned, we input each image along with the learned segmentation-specific prompts into CLIP and the SAMS module to produce high-quality segmentation seeds. These seeds serve as pseudo labels to train an off-the-shelf segmentation network like other two-stage WSSS methods. Experiments show that our method achieves the state-of-the-art performance on PASCAL VOC 2012 and competitive results on MS COCO 2014. Code is available at https://github.com/HAL-42/FMA-WSSS.git.
Learning Intra and Inter-Camera Invariance for Isolated Camera Supervised Person Re-identification
Nov 02, 2023Supervised person re-identification assumes that a person has images captured under multiple cameras. However when cameras are placed in distance, a person rarely appears in more than one camera. This paper thus studies person re-ID under such isolated camera supervised (ISCS) setting. Instead of trying to generate fake cross-camera features like previous methods, we explore a novel perspective by making efficient use of the variation in training data. Under ISCS setting, a person only has limited images from a single camera, so the camera bias becomes a critical issue confounding ID discrimination. Cross-camera images are prone to being recognized as different IDs simply by camera style. To eliminate the confounding effect of camera bias, we propose to learn both intra- and inter-camera invariance under a unified framework. First, we construct style-consistent environments via clustering, and perform prototypical contrastive learning within each environment. Meanwhile, strongly augmented images are contrasted with original prototypes to enforce intra-camera augmentation invariance. For inter-camera invariance, we further design a much improved variant of multi-camera negative loss that optimizes the distance of multi-level negatives. The resulting model learns to be invariant to both subtle and severe style variation within and cross-camera. On multiple benchmarks, we conduct extensive experiments and validate the effectiveness and superiority of the proposed method. Code will be available at https://github.com/Terminator8758/IICI.
Prototypical Contrastive Learning-based CLIP Fine-tuning for Object Re-identification
Oct 26, 2023This work aims to adapt large-scale pre-trained vision-language models, such as contrastive language-image pretraining (CLIP), to enhance the performance of object reidentification (Re-ID) across various supervision settings. Although prompt learning has enabled a recent work named CLIP-ReID to achieve promising performance, the underlying mechanisms and the necessity of prompt learning remain unclear due to the absence of semantic labels in ReID tasks. In this work, we first analyze the role prompt learning in CLIP-ReID and identify its limitations. Based on our investigations, we propose a simple yet effective approach to adapt CLIP for supervised object Re-ID. Our approach directly fine-tunes the image encoder of CLIP using a prototypical contrastive learning (PCL) loss, eliminating the need for prompt learning. Experimental results on both person and vehicle Re-ID datasets demonstrate the competitiveness of our method compared to CLIP-ReID. Furthermore, we extend our PCL-based CLIP fine-tuning approach to unsupervised scenarios, where we achieve state-of-the art performance.
Long-Short Temporal Co-Teaching for Weakly Supervised Video Anomaly Detection
Apr 04, 2023Weakly supervised video anomaly detection (WS-VAD) is a challenging problem that aims to learn VAD models only with video-level annotations. In this work, we propose a Long-Short Temporal Co-teaching (LSTC) method to address the WS-VAD problem. It constructs two tubelet-based spatio-temporal transformer networks to learn from short- and long-term video clips respectively. Each network is trained with respect to a multiple instance learning (MIL)-based ranking loss, together with a cross-entropy loss when clip-level pseudo labels are available. A co-teaching strategy is adopted to train the two networks. That is, clip-level pseudo labels generated from each network are used to supervise the other one at the next training round, and the two networks are learned alternatively and iteratively. Our proposed method is able to better deal with the anomalies with varying durations as well as subtle anomalies. Extensive experiments on three public datasets demonstrate that our method outperforms state-of-the-art WS-VAD methods.
Hierarchical Semantic Contrast for Scene-aware Video Anomaly Detection
Mar 23, 2023Increasing scene-awareness is a key challenge in video anomaly detection (VAD). In this work, we propose a hierarchical semantic contrast (HSC) method to learn a scene-aware VAD model from normal videos. We first incorporate foreground object and background scene features with high-level semantics by taking advantage of pre-trained video parsing models. Then, building upon the autoencoder-based reconstruction framework, we introduce both scene-level and object-level contrastive learning to enforce the encoded latent features to be compact within the same semantic classes while being separable across different classes. This hierarchical semantic contrast strategy helps to deal with the diversity of normal patterns and also increases their discrimination ability. Moreover, for the sake of tackling rare normal activities, we design a skeleton-based motion augmentation to increase samples and refine the model further. Extensive experiments on three public datasets and scene-dependent mixture datasets validate the effectiveness of our proposed method.