 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Aware Bias Mitigation and Invariance Learning for Unsupervised Visible-Infrared Person Re-Identification
Dec 08, 2025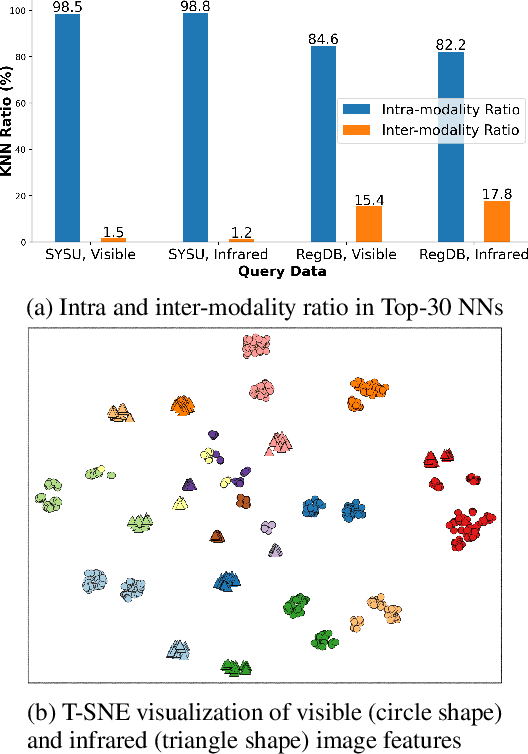
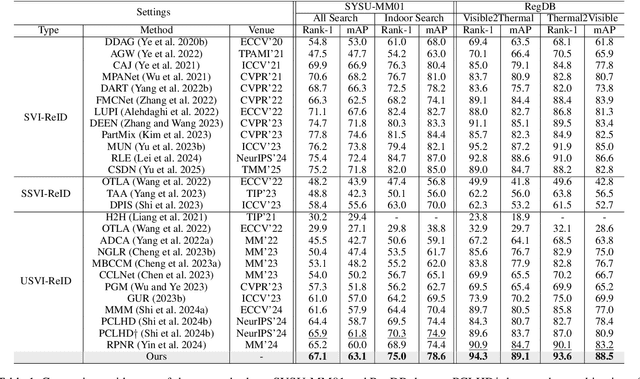
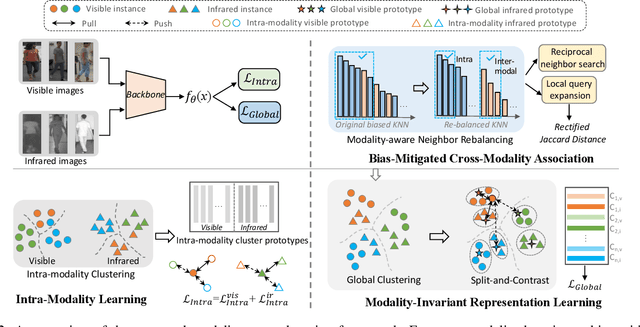
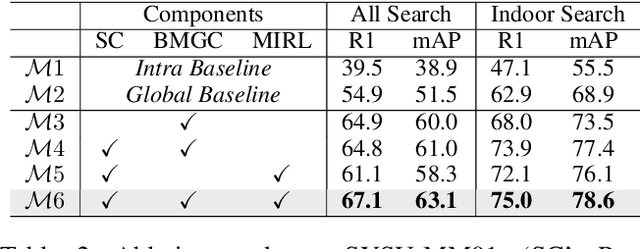
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match individuals across visible and infrared cameras without relying on any annotation. Given the significant gap across visible and infrared modality, estimating reliable cross-modality association becomes a major challenge in USVI-ReID. Existing methods usually adopt optimal transport to associate the intra-modality clusters, which is prone to propagating the local cluster errors, and also overlooks global instance-level relations. By mining and attending to the visible-infrared modality bias, this paper focuses on addressing cross-modality learning from two aspects: bias-mitigated global association and modality-invariant representation learning. Motivated by the camera-aware distance rectification in single-modality re-ID, we propose modality-aware Jaccard distance to mitigate the distance bias caused by modality discrepancy, so that more reliable cross-modality associations can be estimated through global clustering. To further improve cross-modality representation learning, a `split-and-contrast' strategy is designed to obtain modality-specific global prototypes. By explicitly aligning these prototypes under global association guidance, modality-invariant yet ID-discriminative representation learning can be achieved. While conceptually simple, our method obtains state-of-the-art performance on benchmark VI-ReID datasets and outperforms existing methods by a significant margin, validating its effectiveness.
Prior-Constrained Association Learning for Fine-Grained Generalized Category Discovery
Feb 13, 2025



This paper addresses generalized category discovery (GCD), the task of clustering unlabeled data from potentially known or unknown categories with the help of labeled instances from each known category. Compared to traditional semi-supervised learning, GCD is more challenging because unlabeled data could be from novel categories not appearing in labeled data. Current state-of-the-art methods typically learn a parametric classifier assisted by self-distillation. While being effective, these methods do not make use of cross-instance similarity to discover class-specific semantics which are essential for representation learning and category discovery. In this paper, we revisit the association-based paradigm and propose a Prior-constrained Association Learning method to capture and learn the semantic relations within data. In particular, the labeled data from known categories provides a unique prior for the association of unlabeled data. Unlike previous methods that only adopts the prior as a pre or post-clustering refinement, we fully incorporate the prior into the association process, and let it constrain the association towards a reliable grouping outcome. The estimated semantic groups are utilized through non-parametric prototypical contrast to enhance the representation learning. A further combination of both parametric and non-parametric classification complements each other and leads to a model that outperforms existing methods by a significant margin. On multiple GCD benchmarks, we perform extensive experiments and validate the effectiveness of our proposed method.
Learning Intra and Inter-Camera Invariance for Isolated Camera Supervised Person Re-identification
Nov 02, 2023Supervised person re-identification assumes that a person has images captured under multiple cameras. However when cameras are placed in distance, a person rarely appears in more than one camera. This paper thus studies person re-ID under such isolated camera supervised (ISCS) setting. Instead of trying to generate fake cross-camera features like previous methods, we explore a novel perspective by making efficient use of the variation in training data. Under ISCS setting, a person only has limited images from a single camera, so the camera bias becomes a critical issue confounding ID discrimination. Cross-camera images are prone to being recognized as different IDs simply by camera style. To eliminate the confounding effect of camera bias, we propose to learn both intra- and inter-camera invariance under a unified framework. First, we construct style-consistent environments via clustering, and perform prototypical contrastive learning within each environment. Meanwhile, strongly augmented images are contrasted with original prototypes to enforce intra-camera augmentation invariance. For inter-camera invariance, we further design a much improved variant of multi-camera negative loss that optimizes the distance of multi-level negatives. The resulting model learns to be invariant to both subtle and severe style variation within and cross-camera. On multiple benchmarks, we conduct extensive experiments and validate the effectiveness and superiority of the proposed method. Code will be available at https://github.com/Terminator8758/IICI.
Transformer Based Multi-Grained Features for Unsupervised Person Re-Identification
Nov 22, 2022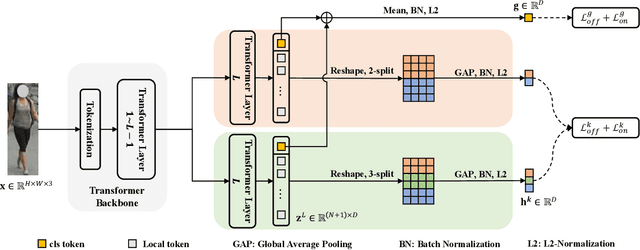


Multi-grained features extracted from convolutional neural networks (CNNs) have demonstrated their strong discrimination ability in supervised person re-identification (Re-ID) tasks. Inspired by them, this work investigates the way of extracting multi-grained features from a pure transformer network to address the unsupervised Re-ID problem that is label-free but much more challenging. To this end, we build a dual-branch network architecture based upon a modified Vision Transformer (ViT). The local tokens output in each branch are reshaped and then uniformly partitioned into multiple stripes to generate part-level features, while the global tokens of two branches are averaged to produce a global feature. Further, based upon offline-online associated camera-aware proxies (O2CAP) that is a top-performing unsupervised Re-ID method, we define offline and online contrastive learning losses with respect to both global and part-level features to conduct unsupervised learning. Extensive experiments on three person Re-ID datasets show that the proposed method outperforms state-of-the-art unsupervised methods by a considerable margin, greatly mitigating the gap to supervised counterparts. Code will be available soon at https://github.com/RikoLi/WACV23-workshop-TMGF.
Offline-Online Associated Camera-Aware Proxies for Unsupervised Person Re-identification
Jan 15, 2022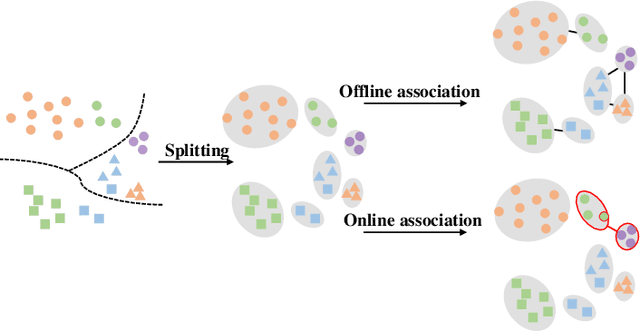
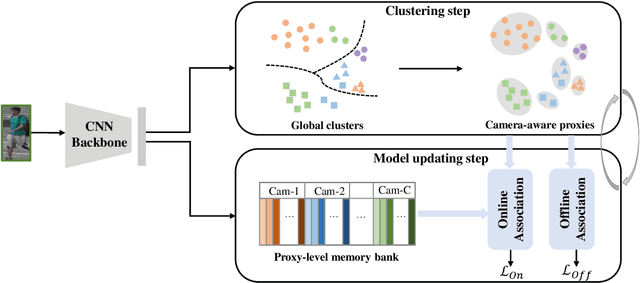
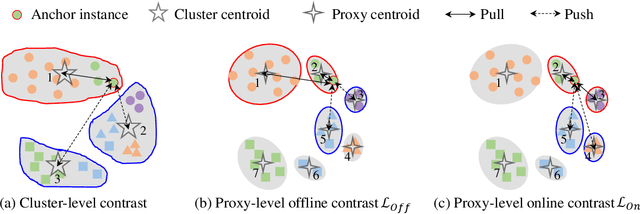
Recently, unsupervised person re-identification (Re-ID) has received increasing research attention due to its potential for label-free applications. A promising way to address unsupervised Re-ID is clustering-based, which generates pseudo labels by clustering and uses the pseudo labels to train a Re-ID model iteratively. However, most clustering-based methods take each cluster as a pseudo identity class, neglecting the intra-cluster variance mainly caused by the change of cameras. To address this issue, we propose to split each single cluster into multiple proxies according to camera views. The camera-aware proxies explicitly capture local structures within clusters, by which the intra-ID variance and inter-ID similarity can be better tackled. Assisted with the camera-aware proxies, we design two proxy-level contrastive learning losses that are, respectively, based on offline and online association results. The offline association directly associates proxies according to the clustering and splitting results, while the online strategy dynamically associates proxies in terms of up-to-date features to reduce the noise caused by the delayed update of pseudo labels. The combination of two losses enable us to train a desirable Re-ID model. Extensive experiments on three person Re-ID datasets and one vehicle Re-ID dataset show that our proposed approach demonstrates competitive performance with state-of-the-art methods. Code will be available at: https://github.com/Terminator8758/O2CAP.
Camera-aware Proxies for Unsupervised Person Re-Identification
Dec 19, 2020
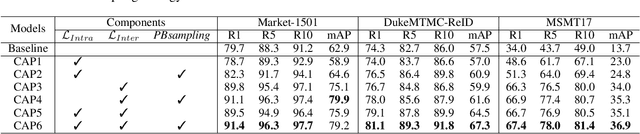
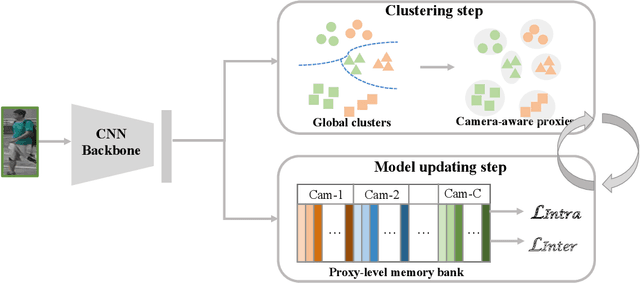
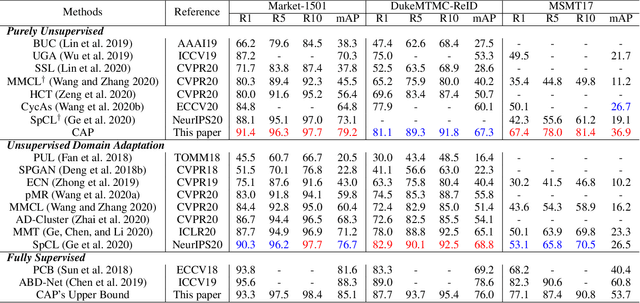
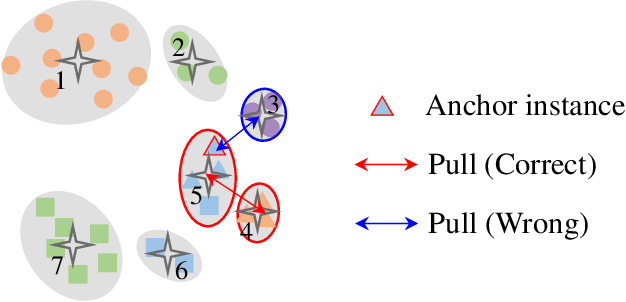
This paper tackles the purely unsupervised person re-identification (Re-ID) problem that requires no annotations. Some previous methods adopt clustering techniques to generate pseudo labels and use the produced labels to train Re-ID models progressively. These methods are relatively simple but effective. However, most clustering-based methods take each cluster as a pseudo identity class, neglecting the large intra-ID variance caused mainly by the change of camera views. To address this issue, we propose to split each single cluster into multiple proxies and each proxy represents the instances coming from the same camera. These camera-aware proxies enable us to deal with large intra-ID variance and generate more reliable pseudo labels for learning. Based on the camera-aware proxies, we design both intra- and inter-camera contrastive learning components for our Re-ID model to effectively learn the ID discrimination ability within and across cameras. Meanwhile, a proxy-balanced sampling strategy is also designed, which facilitates our learning further. Extensive experiments on three large-scale Re-ID datasets show that our proposed approach outperforms most unsupervised methods by a significant margin. Especially, on the challenging MSMT17 dataset, we gain $14.3\%$ Rank-1 and $10.2\%$ mAP improvements when compared to the second place.
The DeepFake Detection Challenge Dataset
Jun 25, 2020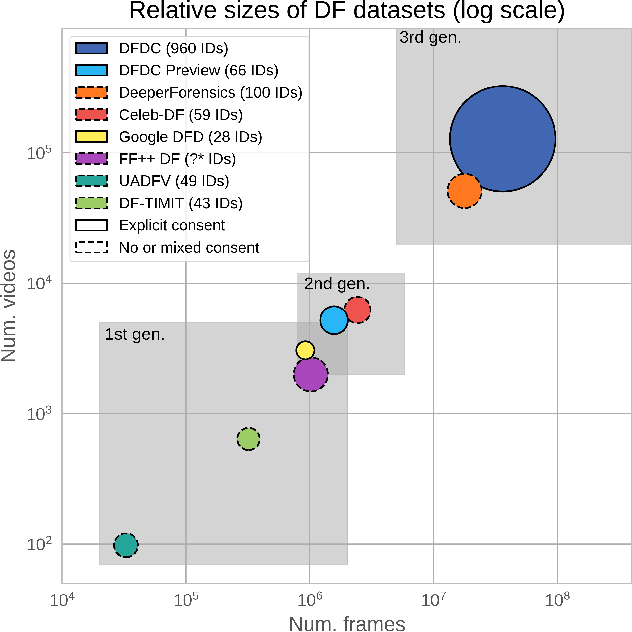
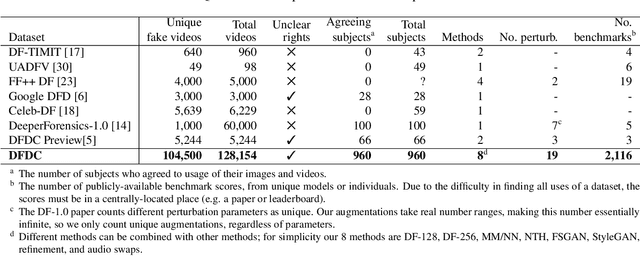

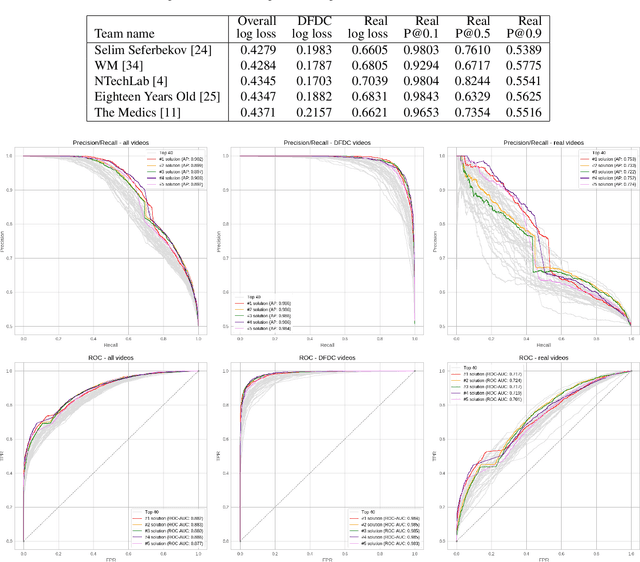
Deepfakes are a recent off-the-shelf manipulation technique that allows anyone to swap two identities in a single video. In addition to Deepfakes, a variety of GAN-based face swapping methods have also been published with accompanying code. To counter this emerging threat, we have constructed an extremely large face swap video dataset to enable the training of detection models, and organized the accompanying DeepFake Detection Challenge (DFDC) Kaggle competition. Importantly, all recorded subjects agreed to participate in and have their likenesses modified during the construction of the face-swapped dataset. The DFDC dataset is by far the largest currently and publicly available face swap video dataset, with over 100,000 total clips sourced from 3,426 paid actors, produced with several Deepfake, GAN-based, and non-learned methods. In addition to describing the methods used to construct the dataset, we provide a detailed analysis of the top submissions from the Kaggle contest. We show although Deepfake detection is extremely difficult and still an unsolved problem, a Deepfake detection model trained only on the DFDC can generalize to real "in-the-wild" Deepfake videos, and such a model can be a valuable analysis tool when analyzing potentially Deepfaked videos. Training, validation and testing corpuses can be downloaded from https://ai.facebook.com/datasets/dfdc.
Towards Precise Intra-camera Supervised Person Re-identification
Feb 12, 2020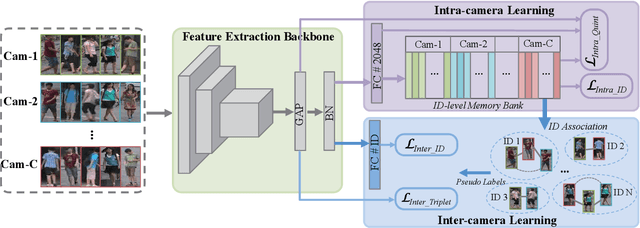

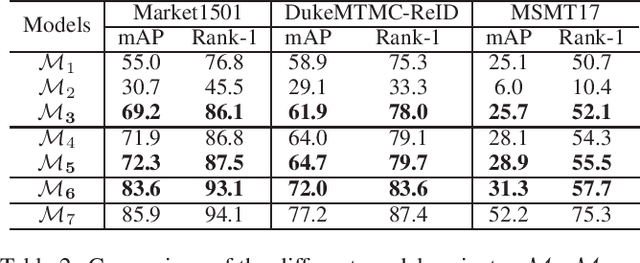
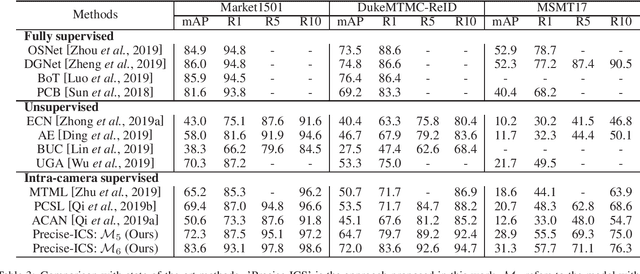
Intra-camera supervision (ICS) for person re-identification (Re-ID) assumes that identity labels are independently annotated within each camera view and no inter-camera identity association is labeled. It is a new setting proposed recently to reduce the burden of annotation while expect to maintain desirable Re-ID performance. However, the lack of inter-camera labels makes the ICS Re-ID problem much more challenging than the fully supervised counterpart. By investigating the characteristics of ICS, this paper proposes camera-specific non-parametric classifiers, together with a hybrid mining quintuplet loss, to perform intra-camera learning. Then, an inter-camera learning module consisting of a graph-based ID association step and a Re-ID model updating step is conducted. Extensive experiments on three large-scale Re-ID datasets show that our approach outperforms all existing ICS works by a great margin. Our approach performs even comparable to state-of-the-art fully supervised methods in two of the datasets.
Deep Active Learning for Video-based Person Re-identification
Dec 14, 2018
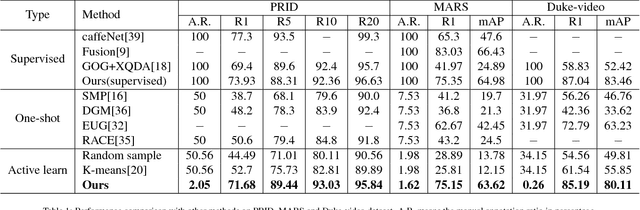
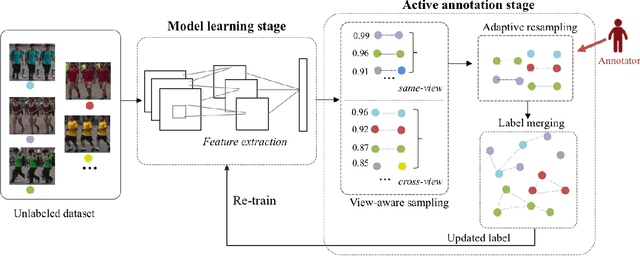
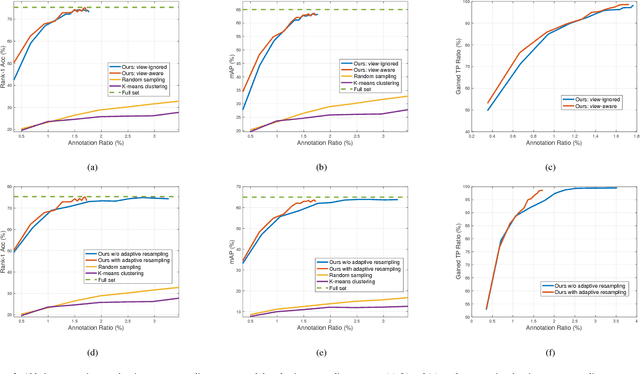
It is prohibitively expensive to annotate a large-scale video-based person re-identification (re-ID) dataset, which makes fully supervised methods inapplicable to real-world deployment. How to maximally reduce the annotation cost while retaining the re-ID performance becomes an interesting problem. In this paper, we address this problem by integrating an active learning scheme into a deep learning framework. Noticing that the truly matched tracklet-pairs, also denoted as true positives (TP), are the most informative samples for our re-ID model, we propose a sampling criterion to choose the most TP-likely tracklet-pairs for annotation. A view-aware sampling strategy considering view-specific biases is designed to facilitate candidate selection, followed by an adaptive resampling step to leave out the selected candidates that are unnecessary to annotate. Our method learns the re-ID model and updates the annotation set iteratively. The re-ID model is supervised by the tracklets' pesudo labels that are initialized by treating each tracklet as a distinct class. With the gained annotations of the actively selected candidates, the tracklets' pesudo labels are updated by label merging and further used to re-train our re-ID model. While being simple, the proposed method demonstrates its effectiveness on three video-based person re-ID datasets. Experimental results show that less than 3\% pairwise annotations are needed for our method to reach comparable performance with the fully-supervised setting.
Dynamic Spatio-temporal Graph-based CNNs for Traffic Prediction
Dec 06, 2018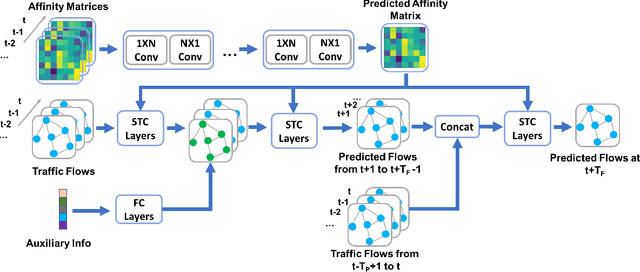
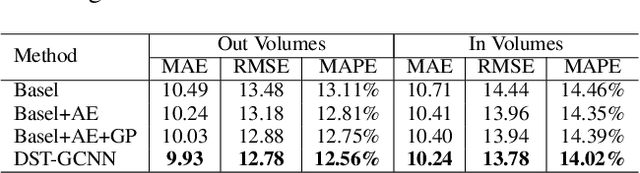
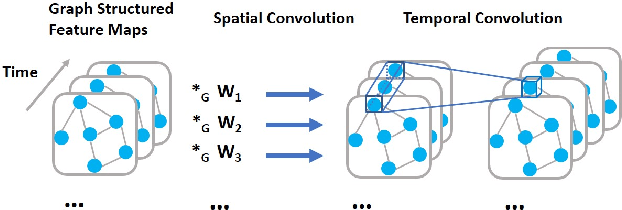
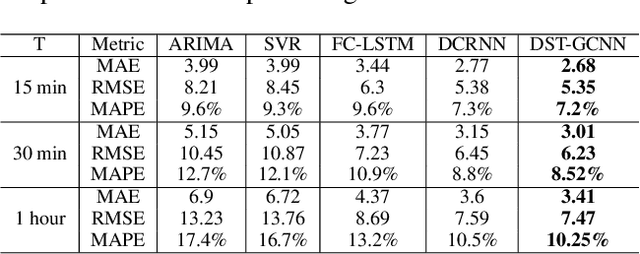
Accurate traffic forecast is a challenging problem due to the large-scale problem size, as well as the complex and dynamic nature of spatio-temporal dependency of traffic flow. Most existing graph-based CNNs attempt to capture the static relations while largely neglecting the dynamics underlying sequential data. In this paper, we present dynamic spatio-temporal graph-based CNNs (DST-GCNNs) by learning expressive features to represent spatio-temporal structures and predict future traffic from historical traffic flow. In particular, DST-GCNN is a two stream network. In the flow prediction stream, we present a novel graph-based spatio-temporal convolutional layer to extract features from a graph representation of traffic flow. Then several such layers are stacked together to predict future traffic over time. Meanwhile, the proximity relations between nodes in the graph are often time variant as the traffic condition changes over time. To capture the graph dynamics, we use the graph prediction stream to predict the dynamic graph structures, and the predicted structures are fed into the flow prediction stream. Experiments on real traffic datasets demonstrate that the proposed model achieves competitive performances compared with the other state-of-the-art methods.