 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning for Video-based Person Re-identification
Paper and Code
Dec 14, 2018
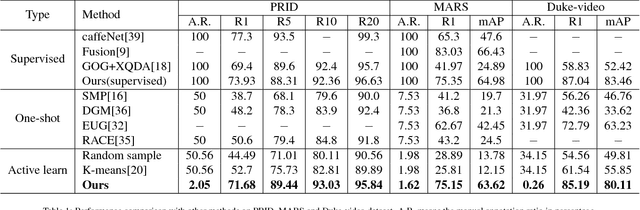
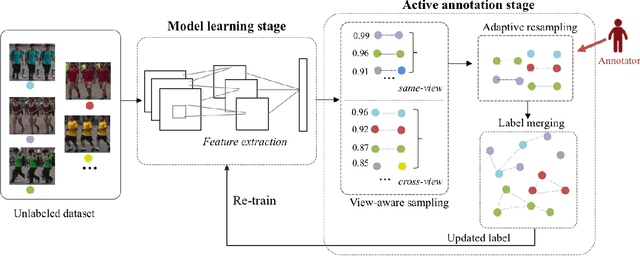
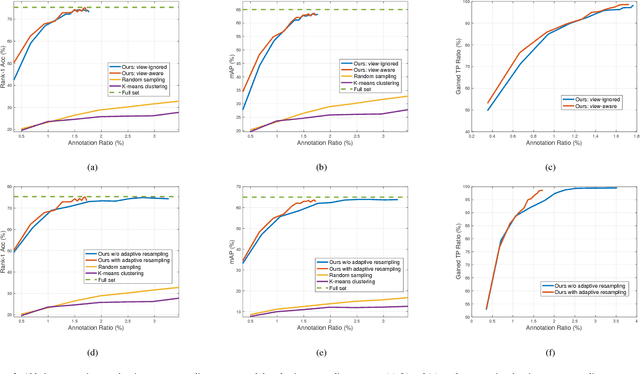
It is prohibitively expensive to annotate a large-scale video-based person re-identification (re-ID) dataset, which makes fully supervised methods inapplicable to real-world deployment. How to maximally reduce the annotation cost while retaining the re-ID performance becomes an interesting problem. In this paper, we address this problem by integrating an active learning scheme into a deep learning framework. Noticing that the truly matched tracklet-pairs, also denoted as true positives (TP), are the most informative samples for our re-ID model, we propose a sampling criterion to choose the most TP-likely tracklet-pairs for annotation. A view-aware sampling strategy considering view-specific biases is designed to facilitate candidate selection, followed by an adaptive resampling step to leave out the selected candidates that are unnecessary to annotate. Our method learns the re-ID model and updates the annotation set iteratively. The re-ID model is supervised by the tracklets' pesudo labels that are initialized by treating each tracklet as a distinct class. With the gained annotations of the actively selected candidates, the tracklets' pesudo labels are updated by label merging and further used to re-train our re-ID model. While being simple, the proposed method demonstrates its effectiveness on three video-based person re-ID datasets. Experimental results show that less than 3\% pairwise annotations are needed for our method to reach comparable performance with the fully-supervised setting.