 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSqueeze: Performance-Preserving Compression for Reasoning LLMs
Nov 17, 2025Emerging reasoning LLMs such as OpenAI-o1 and DeepSeek-R1 have achieved strong performance on complex reasoning tasks by generating long chain-of-thought (CoT) traces. However, these long CoTs result in increased token usage, leading to higher inference latency and memory consumption. As a result, balancing accuracy and reasoning efficiency has become essential for deploying reasoning LLMs in practical applications. Existing long-to-short (Long2Short) methods aim to reduce inference length but often sacrifice accuracy, revealing a need for an approach that maintains performance while lowering token costs. To address this efficiency-accuracy tradeoff, we propose TokenSqueeze, a novel Long2Short method that condenses reasoning paths while preserving performance and relying exclusively on self-generated data. First, to prevent performance degradation caused by excessive compression of reasoning depth, we propose to select self-generated samples whose reasoning depth is adaptively matched to the complexity of the problem. To further optimize the linguistic expression without altering the underlying reasoning paths, we introduce a distribution-aligned linguistic refinement method that enhances the clarity and conciseness of the reasoning path while preserving its logical integrity. Comprehensive experimental results demonstrate the effectiveness of TokenSqueeze in reducing token usage while maintaining accuracy. Notably, DeepSeek-R1-Distill-Qwen-7B fine-tuned using our proposed method achieved a 50\% average token reduction while preserving accuracy on the MATH500 benchmark. TokenSqueeze exclusively utilizes the model's self-generated data, enabling efficient and high-fidelity reasoning without relying on manually curated short-answer datasets across diverse applications. Our code is available at https://github.com/zhangyx1122/TokenSqueeze.
Enhancing Spatial Reasoning through Visual and Textual Thinking
Jul 28, 2025The spatial reasoning task aims to reason about the spatial relationships in 2D and 3D space, which is a fundamental capability for Visual Question Answering (VQA) and robotics. Although vision language models (VLMs) have developed rapidly in recent years, they are still struggling with the spatial reasoning task. In this paper, we introduce a method that can enhance Spatial reasoning through Visual and Textual thinking Simultaneously (SpatialVTS). In the spatial visual thinking phase, our model is trained to generate location-related specific tokens of essential targets automatically. Not only are the objects mentioned in the problem addressed, but also the potential objects related to the reasoning are considered. During the spatial textual thinking phase, Our model conducts long-term thinking based on visual cues and dialogues, gradually inferring the answers to spatial reasoning problems. To effectively support the model's training, we perform manual corrections to the existing spatial reasoning dataset, eliminating numerous incorrect labels resulting from automatic annotation, restructuring the data input format to enhance generalization ability, and developing thinking processes with logical reasoning details. Without introducing additional information (such as masks or depth), our model's overall average level in several spatial understanding tasks has significantly improved compared with other models.
Plan-on-Graph: Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs
Oct 31, 2024



Large Language Models (LLMs) have shown remarkable reasoning capabilities on complex tasks, but they still suffer from out-of-date knowledge, hallucinations, and opaque decision-making. In contrast, Knowledge Graphs (KGs) can provide explicit and editable knowledge for LLMs to alleviate these issues. Existing paradigm of KG-augmented LLM manually predefines the breadth of exploration space and requires flawless navigation in KGs. However, this paradigm cannot adaptively explore reasoning paths in KGs based on the question semantics and self-correct erroneous reasoning paths, resulting in a bottleneck in efficiency and effect. To address these limitations, we propose a novel self-correcting adaptive planning paradigm for KG-augmented LLM named Plan-on-Graph (PoG), which first decomposes the question into several sub-objectives and then repeats the process of adaptively exploring reasoning paths, updating memory, and reflecting on the need to self-correct erroneous reasoning paths until arriving at the answer. Specifically, three important mechanisms of Guidance, Memory, and Reflection are designed to work together, to guarantee the adaptive breadth of self-correcting planning for graph reasoning. Finally, extensive experiments on three real-world datasets demonstrate the effectiveness and efficiency of PoG.
Discriminative-Generative Dual Memory Video Anomaly Detection
Apr 29, 2021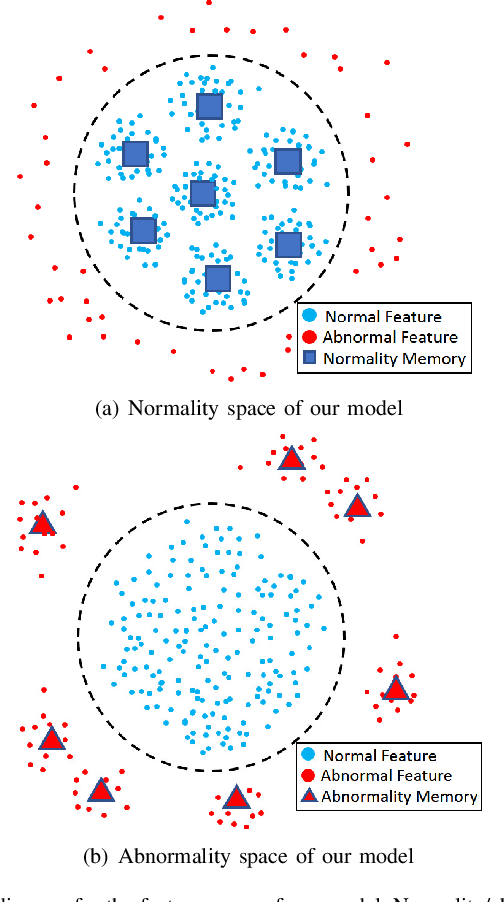
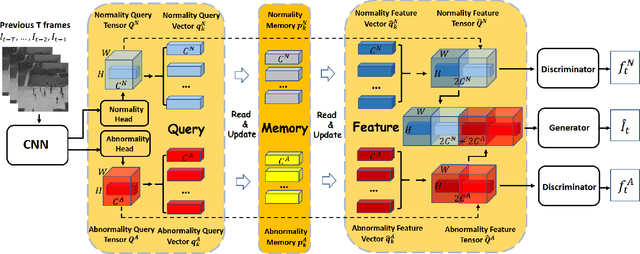
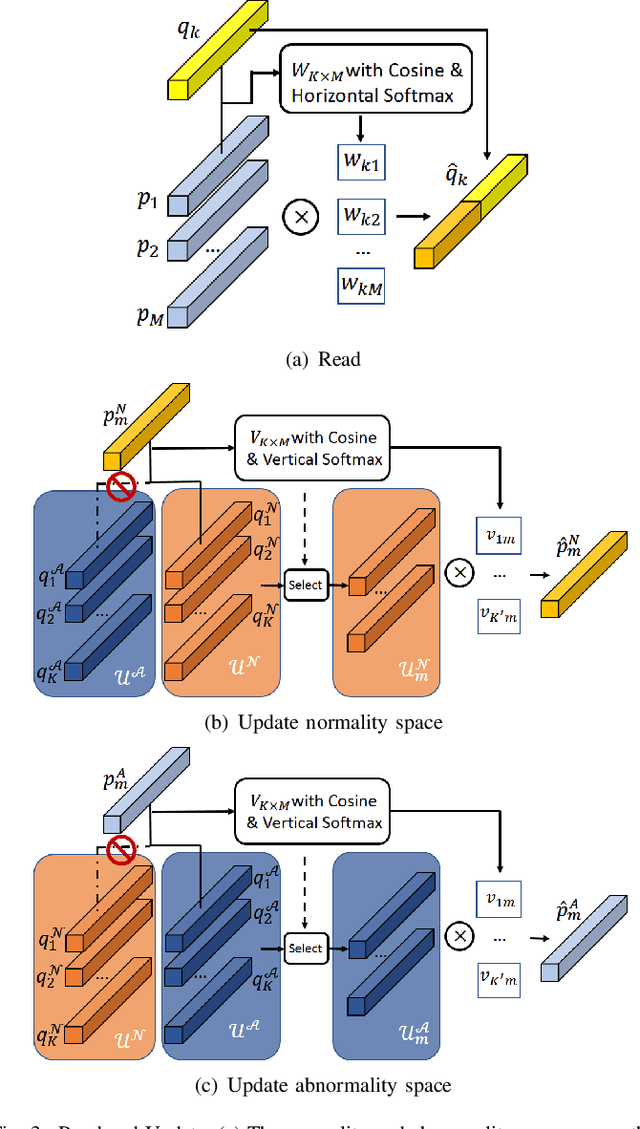
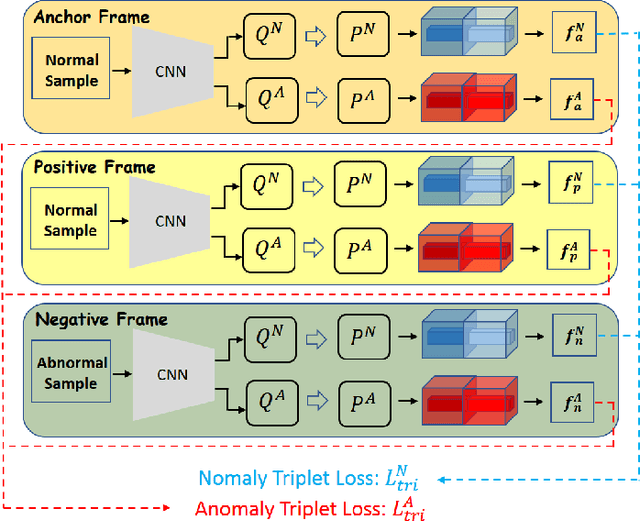
Recently, people tried to use a few anomalies for video anomaly detection (VAD) instead of only normal data during the training process. A side effect of data imbalance occurs when a few abnormal data face a vast number of normal data. The latest VAD works use triplet loss or data re-sampling strategy to lessen this problem. However, there is still no elaborately designed structure for discriminative VAD with a few anomalies. In this paper, we propose a DiscRiminative-gEnerative duAl Memory (DREAM) anomaly detection model to take advantage of a few anomalies and solve data imbalance. We use two shallow discriminators to tighten the normal feature distribution boundary along with a generator for the next frame prediction. Further, we propose a dual memory module to obtain a sparse feature representation in both normality and abnormality space. As a result, DREAM not only solves the data imbalance problem but also learn a reasonable feature space. Further theoretical analysis shows that our DREAM also works for the unknown anomalies. Comparing with the previous methods on UCSD Ped1, UCSD Ped2, CUHK Avenue, and ShanghaiTech, our model outperforms all the baselines with no extra parameters. The ablation study demonstrates the effectiveness of our dual memory module and discriminative-generative network.
PCPL: Predicate-Correlation Perception Learning for Unbiased Scene Graph Generation
Sep 02, 2020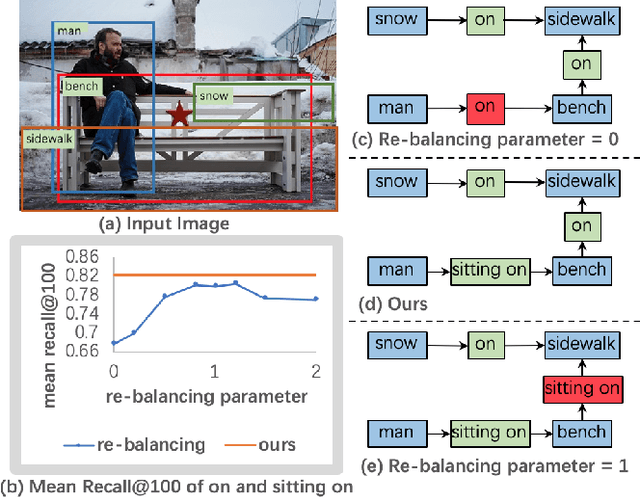
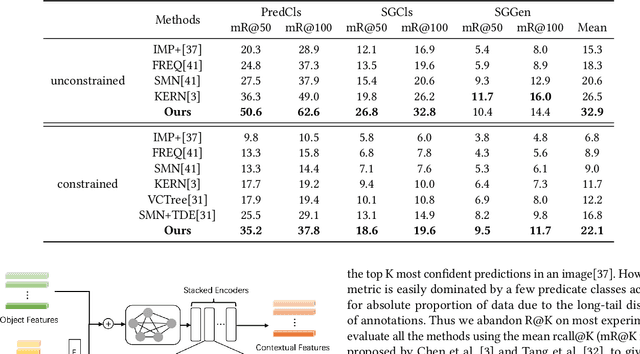
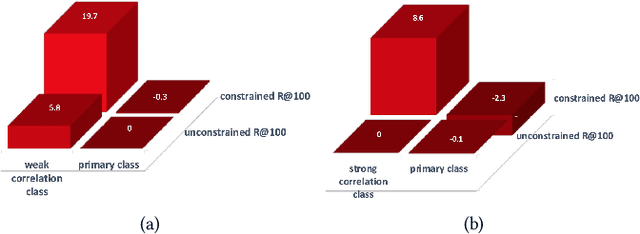
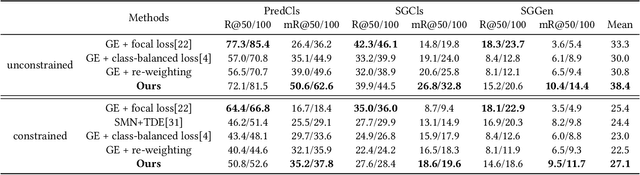
Today, scene graph generation(SGG) task is largely limited in realistic scenarios, mainly due to the extremely long-tailed bias of predicate annotation distribution. Thus, tackling the class imbalance trouble of SGG is critical and challenging. In this paper, we first discover that when predicate labels have strong correlation with each other, prevalent re-balancing strategies(e.g., re-sampling and re-weighting) will give rise to either over-fitting the tail data(e.g., bench sitting on sidewalk rather than on), or still suffering the adverse effect from the original uneven distribution(e.g., aggregating varied parked on/standing on/sitting on into on). We argue the principal reason is that re-balancing strategies are sensitive to the frequencies of predicates yet blind to their relatedness, which may play a more important role to promote the learning of predicate features. Therefore, we propose a novel Predicate-Correlation Perception Learning(PCPL for short) scheme to adaptively seek out appropriate loss weights by directly perceiving and utilizing the correlation among predicate classes. Moreover, our PCPL framework is further equipped with a graph encoder module to better extract context features. Extensive experiments on the benchmark VG150 dataset show that the proposed PCPL performs markedly better on tail classes while well-preserving the performance on head ones, which significantly outperforms previous state-of-the-art methods.
Deep Robust Clustering by Contrastive Learning
Aug 27, 2020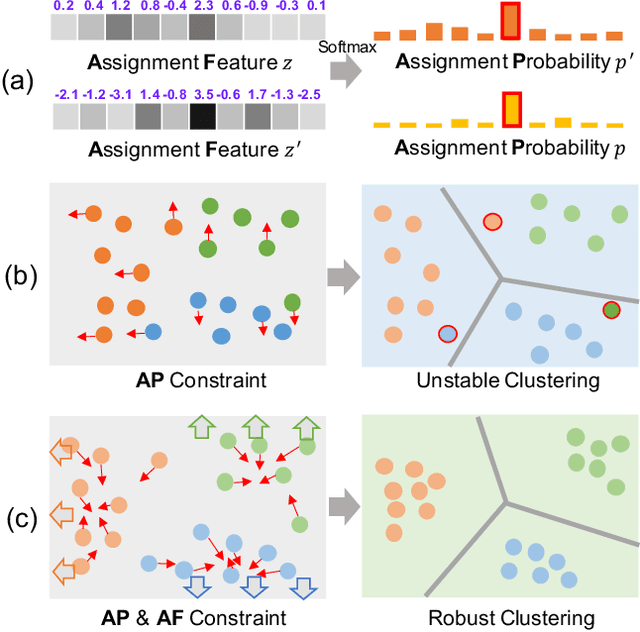
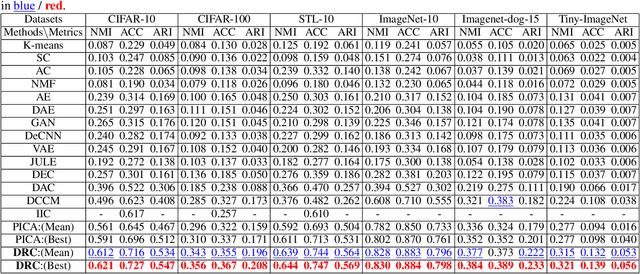
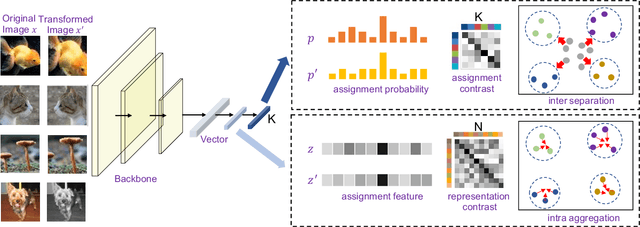

Recently, many unsupervised deep learning methods have been proposed to learn clustering with unlabelled data. By introducing data augmentation, most of the latest methods look into deep clustering from the perspective that the original image and its transformation should share similar semantic clustering assignment. However, the representation features could be quite different even they are assigned to the same cluster since softmax function is only sensitive to the maximum value. This may result in high intra-class diversities in the representation feature space, which will lead to unstable local optimal and thus harm the clustering performance. To address this drawback, we proposed Deep Robust Clustering (DRC). Different from existing methods, DRC looks into deep clustering from two perspectives of both semantic clustering assignment and representation feature, which can increase inter-class diversities and decrease intra-class diversities simultaneously. Furthermore, we summarized a general framework that can turn any maximizing mutual information into minimizing contrastive loss by investigating the internal relationship between mutual information and contrastive learning. And we successfully applied it in DRC to learn invariant features and robust clusters. Extensive experiments on six widely-adopted deep clustering benchmarks demonstrate the superiority of DRC in both stability and accuracy. e.g., attaining 71.6% mean accuracy on CIFAR-10, which is 7.1% higher than state-of-the-art results.
Apparel-invariant Feature Learning for Apparel-changed Person Re-identification
Aug 17, 2020
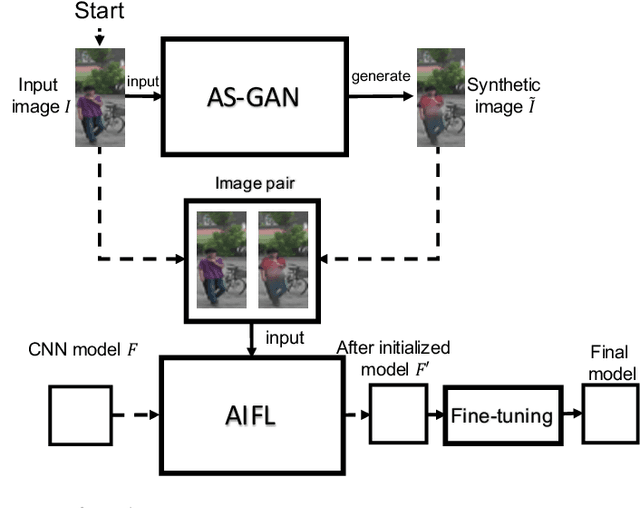
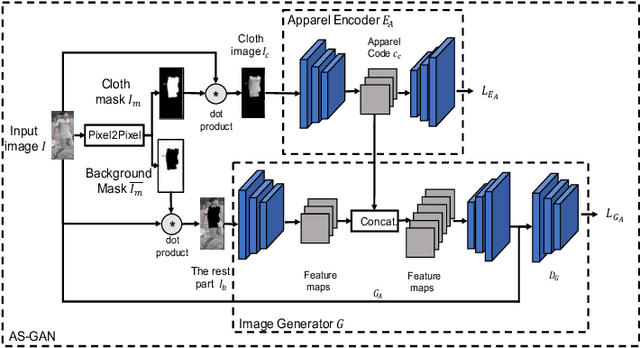

With the rise of deep learning methods, person Re-Identification (ReID) performance has been improved tremendously in many public datasets. However, most public ReID datasets are collected in a short time window in which persons' appearance rarely changes. In real-world applications such as in a shopping mall, the same person's clothing may change, and different persons may wearing similar clothes. All these cases can result in an inconsistent ReID performance, revealing a critical problem that current ReID models heavily rely on person's apparels. Therefore, it is critical to learn an apparel-invariant person representation under cases like cloth changing or several persons wearing similar clothes. In this work, we tackle this problem from the viewpoint of invariant feature representation learning. The main contributions of this work are as follows. (1) We propose the semi-supervised Apparel-invariant Feature Learning (AIFL) framework to learn an apparel-invariant pedestrian representation using images of the same person wearing different clothes. (2) To obtain images of the same person wearing different clothes, we propose an unsupervised apparel-simulation GAN (AS-GAN) to synthesize cloth changing images according to the target cloth embedding. It's worth noting that the images used in ReID tasks were cropped from real-world low-quality CCTV videos, making it more challenging to synthesize cloth changing images. We conduct extensive experiments on several datasets comparing with several baselines. Experimental results demonstrate that our proposal can improve the ReID performance of the baseline models.
Stable Learning via Causality-based Feature Rectification
Jul 30, 2020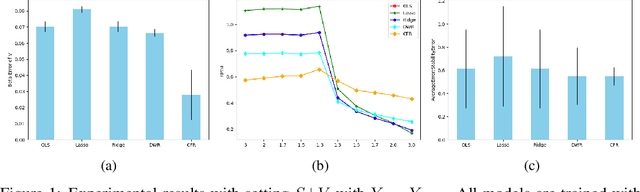
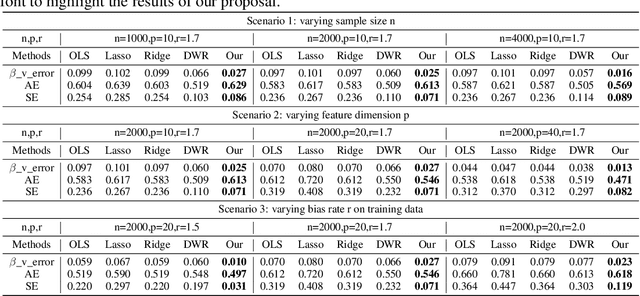
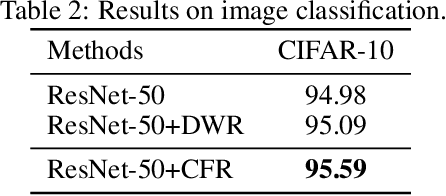
How to learn a stable model under agnostic distribution shift between training and testing datasets is an essential problem in machine learning tasks. The agnostic distribution shift caused by data generation bias can lead to model misspecification and unstable performance across different test datasets. Most of the recently proposed methods are causality-based sample reweighting methods, whose performance is affected by sample size. Moreover, these works are restricted to linear models, not to deep-learning based nonlinear models. In this work, we propose a novel Causality-based Feature Rectification (CFR) method to address the model misspecification problem under agnostic distribution shift by using a weight matrix to rectify features. Our proposal based on the fact that the causality between stable features and the ground truth is consistent under agnostic distribution shift, but is partly omitted and statistically correlated with other features. We propose the feature rectification weight matrix to reconstruct the omitted causality by using other features as proxy variables. We further propose an algorithm that jointly optimizes the weight matrix and the regressor (or classifier). Our proposal can not only improve the stability of linear models, but also deep-learning based models. Extensive experiments on both synthetic and real-world datasets demonstrate that our proposal outperforms previous state-of-the-art stable learning methods. The code will be released later on.
Adversarial Mutual Information for Text Generation
Jun 30, 2020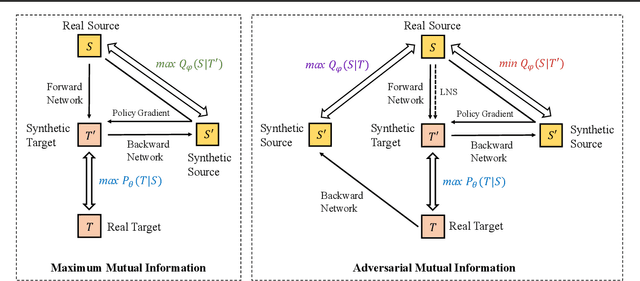
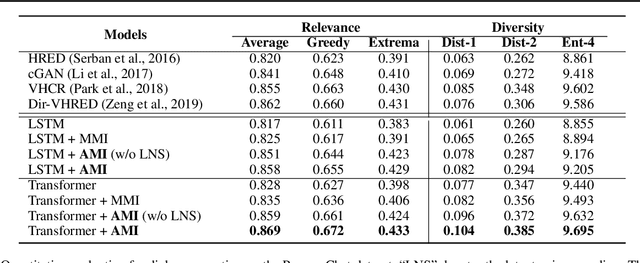

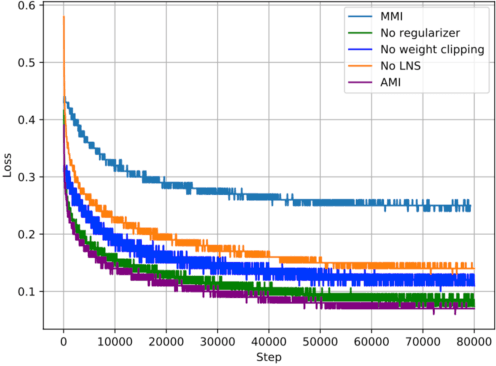
Recent advances in maximizing mutual information (MI) between the source and target have demonstrated its effectiveness in text generation. However, previous works paid little attention to modeling the backward network of MI (i.e., dependency from the target to the source), which is crucial to the tightness of the variational information maximization lower bound. In this paper, we propose Adversarial Mutual Information (AMI): a text generation framework which is formed as a novel saddle point (min-max) optimization aiming to identify joint interactions between the source and target. Within this framework, the forward and backward networks are able to iteratively promote or demote each other's generated instances by comparing the real and synthetic data distributions. We also develop a latent noise sampling strategy that leverages random variations at the high-level semantic space to enhance the long term dependency in the generation process. Extensive experiments based on different text generation tasks demonstrate that the proposed AMI framework can significantly outperform several strong baselines, and we also show that AMI has potential to lead to a tighter lower bound of maximum mutual information for the variational information maximization problem.
A Fast Sampling Gradient Tree Boosting Framework
Nov 20, 2019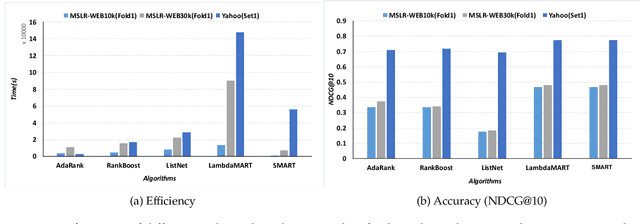
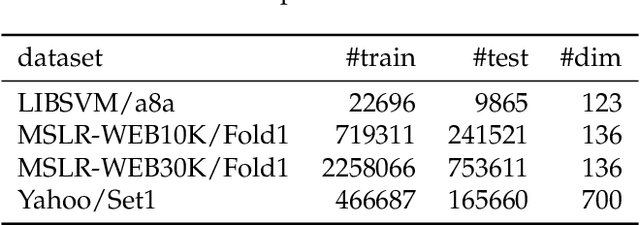
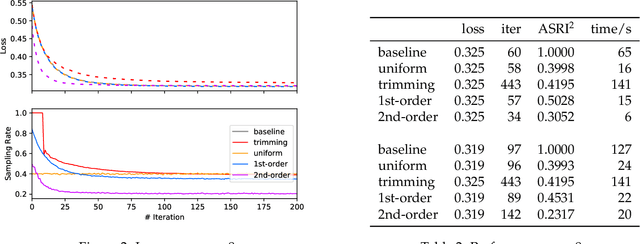
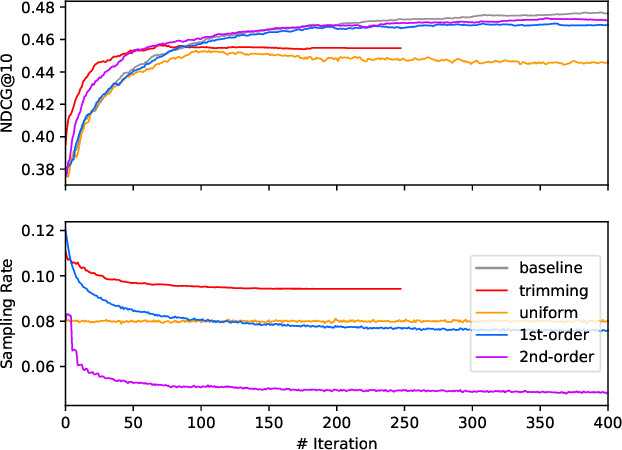
As an adaptive, interpretable, robust, and accurate meta-algorithm for arbitrary differentiable loss functions, gradient tree boosting is one of the most popular machine learning techniques, though the computational expensiveness severely limits its usage. Stochastic gradient boosting could be adopted to accelerates gradient boosting by uniformly sampling training instances, but its estimator could introduce a high variance. This situation arises motivation for us to optimize gradient tree boosting. We combine gradient tree boosting with importance sampling, which achieves better performance by reducing the stochastic variance. Furthermore, we use a regularizer to improve the diagonal approximation in the Newton step of gradient boosting. The theoretical analysis supports that our strategies achieve a linear convergence rate on logistic loss. Empirical results show that our algorithm achieves a 2.5x--18x acceleration on two different gradient boosting algorithms (LogitBoost and LambdaMART) without appreciable performance loss.