 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegulating Intermediate 3D Features for Vision-Centric Autonomous Driving
Dec 19, 2023



Multi-camera perception tasks have gained significant attention in the field of autonomous driving. However, existing frameworks based on Lift-Splat-Shoot (LSS) in the multi-camera setting cannot produce suitable dense 3D features due to the projection nature and uncontrollable densification process. To resolve this problem, we propose to regulate intermediate dense 3D features with the help of volume rendering. Specifically, we employ volume rendering to process the dense 3D features to obtain corresponding 2D features (e.g., depth maps, semantic maps), which are supervised by associated labels in the training. This manner regulates the generation of dense 3D features on the feature level, providing appropriate dense and unified features for multiple perception tasks. Therefore, our approach is termed Vampire, stands for "Volume rendering As Multi-camera Perception Intermediate feature REgulator". Experimental results on the Occ3D and nuScenes datasets demonstrate that Vampire facilitates fine-grained and appropriate extraction of dense 3D features, and is competitive with existing SOTA methods across diverse downstream perception tasks like 3D occupancy prediction, LiDAR segmentation and 3D objection detection, while utilizing moderate GPU resources. We provide a video demonstration in the supplementary materials and Codes are available at github.com/cskkxjk/Vampire.
MonoNeRD: NeRF-like Representations for Monocular 3D Object Detection
Aug 18, 2023



In the field of monocular 3D detection, it is common practice to utilize scene geometric clues to enhance the detector's performance. However, many existing works adopt these clues explicitly such as estimating a depth map and back-projecting it into 3D space. This explicit methodology induces sparsity in 3D representations due to the increased dimensionality from 2D to 3D, and leads to substantial information loss, especially for distant and occluded objects. To alleviate this issue, we propose MonoNeRD, a novel detection framework that can infer dense 3D geometry and occupancy. Specifically, we model scenes with Signed Distance Functions (SDF), facilitating the production of dense 3D representations. We treat these representations as Neural Radiance Fields (NeRF) and then employ volume rendering to recover RGB images and depth maps. To the best of our knowledge, this work is the first to introduce volume rendering for M3D, and demonstrates the potential of implicit reconstruction for image-based 3D perception. Extensive experiments conducted on the KITTI-3D benchmark and Waymo Open Dataset demonstrate the effectiveness of MonoNeRD. Codes are available at https://github.com/cskkxjk/MonoNeRD.
Learning Occupancy for Monocular 3D Object Detection
May 25, 2023
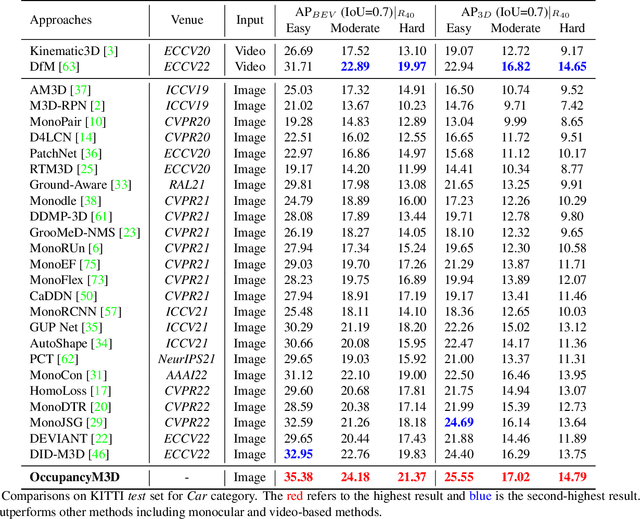
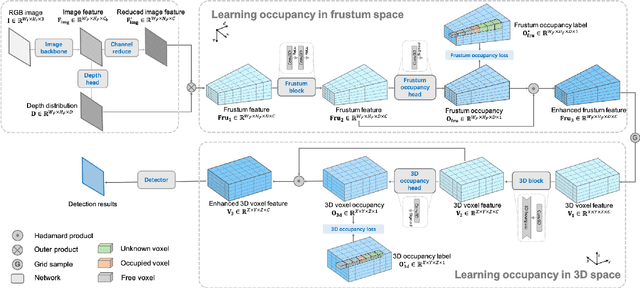
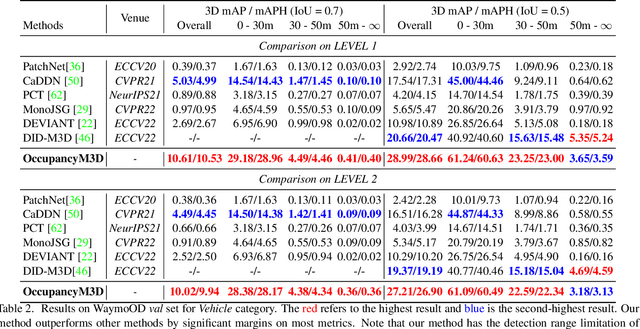
Monocular 3D detection is a challenging task due to the lack of accurate 3D information. Existing approaches typically rely on geometry constraints and dense depth estimates to facilitate the learning, but often fail to fully exploit the benefits of three-dimensional feature extraction in frustum and 3D space. In this paper, we propose \textbf{OccupancyM3D}, a method of learning occupancy for monocular 3D detection. It directly learns occupancy in frustum and 3D space, leading to more discriminative and informative 3D features and representations. Specifically, by using synchronized raw sparse LiDAR point clouds, we define the space status and generate voxel-based occupancy labels. We formulate occupancy prediction as a simple classification problem and design associated occupancy losses. Resulting occupancy estimates are employed to enhance original frustum/3D features. As a result, experiments on KITTI and Waymo open datasets demonstrate that the proposed method achieves a new state of the art and surpasses other methods by a significant margin. Codes and pre-trained models will be available at \url{https://github.com/SPengLiang/OccupancyM3D}.
Stable Learning via Causality-based Feature Rectification
Jul 30, 2020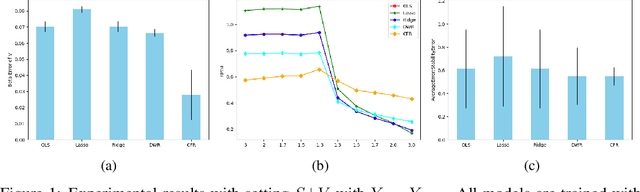
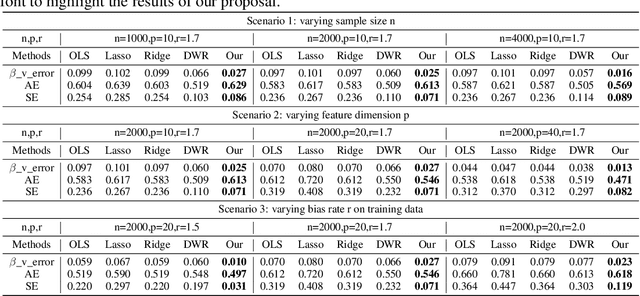
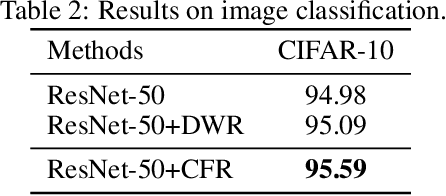
How to learn a stable model under agnostic distribution shift between training and testing datasets is an essential problem in machine learning tasks. The agnostic distribution shift caused by data generation bias can lead to model misspecification and unstable performance across different test datasets. Most of the recently proposed methods are causality-based sample reweighting methods, whose performance is affected by sample size. Moreover, these works are restricted to linear models, not to deep-learning based nonlinear models. In this work, we propose a novel Causality-based Feature Rectification (CFR) method to address the model misspecification problem under agnostic distribution shift by using a weight matrix to rectify features. Our proposal based on the fact that the causality between stable features and the ground truth is consistent under agnostic distribution shift, but is partly omitted and statistically correlated with other features. We propose the feature rectification weight matrix to reconstruct the omitted causality by using other features as proxy variables. We further propose an algorithm that jointly optimizes the weight matrix and the regressor (or classifier). Our proposal can not only improve the stability of linear models, but also deep-learning based models. Extensive experiments on both synthetic and real-world datasets demonstrate that our proposal outperforms previous state-of-the-art stable learning methods. The code will be released later on.