 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Causal RAG: A Retrieval-Augmented Generation Framework for Long Video Reasoning in Complex Scenarios
May 07, 2026Recent large vision-language models have achieved strong performance on short- and medium-length video understanding, yet they remain inadequate for ultra-long or even infinite video reasoning, where models must preserve coherent memory over extended durations and infer causal dependencies across temporally distant events. Existing end-to-end video understanding methods are fundamentally limited by the $O(n^2)$ complexity of self-attention, while recent retrieval-augmented generation (RAG) approaches still suffer from fragmented clip-level memory, weak modeling of temporal and causal structure, and high storage and online inference costs. We present Event-Causal RAG, a lightweight retrieval-augmented framework for infinite long-video reasoning. Instead of indexing fixed-length clips, our method segments streaming videos into semantically coherent events and represents each event as a structured State-Event-State (SES) graph, capturing the event together with its surrounding state transitions. These graphs are merged into a global Event Knowledge Graph and stored in a dual-store memory that supports both semantic matching and causal-topological retrieval. On top of this memory, we design a bidirectional retrieval strategy to efficiently identify the most relevant event causal chains and provide them, together with the associated video evidence, to a backbone video foundation model for answer generation. Experiments on long-video understanding benchmarks demonstrate that Event-Causal RAG consistently outperforms strong clip-based retrieval baselines and long-context video models, particularly on questions requiring multi-event integration and causal inference across long temporal gaps, while also achieving improved memory efficiency and robust streaming performance.
Supervised makeup transfer with a curated dataset: Decoupling identity and makeup features for enhanced transformation
Jan 31, 2026Diffusion models have recently shown strong progress in generative tasks, offering a more stable alternative to GAN-based approaches for makeup transfer. Existing methods often suffer from limited datasets, poor disentanglement between identity and makeup features, and weak controllability. To address these issues, we make three contributions. First, we construct a curated high-quality dataset using a train-generate-filter-retrain strategy that combines synthetic, realistic, and filtered samples to improve diversity and fidelity. Second, we design a diffusion-based framework that disentangles identity and makeup features, ensuring facial structure and skin tone are preserved while applying accurate and diverse cosmetic styles. Third, we propose a text-guided mechanism that allows fine-grained and region-specific control, enabling users to modify eyes, lips, or face makeup with natural language prompts. Experiments on benchmarks and real-world scenarios demonstrate improvements in fidelity, identity preservation, and flexibility. Examples of our dataset can be found at: https://makeup-adapter.github.io.
Spatial-VLN: Zero-Shot Vision-and-Language Navigation With Explicit Spatial Perception and Exploration
Jan 19, 2026Zero-shot Vision-and-Language Navigation (VLN) agents leveraging Large Language Models (LLMs) excel in generalization but suffer from insufficient spatial perception. Focusing on complex continuous environments, we categorize key perceptual bottlenecks into three spatial challenges: door interaction,multi-room navigation, and ambiguous instruction execution, where existing methods consistently suffer high failure rates. We present Spatial-VLN, a perception-guided exploration framework designed to overcome these challenges. The framework consists of two main modules. The Spatial Perception Enhancement (SPE) module integrates panoramic filtering with specialized door and region experts to produce spatially coherent, cross-view consistent perceptual representations. Building on this foundation, our Explored Multi-expert Reasoning (EMR) module uses parallel LLM experts to address waypoint-level semantics and region-level spatial transitions. When discrepancies arise between expert predictions, a query-and-explore mechanism is activated, prompting the agent to actively probe critical areas and resolve perceptual ambiguities. Experiments on VLN-CE demonstrate that Spatial VLN achieves state-of-the-art performance using only low-cost LLMs. Furthermore, to validate real-world applicability, we introduce a value-based waypoint sampling strategy that effectively bridges the Sim2Real gap. Extensive real-world evaluations confirm that our framework delivers superior generalization and robustness in complex environments. Our codes and videos are available at https://yueluhhxx.github.io/Spatial-VLN-web/.
Purification Before Fusion: Toward Mask-Free Speech Enhancement for Robust Audio-Visual Speech Recognition
Jan 18, 2026Audio-visual speech recognition (AVSR) typically improves recognition accuracy in noisy environments by integrating noise-immune visual cues with audio signals. Nevertheless, high-noise audio inputs are prone to introducing adverse interference into the feature fusion process. To mitigate this, recent AVSR methods often adopt mask-based strategies to filter audio noise during feature interaction and fusion, yet such methods risk discarding semantically relevant information alongside noise. In this work, we propose an end-to-end noise-robust AVSR framework coupled with speech enhancement, eliminating the need for explicit noise mask generation. This framework leverages a Conformer-based bottleneck fusion module to implicitly refine noisy audio features with video assistance. By reducing modality redundancy and enhancing inter-modal interactions, our method preserves speech semantic integrity to achieve robust recognition performance. Experimental evaluations on the public LRS3 benchmark suggest that our method outperforms prior advanced mask-based baselines under noisy conditions.
OMG-Bench: A New Challenging Benchmark for Skeleton-based Online Micro Hand Gesture Recognition
Dec 18, 2025Online micro gesture recognition from hand skeletons is critical for VR/AR interaction but faces challenges due to limited public datasets and task-specific algorithms. Micro gestures involve subtle motion patterns, which make constructing datasets with precise skeletons and frame-level annotations difficult. To this end, we develop a multi-view self-supervised pipeline to automatically generate skeleton data, complemented by heuristic rules and expert refinement for semi-automatic annotation. Based on this pipeline, we introduce OMG-Bench, the first large-scale public benchmark for skeleton-based online micro gesture recognition. It features 40 fine-grained gesture classes with 13,948 instances across 1,272 sequences, characterized by subtle motions, rapid dynamics, and continuous execution. To tackle these challenges, we propose Hierarchical Memory-Augmented Transformer (HMATr), an end-to-end framework that unifies gesture detection and classification by leveraging hierarchical memory banks which store frame-level details and window-level semantics to preserve historical context. In addition, it employs learnable position-aware queries initialized from the memory to implicitly encode gesture positions and semantics. Experiments show that HMATr outperforms state-of-the-art methods by 7.6\% in detection rate, establishing a strong baseline for online micro gesture recognition. Project page: https://omg-bench.github.io/
AFD-SLU: Adaptive Feature Distillation for Spoken Language Understanding
Sep 05, 2025Spoken Language Understanding (SLU) is a core component of conversational systems, enabling machines to interpret user utterances. Despite its importance, developing effective SLU systems remains challenging due to the scarcity of labeled training data and the computational burden of deploying Large Language Models (LLMs) in real-world applications. To further alleviate these issues, we propose an Adaptive Feature Distillation framework that transfers rich semantic representations from a General Text Embeddings (GTE)-based teacher model to a lightweight student model. Our method introduces a dynamic adapter equipped with a Residual Projection Neural Network (RPNN) to align heterogeneous feature spaces, and a Dynamic Distillation Coefficient (DDC) that adaptively modulates the distillation strength based on real-time feedback from intent and slot prediction performance. Experiments on the Chinese profile-based ProSLU benchmark demonstrate that AFD-SLU achieves state-of-the-art results, with 95.67% intent accuracy, 92.02% slot F1 score, and 85.50% overall accuracy.
MMME: A Spontaneous Multi-Modal Micro-Expression Dataset Enabling Visual-Physiological Fusion
Jun 12, 2025Micro-expressions (MEs) are subtle, fleeting nonverbal cues that reveal an individual's genuine emotional state. Their analysis has attracted considerable interest due to its promising applications in fields such as healthcare, criminal investigation, and human-computer interaction. However, existing ME research is limited to single visual modality, overlooking the rich emotional information conveyed by other physiological modalities, resulting in ME recognition and spotting performance far below practical application needs. Therefore, exploring the cross-modal association mechanism between ME visual features and physiological signals (PS), and developing a multimodal fusion framework, represents a pivotal step toward advancing ME analysis. This study introduces a novel ME dataset, MMME, which, for the first time, enables synchronized collection of facial action signals (MEs), central nervous system signals (EEG), and peripheral PS (PPG, RSP, SKT, EDA, and ECG). By overcoming the constraints of existing ME corpora, MMME comprises 634 MEs, 2,841 macro-expressions (MaEs), and 2,890 trials of synchronized multimodal PS, establishing a robust foundation for investigating ME neural mechanisms and conducting multimodal fusion-based analyses. Extensive experiments validate the dataset's reliability and provide benchmarks for ME analysis, demonstrating that integrating MEs with PS significantly enhances recognition and spotting performance. To the best of our knowledge, MMME is the most comprehensive ME dataset to date in terms of modality diversity. It provides critical data support for exploring the neural mechanisms of MEs and uncovering the visual-physiological synergistic effects, driving a paradigm shift in ME research from single-modality visual analysis to multimodal fusion. The dataset will be publicly available upon acceptance of this paper.
GeoCAD: Local Geometry-Controllable CAD Generation
Jun 12, 2025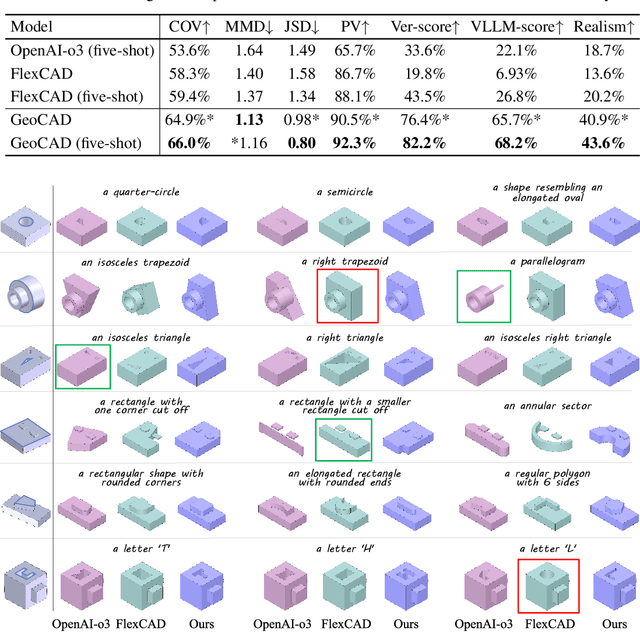
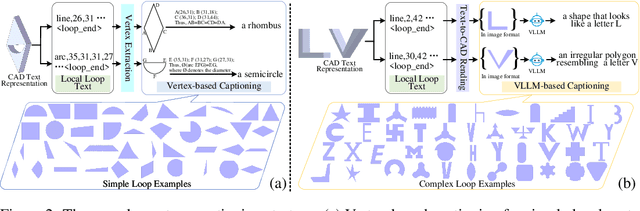
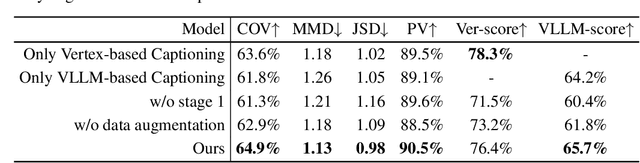

Local geometry-controllable computer-aided design (CAD) generation aims to modify local parts of CAD models automatically, enhancing design efficiency. It also ensures that the shapes of newly generated local parts follow user-specific geometric instructions (e.g., an isosceles right triangle or a rectangle with one corner cut off). However, existing methods encounter challenges in achieving this goal. Specifically, they either lack the ability to follow textual instructions or are unable to focus on the local parts. To address this limitation, we introduce GeoCAD, a user-friendly and local geometry-controllable CAD generation method. Specifically, we first propose a complementary captioning strategy to generate geometric instructions for local parts. This strategy involves vertex-based and VLLM-based captioning for systematically annotating simple and complex parts, respectively. In this way, we caption $\sim$221k different local parts in total. In the training stage, given a CAD model, we randomly mask a local part. Then, using its geometric instruction and the remaining parts as input, we prompt large language models (LLMs) to predict the masked part. During inference, users can specify any local part for modification while adhering to a variety of predefined geometric instructions. Extensive experiments demonstrate the effectiveness of GeoCAD in generation quality, validity and text-to-CAD consistency. Code will be available at https://github.com/Zhanwei-Z/GeoCAD.
MPFNet: A Multi-Prior Fusion Network with a Progressive Training Strategy for Micro-Expression Recognition
Jun 11, 2025Micro-expression recognition (MER), a critical subfield of affective computing, presents greater challenges than macro-expression recognition due to its brief duration and low intensity. While incorporating prior knowledge has been shown to enhance MER performance, existing methods predominantly rely on simplistic, singular sources of prior knowledge, failing to fully exploit multi-source information. This paper introduces the Multi-Prior Fusion Network (MPFNet), leveraging a progressive training strategy to optimize MER tasks. We propose two complementary encoders: the Generic Feature Encoder (GFE) and the Advanced Feature Encoder (AFE), both based on Inflated 3D ConvNets (I3D) with Coordinate Attention (CA) mechanisms, to improve the model's ability to capture spatiotemporal and channel-specific features. Inspired by developmental psychology, we present two variants of MPFNet--MPFNet-P and MPFNet-C--corresponding to two fundamental modes of infant cognitive development: parallel and hierarchical processing. These variants enable the evaluation of different strategies for integrating prior knowledge. Extensive experiments demonstrate that MPFNet significantly improves MER accuracy while maintaining balanced performance across categories, achieving accuracies of 0.811, 0.924, and 0.857 on the SMIC, CASME II, and SAMM datasets, respectively. To the best of our knowledge, our approach achieves state-of-the-art performance on the SMIC and SAMM datasets.
Generating Vision-Language Navigation Instructions Incorporated Fine-Grained Alignment Annotations
Jun 10, 2025Vision-Language Navigation (VLN) enables intelligent agents to navigate environments by integrating visual perception and natural language instructions, yet faces significant challenges due to the scarcity of fine-grained cross-modal alignment annotations. Existing datasets primarily focus on global instruction-trajectory matching, neglecting sub-instruction-level and entity-level alignments critical for accurate navigation action decision-making. To address this limitation, we propose FCA-NIG, a generative framework that automatically constructs navigation instructions with dual-level fine-grained cross-modal annotations. In this framework, an augmented trajectory is first divided into sub-trajectories, which are then processed through GLIP-based landmark detection, crafted instruction construction, OFA-Speaker based R2R-like instruction generation, and CLIP-powered entity selection, generating sub-instruction-trajectory pairs with entity-landmark annotations. Finally, these sub-pairs are aggregated to form a complete instruction-trajectory pair. The framework generates the FCA-R2R dataset, the first large-scale augmentation dataset featuring precise sub-instruction-sub-trajectory and entity-landmark alignments. Extensive experiments demonstrate that training with FCA-R2R significantly improves the performance of multiple state-of-the-art VLN agents, including SF, EnvDrop, RecBERT, and HAMT. Incorporating sub-instruction-trajectory alignment enhances agents' state awareness and decision accuracy, while entity-landmark alignment further boosts navigation performance and generalization. These results highlight the effectiveness of FCA-NIG in generating high-quality, scalable training data without manual annotation, advancing fine-grained cross-modal learning in complex navigation tasks.