 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-aware SAR ship detection guided by unsupervised sea-land segmentation
Jun 15, 2025DL based Synthetic Aperture Radar (SAR) ship detection has tremendous advantages in numerous areas. However, it still faces some problems, such as the lack of prior knowledge, which seriously affects detection accuracy. In order to solve this problem, we propose a scene-aware SAR ship detection method based on unsupervised sea-land segmentation. This method follows a classical two-stage framework and is enhanced by two models: the unsupervised land and sea segmentation module (ULSM) and the land attention suppression module (LASM). ULSM and LASM can adaptively guide the network to reduce attention on land according to the type of scenes (inshore scene and offshore scene) and add prior knowledge (sea land segmentation information) to the network, thereby reducing the network's attention to land directly and enhancing offshore detection performance relatively. This increases the accuracy of ship detection and enhances the interpretability of the model. Specifically, in consideration of the lack of land sea segmentation labels in existing deep learning-based SAR ship detection datasets, ULSM uses an unsupervised approach to classify the input data scene into inshore and offshore types and performs sea-land segmentation for inshore scenes. LASM uses the sea-land segmentation information as prior knowledge to reduce the network's attention to land. We conducted our experiments using the publicly available SSDD dataset, which demonstrated the effectiveness of our network.
MMME: A Spontaneous Multi-Modal Micro-Expression Dataset Enabling Visual-Physiological Fusion
Jun 12, 2025Micro-expressions (MEs) are subtle, fleeting nonverbal cues that reveal an individual's genuine emotional state. Their analysis has attracted considerable interest due to its promising applications in fields such as healthcare, criminal investigation, and human-computer interaction. However, existing ME research is limited to single visual modality, overlooking the rich emotional information conveyed by other physiological modalities, resulting in ME recognition and spotting performance far below practical application needs. Therefore, exploring the cross-modal association mechanism between ME visual features and physiological signals (PS), and developing a multimodal fusion framework, represents a pivotal step toward advancing ME analysis. This study introduces a novel ME dataset, MMME, which, for the first time, enables synchronized collection of facial action signals (MEs), central nervous system signals (EEG), and peripheral PS (PPG, RSP, SKT, EDA, and ECG). By overcoming the constraints of existing ME corpora, MMME comprises 634 MEs, 2,841 macro-expressions (MaEs), and 2,890 trials of synchronized multimodal PS, establishing a robust foundation for investigating ME neural mechanisms and conducting multimodal fusion-based analyses. Extensive experiments validate the dataset's reliability and provide benchmarks for ME analysis, demonstrating that integrating MEs with PS significantly enhances recognition and spotting performance. To the best of our knowledge, MMME is the most comprehensive ME dataset to date in terms of modality diversity. It provides critical data support for exploring the neural mechanisms of MEs and uncovering the visual-physiological synergistic effects, driving a paradigm shift in ME research from single-modality visual analysis to multimodal fusion. The dataset will be publicly available upon acceptance of this paper.
MPFNet: A Multi-Prior Fusion Network with a Progressive Training Strategy for Micro-Expression Recognition
Jun 11, 2025Micro-expression recognition (MER), a critical subfield of affective computing, presents greater challenges than macro-expression recognition due to its brief duration and low intensity. While incorporating prior knowledge has been shown to enhance MER performance, existing methods predominantly rely on simplistic, singular sources of prior knowledge, failing to fully exploit multi-source information. This paper introduces the Multi-Prior Fusion Network (MPFNet), leveraging a progressive training strategy to optimize MER tasks. We propose two complementary encoders: the Generic Feature Encoder (GFE) and the Advanced Feature Encoder (AFE), both based on Inflated 3D ConvNets (I3D) with Coordinate Attention (CA) mechanisms, to improve the model's ability to capture spatiotemporal and channel-specific features. Inspired by developmental psychology, we present two variants of MPFNet--MPFNet-P and MPFNet-C--corresponding to two fundamental modes of infant cognitive development: parallel and hierarchical processing. These variants enable the evaluation of different strategies for integrating prior knowledge. Extensive experiments demonstrate that MPFNet significantly improves MER accuracy while maintaining balanced performance across categories, achieving accuracies of 0.811, 0.924, and 0.857 on the SMIC, CASME II, and SAMM datasets, respectively. To the best of our knowledge, our approach achieves state-of-the-art performance on the SMIC and SAMM datasets.
PanoGen++: Domain-Adapted Text-Guided Panoramic Environment Generation for Vision-and-Language Navigation
Mar 13, 2025Vision-and-language navigation (VLN) tasks require agents to navigate three-dimensional environments guided by natural language instructions, offering substantial potential for diverse applications. However, the scarcity of training data impedes progress in this field. This paper introduces PanoGen++, a novel framework that addresses this limitation by generating varied and pertinent panoramic environments for VLN tasks. PanoGen++ incorporates pre-trained diffusion models with domain-specific fine-tuning, employing parameter-efficient techniques such as low-rank adaptation to minimize computational costs. We investigate two settings for environment generation: masked image inpainting and recursive image outpainting. The former maximizes novel environment creation by inpainting masked regions based on textual descriptions, while the latter facilitates agents' learning of spatial relationships within panoramas. Empirical evaluations on room-to-room (R2R), room-for-room (R4R), and cooperative vision-and-dialog navigation (CVDN) datasets reveal significant performance enhancements: a 2.44% increase in success rate on the R2R test leaderboard, a 0.63% improvement on the R4R validation unseen set, and a 0.75-meter enhancement in goal progress on the CVDN validation unseen set. PanoGen++ augments the diversity and relevance of training environments, resulting in improved generalization and efficacy in VLN tasks.
Landmark-Guided Cross-Speaker Lip Reading with Mutual Information Regularization
Mar 24, 2024



Lip reading, the process of interpreting silent speech from visual lip movements, has gained rising attention for its wide range of realistic applications. Deep learning approaches greatly improve current lip reading systems. However, lip reading in cross-speaker scenarios where the speaker identity changes, poses a challenging problem due to inter-speaker variability. A well-trained lip reading system may perform poorly when handling a brand new speaker. To learn a speaker-robust lip reading model, a key insight is to reduce visual variations across speakers, avoiding the model overfitting to specific speakers. In this work, in view of both input visual clues and latent representations based on a hybrid CTC/attention architecture, we propose to exploit the lip landmark-guided fine-grained visual clues instead of frequently-used mouth-cropped images as input features, diminishing speaker-specific appearance characteristics. Furthermore, a max-min mutual information regularization approach is proposed to capture speaker-insensitive latent representations. Experimental evaluations on public lip reading datasets demonstrate the effectiveness of the proposed approach under the intra-speaker and inter-speaker conditions.
* To appear in LREC-COLING 2024
HDA-LVIO: A High-Precision LiDAR-Visual-Inertial Odometry in Urban Environments with Hybrid Data Association
Mar 11, 2024To enhance localization accuracy in urban environments, an innovative LiDAR-Visual-Inertial odometry, named HDA-LVIO, is proposed by employing hybrid data association. The proposed HDA_LVIO system can be divided into two subsystems: the LiDAR-Inertial subsystem (LIS) and the Visual-Inertial subsystem (VIS). In the LIS, the LiDAR pointcloud is utilized to calculate the Iterative Closest Point (ICP) error, serving as the measurement value of Error State Iterated Kalman Filter (ESIKF) to construct the global map. In the VIS, an incremental method is firstly employed to adaptively extract planes from the global map. And the centroids of these planes are projected onto the image to obtain projection points. Then, feature points are extracted from the image and tracked along with projection points using Lucas-Kanade (LK) optical flow. Next, leveraging the vehicle states from previous intervals, sliding window optimization is performed to estimate the depth of feature points. Concurrently, a method based on epipolar geometric constraints is proposed to address tracking failures for feature points, which can improve the accuracy of depth estimation for feature points by ensuring sufficient parallax within the sliding window. Subsequently, the feature points and projection points are hybridly associated to construct reprojection error, serving as the measurement value of ESIKF to estimate vehicle states. Finally, the localization accuracy of the proposed HDA-LVIO is validated using public datasets and data from our equipment. The results demonstrate that the proposed algorithm achieves obviously improvement in localization accuracy compared to various existing algorithms.
Safe-VLN: Collision Avoidance for Vision-and-Language Navigation of Autonomous Robots Operating in Continuous Environments
Nov 06, 2023
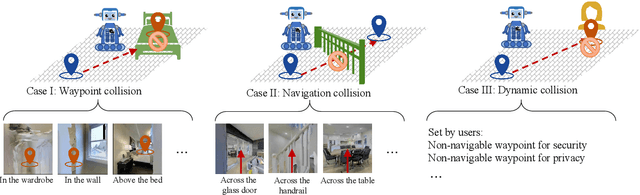
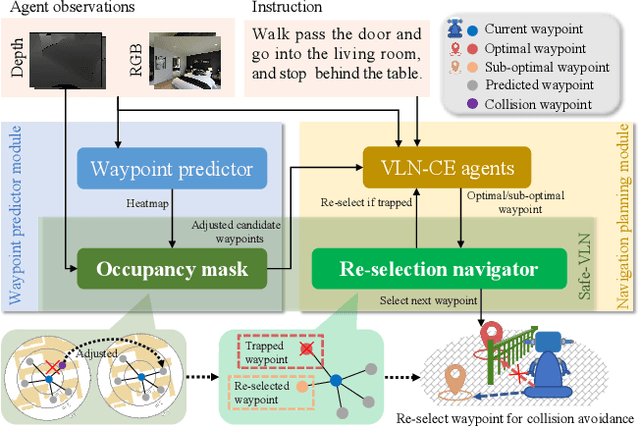

The task of vision-and-language navigation in continuous environments (VLN-CE) aims at training an autonomous agent to perform low-level actions to navigate through 3D continuous surroundings using visual observations and language instructions. The significant potential of VLN-CE for mobile robots has been demonstrated across a large number of studies. However, most existing works in VLN-CE focus primarily on transferring the standard discrete vision-and-language navigation (VLN) methods to continuous environments, overlooking the problem of collisions. Such oversight often results in the agent deviating from the planned path or, in severe instances, the agent being trapped in obstacle areas and failing the navigational task. To address the above-mentioned issues, this paper investigates various collision scenarios within VLN-CE and proposes a classification method to predicate the underlying causes of collisions. Furthermore, a new VLN-CE algorithm, named Safe-VLN, is proposed to bolster collision avoidance capabilities including two key components, i.e., a waypoint predictor and a navigator. In particular, the waypoint predictor leverages a simulated 2D LiDAR occupancy mask to prevent the predicted waypoints from being situated in obstacle-ridden areas. The navigator, on the other hand, employs the strategy of `re-selection after collision' to prevent the robot agent from becoming ensnared in a cycle of perpetual collisions. The proposed Safe-VLN is evaluated on the R2R-CE, the results of which demonstrate an enhanced navigational performance and a statistically significant reduction in collision incidences.
Grounded Entity-Landmark Adaptive Pre-training for Vision-and-Language Navigation
Aug 24, 2023Cross-modal alignment is one key challenge for Vision-and-Language Navigation (VLN). Most existing studies concentrate on mapping the global instruction or single sub-instruction to the corresponding trajectory. However, another critical problem of achieving fine-grained alignment at the entity level is seldom considered. To address this problem, we propose a novel Grounded Entity-Landmark Adaptive (GELA) pre-training paradigm for VLN tasks. To achieve the adaptive pre-training paradigm, we first introduce grounded entity-landmark human annotations into the Room-to-Room (R2R) dataset, named GEL-R2R. Additionally, we adopt three grounded entity-landmark adaptive pre-training objectives: 1) entity phrase prediction, 2) landmark bounding box prediction, and 3) entity-landmark semantic alignment, which explicitly supervise the learning of fine-grained cross-modal alignment between entity phrases and environment landmarks. Finally, we validate our model on two downstream benchmarks: VLN with descriptive instructions (R2R) and dialogue instructions (CVDN). The comprehensive experiments show that our GELA model achieves state-of-the-art results on both tasks, demonstrating its effectiveness and generalizability.
Planimation
Aug 11, 2020Planimation is a modular and extensible open source framework to visualise sequential solutions of planning problems specified in PDDL. We introduce a preliminary declarative PDDL-like animation profile specification, expressive enough to synthesise animations of arbitrary initial states and goals of a benchmark with just a single profile.