 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Ego-Motion from Target Dynamics via Dual-Interval Motion Cues for UAV Detection
May 21, 2026Object detection from Unmanned Aerial Vehicles (UAVs) is challenged by severe ego-motion, camera jitter, and large scale variations. While modern detectors perform well on static images, their direct application to UAV video often fails, particularly for small objects in dynamic scenes. Existing motion-based methods either rely on computationally expensive optical flow or use single-interval differencing, which is sensitive to jitter and limited in capturing diverse motion patterns. We propose a vision-only motion-guided detection framework that decouples target motion from camera-induced disturbances. A homography-based Global Motion Compensation (GMC) first aligns adjacent frames. We then introduce a Dual-Interval Motion Extraction strategy that captures both short-term and long-term motion cues. To integrate these cues, a lightweight Motion-Guided Attention (MGA) module enhances feature representations within a Feature Pyramid Network. Experiments on the VisDrone-VID dataset demonstrate consistent improvements over a strong YOLOv8 baseline under severe ego-motion. Ablation studies further confirm the effectiveness of the dual-interval design and the proposed motion-guided attention mechanism.
Inductance-Based Force Self-Sensing in Fiber-Reinforced Pneumatic Twisted-and-Coiled Actuators
Mar 19, 2026Fiber-reinforced pneumatic twisted-and-coiled actuators (FR-PTCAs) offer high power density and compliance but their strong hysteresis and lack of intrinsic proprioception limit effective closed-loop control. This paper presents a self-sensing FR-PTCA integrated with a conductive nickel wire that enables intrinsic force estimation and indirect displacement inference via inductance feedback. Experimental characterization reveals that the inductance of the actuator exhibits a deterministic, low-hysteresis inductance-force relationship at constant pressures, in contrast to the strongly hysteretic inductance-length behavior. Leveraging this property, this paper develops a parametric self-sensing model and a nonlinear hybrid observer that integrates an Extended Kalman Filter (EKF) with constrained optimization to resolve the ambiguity in the inductance-force mapping and estimate actuator states. Experimental results demonstrate that the proposed approach achieves force estimation accuracy comparable to that of external load cells and maintains robust performance under varying load conditions.
Dual-Regime Hybrid Aerodynamic Modeling of Winged Blimps With Neural Mixing
Feb 25, 2026Winged blimps operate across distinct aerodynamic regimes that cannot be adequately captured by a single model. At high speeds and small angles of attack, their dynamics exhibit strong coupling between lift and attitude, resembling fixed-wing aircraft behavior. At low speeds or large angles of attack, viscous effects and flow separation dominate, leading to drag-driven and damping-dominated dynamics. Accurately representing transitions between these regimes remains a fundamental challenge. This paper presents a hybrid aerodynamic modeling framework that integrates a fixed-wing Aerodynamic Coupling Model (ACM) and a Generalized Drag Model (GDM) using a learned neural network mixer with explicit physics-based regularization. The mixer enables smooth transitions between regimes while retaining explicit, physics-based aerodynamic representation. Model parameters are identified through a structured three-phase pipeline tailored for hybrid aerodynamic modeling. The proposed approach is validated on the RGBlimp platform through a large-scale experimental campaign comprising 1,320 real-world flight trajectories across 330 thruster and moving mass configurations, spanning a wide range of speeds and angles of attack. Experimental results demonstrate that the proposed hybrid model consistently outperforms single-model and predefined-mixer baselines, establishing a practical and robust aerodynamic modeling solution for winged blimps.
Disturbance-Aware Flight Control of Robotic Gliding Blimp via Moving Mass Actuation
Jan 29, 2026Robotic blimps, as lighter-than-air (LTA) aerial systems, offer long endurance and inherently safe operation but remain highly susceptible to wind disturbances. Building on recent advances in moving mass actuation, this paper addresses the lack of disturbance-aware control frameworks for LTA platforms by explicitly modeling and compensating for wind-induced effects. A moving horizon estimator (MHE) infers real-time wind perturbations and provides these estimates to a model predictive controller (MPC), enabling robust trajectory and heading regulation under varying wind conditions. The proposed approach leverages a two-degree-of-freedom (2-DoF) moving-mass mechanism to generate both inertial and aerodynamic moments for attitude and heading control, thereby enhancing flight stability in disturbance-prone environments. Extensive flight experiments under headwind and crosswind conditions show that the integrated MHE-MPC framework significantly outperforms baseline PID control, demonstrating its effectiveness for disturbance-aware LTA flight.
Spatial-VLN: Zero-Shot Vision-and-Language Navigation With Explicit Spatial Perception and Exploration
Jan 19, 2026Zero-shot Vision-and-Language Navigation (VLN) agents leveraging Large Language Models (LLMs) excel in generalization but suffer from insufficient spatial perception. Focusing on complex continuous environments, we categorize key perceptual bottlenecks into three spatial challenges: door interaction,multi-room navigation, and ambiguous instruction execution, where existing methods consistently suffer high failure rates. We present Spatial-VLN, a perception-guided exploration framework designed to overcome these challenges. The framework consists of two main modules. The Spatial Perception Enhancement (SPE) module integrates panoramic filtering with specialized door and region experts to produce spatially coherent, cross-view consistent perceptual representations. Building on this foundation, our Explored Multi-expert Reasoning (EMR) module uses parallel LLM experts to address waypoint-level semantics and region-level spatial transitions. When discrepancies arise between expert predictions, a query-and-explore mechanism is activated, prompting the agent to actively probe critical areas and resolve perceptual ambiguities. Experiments on VLN-CE demonstrate that Spatial VLN achieves state-of-the-art performance using only low-cost LLMs. Furthermore, to validate real-world applicability, we introduce a value-based waypoint sampling strategy that effectively bridges the Sim2Real gap. Extensive real-world evaluations confirm that our framework delivers superior generalization and robustness in complex environments. Our codes and videos are available at https://yueluhhxx.github.io/Spatial-VLN-web/.
ST-Booster: An Iterative SpatioTemporal Perception Booster for Vision-and-Language Navigation in Continuous Environments
Apr 14, 2025Vision-and-Language Navigation in Continuous Environments (VLN-CE) requires agents to navigate unknown, continuous spaces based on natural language instructions. Compared to discrete settings, VLN-CE poses two core perception challenges. First, the absence of predefined observation points leads to heterogeneous visual memories and weakened global spatial correlations. Second, cumulative reconstruction errors in three-dimensional scenes introduce structural noise, impairing local feature perception. To address these challenges, this paper proposes ST-Booster, an iterative spatiotemporal booster that enhances navigation performance through multi-granularity perception and instruction-aware reasoning. ST-Booster consists of three key modules -- Hierarchical SpatioTemporal Encoding (HSTE), Multi-Granularity Aligned Fusion (MGAF), and ValueGuided Waypoint Generation (VGWG). HSTE encodes long-term global memory using topological graphs and captures shortterm local details via grid maps. MGAF aligns these dualmap representations with instructions through geometry-aware knowledge fusion. The resulting representations are iteratively refined through pretraining tasks. During reasoning, VGWG generates Guided Attention Heatmaps (GAHs) to explicitly model environment-instruction relevance and optimize waypoint selection. Extensive comparative experiments and performance analyses are conducted, demonstrating that ST-Booster outperforms existing state-of-the-art methods, particularly in complex, disturbance-prone environments.
Bioinspired Sensing of Undulatory Flow Fields Generated by Leg Kicks in Swimming
Mar 10, 2025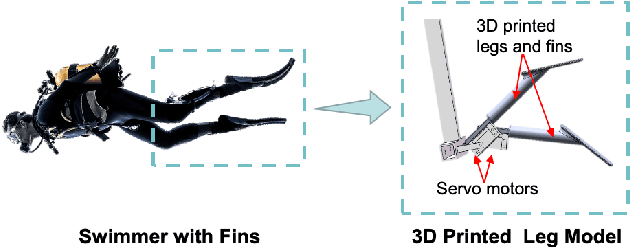
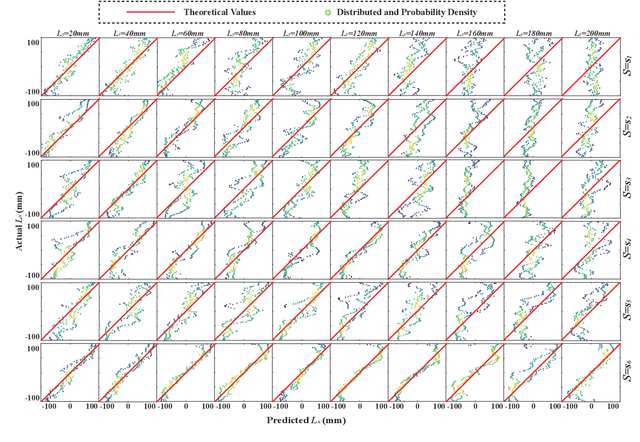
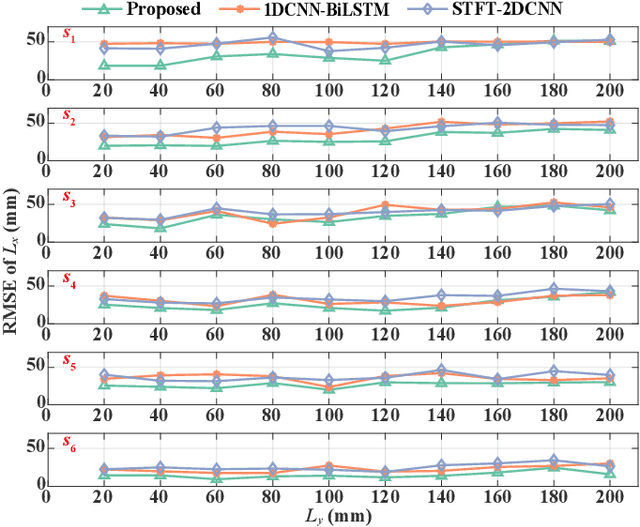
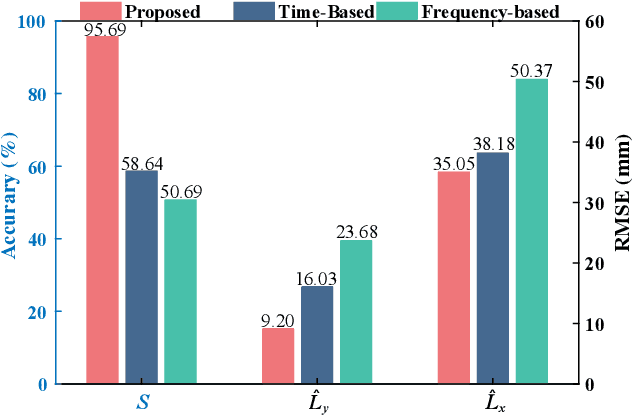
The artificial lateral line (ALL) is a bioinspired flow sensing system for underwater robots, comprising of distributed flow sensors. The ALL has been successfully applied to detect the undulatory flow fields generated by body undulation and tail-flapping of bioinspired robotic fish. However, its feasibility and performance in sensing the undulatory flow fields produced by human leg kicks during swimming has not been systematically tested and studied. This paper presents a novel sensing framework to investigate the undulatory flow field generated by swimmer's leg kicks, leveraging bioinspired ALL sensing. To evaluate the feasibility of using the ALL system for sensing the undulatory flow fields generated by swimmer leg kicks, this paper designs an experimental platform integrating an ALL system and a lab-fabricated human leg model. To enhance the accuracy of flow sensing, this paper proposes a feature extraction method that dynamically fuses time-domain and time-frequency characteristics. Specifically, time-domain features are extracted using one-dimensional convolutional neural networks and bidirectional long short-term memory networks (1DCNN-BiLSTM), while time-frequency features are extracted using short-term Fourier transform and two-dimensional convolutional neural networks (STFT-2DCNN). These features are then dynamically fused based on attention mechanisms to achieve accurate sensing of the undulatory flow field. Furthermore, extensive experiments are conducted to test various scenarios inspired by human swimming, such as leg kick pattern recognition and kicking leg localization, achieving satisfactory results.
Design, Dynamic Modeling and Control of a 2-DOF Robotic Wrist Actuated by Twisted and Coiled Actuators
Mar 07, 2025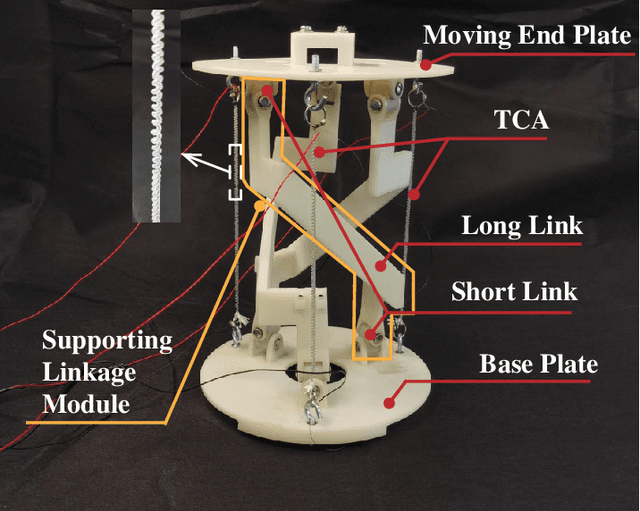
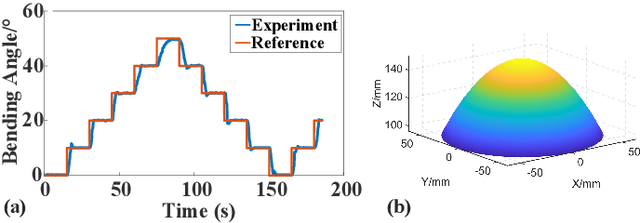
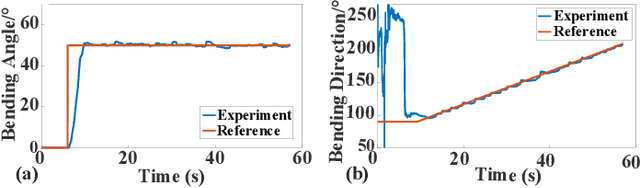
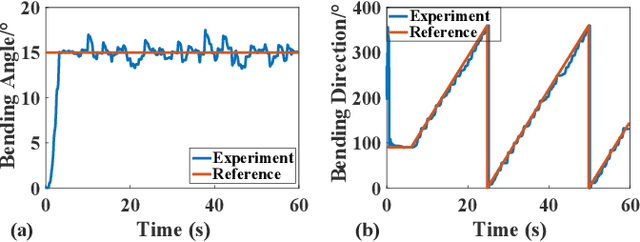
Robotic wrists play a pivotal role in the functionality of industrial manipulators and humanoid robots, facilitating manipulation and grasping tasks. In recent years, there has been a growing interest in integrating artificial muscle-driven actuators for robotic wrists, driven by advancements in technology offering high energy density, lightweight construction, and compact designs. However, in the study of robotic wrists driven by artificial muscles, dynamic model-based controllers are often overlooked, despite their critical importance for motion analysis and dynamic control of robots. This paper presents a novel design of a two-degree-of-freedom (2-DOF) robotic wrist driven by twisted and coiled actuators (TCA) utilizing a parallel mechanism with a 3RRRR configuration. The proposed robotic wrist is expected to feature lightweight structures and superior motion performance while mitigating friction issues. The Lagrangian dynamic model of the wrist is established, along with a nonlinear model predictive controller (NMPC) designed for trajectory tracking tasks. A prototype of the robotic wrist is developed, and extensive experiments are conducted to validate its superior motion performance and the proposed dynamic model. Subsequently, extensive comparative experiments between NMPC and PID controller were conducted under various operating conditions. The experimental results demonstrate the effectiveness and robustness of the dynamic model-based controller in the motion control of TCA-driven robotic wrists.
Learning-Based Leader Localization for Underwater Vehicles With Optical-Acoustic-Pressure Sensor Fusion
Feb 28, 2025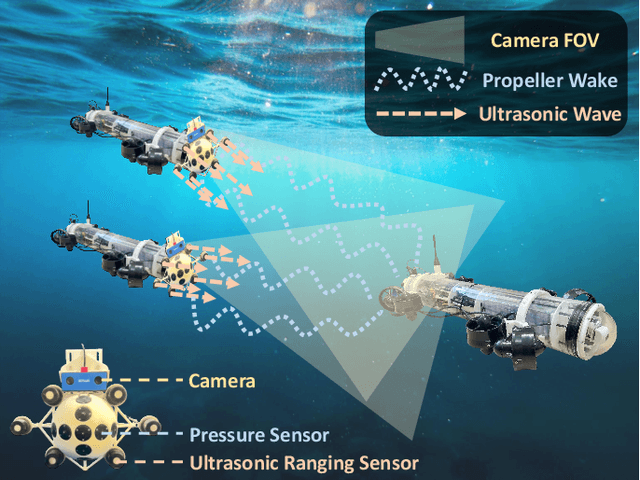

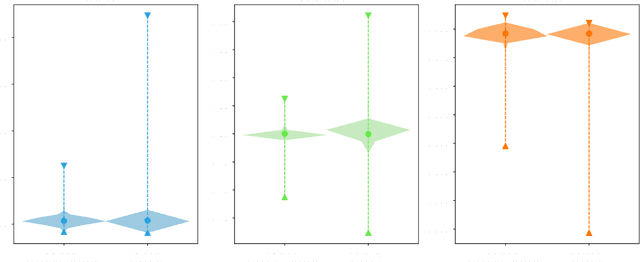
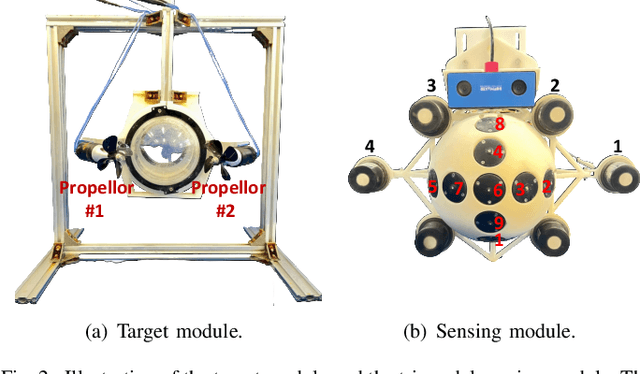
Underwater vehicles have emerged as a critical technology for exploring and monitoring aquatic environments. The deployment of multi-vehicle systems has gained substantial interest due to their capability to perform collaborative tasks with improved efficiency. However, achieving precise localization of a leader underwater vehicle within a multi-vehicle configuration remains a significant challenge, particularly in dynamic and complex underwater conditions. To address this issue, this paper presents a novel tri-modal sensor fusion neural network approach that integrates optical, acoustic, and pressure sensors to localize the leader vehicle. The proposed method leverages the unique strengths of each sensor modality to improve localization accuracy and robustness. Specifically, optical sensors provide high-resolution imaging for precise relative positioning, acoustic sensors enable long-range detection and ranging, and pressure sensors offer environmental context awareness. The fusion of these sensor modalities is implemented using a deep learning architecture designed to extract and combine complementary features from raw sensor data. The effectiveness of the proposed method is validated through a custom-designed testing platform. Extensive data collection and experimental evaluations demonstrate that the tri-modal approach significantly improves the accuracy and robustness of leader localization, outperforming both single-modal and dual-modal methods.
Target Defense with Multiple Defenders and an Agile Attacker via Residual Policy Learning
Feb 25, 2025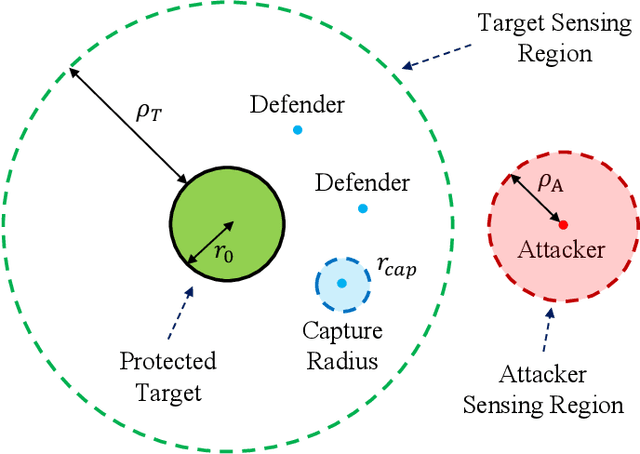
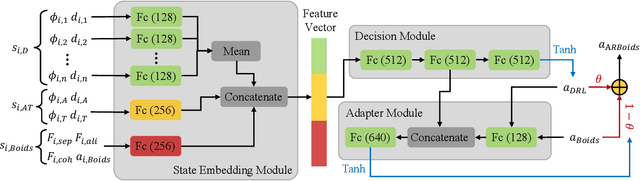
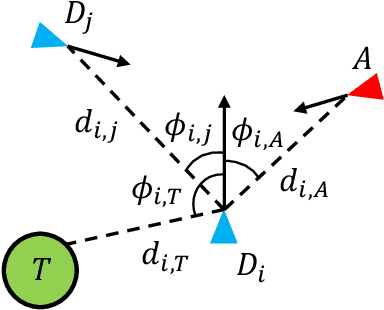
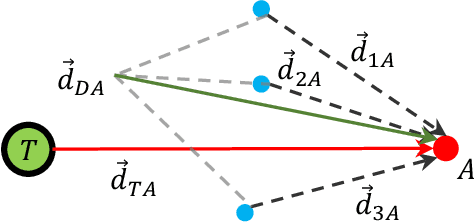
The target defense problem involves intercepting an attacker before it reaches a designated target region using one or more defenders. This letter focuses on a particularly challenging scenario in which the attacker is more agile than the defenders, significantly increasing the difficulty of effective interception. To address this challenge, we propose a novel residual policy framework that integrates deep reinforcement learning (DRL) with the force-based Boids model. In this framework, the Boids model serves as a baseline policy, while DRL learns a residual policy to refine and optimize the defenders' actions. Simulation experiments demonstrate that the proposed method consistently outperforms traditional interception policies, whether learned via vanilla DRL or fine-tuned from force-based methods. Moreover, the learned policy exhibits strong scalability and adaptability, effectively handling scenarios with varying numbers of defenders and attackers with different agility levels.