 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaveBench: A Versatile Benchmark for Pavement Distress Perception and Interactive Vision-Language Analysis
Apr 03, 2026Pavement condition assessment is essential for road safety and maintenance. Existing research has made significant progress. However, most studies focus on conventional computer vision tasks such as classification, detection, and segmentation. In real-world applications, pavement inspection requires more than visual recognition. It also requires quantitative analysis, explanation, and interactive decision support. Current datasets are limited. They focus on unimodal perception. They lack support for multi-turn interaction and fact-grounded reasoning. They also do not connect perception with vision-language analysis. To address these limitations, we introduce PaveBench, a large-scale benchmark for pavement distress perception and interactive vision-language analysis on real-world highway inspection images. PaveBench supports four core tasks: classification, object detection, semantic segmentation, and vision-language question answering. It provides unified task definitions and evaluation protocols. On the visual side, PaveBench provides large-scale annotations and includes a curated hard-distractor subset for robustness evaluation. It contains a large collection of real-world pavement images. On the multimodal side, we introduce PaveVQA, a real-image question answering (QA) dataset that supports single-turn, multi-turn, and expert-corrected interactions. It covers recognition, localization, quantitative estimation, and maintenance reasoning. We evaluate several state-of-the-art methods and provide a detailed analysis. We also present a simple and effective agent-augmented visual question answering framework that integrates domain-specific models as tools alongside vision-language models. The dataset is available at: https://huggingface.co/datasets/MML-Group/PaveBench.
ST-Booster: An Iterative SpatioTemporal Perception Booster for Vision-and-Language Navigation in Continuous Environments
Apr 14, 2025Vision-and-Language Navigation in Continuous Environments (VLN-CE) requires agents to navigate unknown, continuous spaces based on natural language instructions. Compared to discrete settings, VLN-CE poses two core perception challenges. First, the absence of predefined observation points leads to heterogeneous visual memories and weakened global spatial correlations. Second, cumulative reconstruction errors in three-dimensional scenes introduce structural noise, impairing local feature perception. To address these challenges, this paper proposes ST-Booster, an iterative spatiotemporal booster that enhances navigation performance through multi-granularity perception and instruction-aware reasoning. ST-Booster consists of three key modules -- Hierarchical SpatioTemporal Encoding (HSTE), Multi-Granularity Aligned Fusion (MGAF), and ValueGuided Waypoint Generation (VGWG). HSTE encodes long-term global memory using topological graphs and captures shortterm local details via grid maps. MGAF aligns these dualmap representations with instructions through geometry-aware knowledge fusion. The resulting representations are iteratively refined through pretraining tasks. During reasoning, VGWG generates Guided Attention Heatmaps (GAHs) to explicitly model environment-instruction relevance and optimize waypoint selection. Extensive comparative experiments and performance analyses are conducted, demonstrating that ST-Booster outperforms existing state-of-the-art methods, particularly in complex, disturbance-prone environments.
PanoGen++: Domain-Adapted Text-Guided Panoramic Environment Generation for Vision-and-Language Navigation
Mar 13, 2025Vision-and-language navigation (VLN) tasks require agents to navigate three-dimensional environments guided by natural language instructions, offering substantial potential for diverse applications. However, the scarcity of training data impedes progress in this field. This paper introduces PanoGen++, a novel framework that addresses this limitation by generating varied and pertinent panoramic environments for VLN tasks. PanoGen++ incorporates pre-trained diffusion models with domain-specific fine-tuning, employing parameter-efficient techniques such as low-rank adaptation to minimize computational costs. We investigate two settings for environment generation: masked image inpainting and recursive image outpainting. The former maximizes novel environment creation by inpainting masked regions based on textual descriptions, while the latter facilitates agents' learning of spatial relationships within panoramas. Empirical evaluations on room-to-room (R2R), room-for-room (R4R), and cooperative vision-and-dialog navigation (CVDN) datasets reveal significant performance enhancements: a 2.44% increase in success rate on the R2R test leaderboard, a 0.63% improvement on the R4R validation unseen set, and a 0.75-meter enhancement in goal progress on the CVDN validation unseen set. PanoGen++ augments the diversity and relevance of training environments, resulting in improved generalization and efficacy in VLN tasks.
COutfitGAN: Learning to Synthesize Compatible Outfits Supervised by Silhouette Masks and Fashion Styles
Feb 12, 2025



How to recommend outfits has gained considerable attention in both academia and industry in recent years. Many studies have been carried out regarding fashion compatibility learning, to determine whether the fashion items in an outfit are compatible or not. These methods mainly focus on evaluating the compatibility of existing outfits and rarely consider applying such knowledge to 'design' new fashion items. We propose the new task of generating complementary and compatible fashion items based on an arbitrary number of given fashion items. In particular, given some fashion items that can make up an outfit, the aim of this paper is to synthesize photo-realistic images of other, complementary, fashion items that are compatible with the given ones. To achieve this, we propose an outfit generation framework, referred to as COutfitGAN, which includes a pyramid style extractor, an outfit generator, a UNet-based real/fake discriminator, and a collocation discriminator. To train and evaluate this framework, we collected a large-scale fashion outfit dataset with over 200K outfits and 800K fashion items from the Internet. Extensive experiments show that COutfitGAN outperforms other baselines in terms of similarity, authenticity, and compatibility measurements.
FCBoost-Net: A Generative Network for Synthesizing Multiple Collocated Outfits via Fashion Compatibility Boosting
Feb 03, 2025



Outfit generation is a challenging task in the field of fashion technology, in which the aim is to create a collocated set of fashion items that complement a given set of items. Previous studies in this area have been limited to generating a unique set of fashion items based on a given set of items, without providing additional options to users. This lack of a diverse range of choices necessitates the development of a more versatile framework. However, when the task of generating collocated and diversified outfits is approached with multimodal image-to-image translation methods, it poses a challenging problem in terms of non-aligned image translation, which is hard to address with existing methods. In this research, we present FCBoost-Net, a new framework for outfit generation that leverages the power of pre-trained generative models to produce multiple collocated and diversified outfits. Initially, FCBoost-Net randomly synthesizes multiple sets of fashion items, and the compatibility of the synthesized sets is then improved in several rounds using a novel fashion compatibility booster. This approach was inspired by boosting algorithms and allows the performance to be gradually improved in multiple steps. Empirical evidence indicates that the proposed strategy can improve the fashion compatibility of randomly synthesized fashion items as well as maintain their diversity. Extensive experiments confirm the effectiveness of our proposed framework with respect to visual authenticity, diversity, and fashion compatibility.
BC-GAN: A Generative Adversarial Network for Synthesizing a Batch of Collocated Clothing
Feb 03, 2025



Collocated clothing synthesis using generative networks has become an emerging topic in the field of fashion intelligence, as it has significant potential economic value to increase revenue in the fashion industry. In previous studies, several works have attempted to synthesize visually-collocated clothing based on a given clothing item using generative adversarial networks (GANs) with promising results. These works, however, can only accomplish the synthesis of one collocated clothing item each time. Nevertheless, users may require different clothing items to meet their multiple choices due to their personal tastes and different dressing scenarios. To address this limitation, we introduce a novel batch clothing generation framework, named BC-GAN, which is able to synthesize multiple visually-collocated clothing images simultaneously. In particular, to further improve the fashion compatibility of synthetic results, BC-GAN proposes a new fashion compatibility discriminator in a contrastive learning perspective by fully exploiting the collocation relationship among all clothing items. Our model was examined in a large-scale dataset with compatible outfits constructed by ourselves. Extensive experiment results confirmed the effectiveness of our proposed BC-GAN in comparison to state-of-the-art methods in terms of diversity, visual authenticity, and fashion compatibility.
AVE Speech Dataset: A Comprehensive Benchmark for Multi-Modal Speech Recognition Integrating Audio, Visual, and Electromyographic Signals
Jan 28, 2025



The global aging population faces considerable challenges, particularly in communication, due to the prevalence of hearing and speech impairments. To address these, we introduce the AVE speech dataset, a comprehensive multi-modal benchmark for speech recognition tasks. The dataset includes a 100-sentence Mandarin Chinese corpus with audio signals, lip-region video recordings, and six-channel electromyography (EMG) data, collected from 100 participants. Each subject read the entire corpus ten times, with each sentence averaging approximately two seconds in duration, resulting in over 55 hours of multi-modal speech data per modality. Experiments demonstrate that combining these modalities significantly improves recognition performance, particularly in cross-subject and high-noise environments. To our knowledge, this is the first publicly available sentence-level dataset integrating these three modalities for large-scale Mandarin speech recognition. We expect this dataset to drive advancements in both acoustic and non-acoustic speech recognition research, enhancing cross-modal learning and human-machine interaction.
LipGen: Viseme-Guided Lip Video Generation for Enhancing Visual Speech Recognition
Jan 08, 2025



Visual speech recognition (VSR), commonly known as lip reading, has garnered significant attention due to its wide-ranging practical applications. The advent of deep learning techniques and advancements in hardware capabilities have significantly enhanced the performance of lip reading models. Despite these advancements, existing datasets predominantly feature stable video recordings with limited variability in lip movements. This limitation results in models that are highly sensitive to variations encountered in real-world scenarios. To address this issue, we propose a novel framework, LipGen, which aims to improve model robustness by leveraging speech-driven synthetic visual data, thereby mitigating the constraints of current datasets. Additionally, we introduce an auxiliary task that incorporates viseme classification alongside attention mechanisms. This approach facilitates the efficient integration of temporal information, directing the model's focus toward the relevant segments of speech, thereby enhancing discriminative capabilities. Our method demonstrates superior performance compared to the current state-of-the-art on the lip reading in the wild (LRW) dataset and exhibits even more pronounced advantages under challenging conditions.
Safe-VLN: Collision Avoidance for Vision-and-Language Navigation of Autonomous Robots Operating in Continuous Environments
Nov 06, 2023
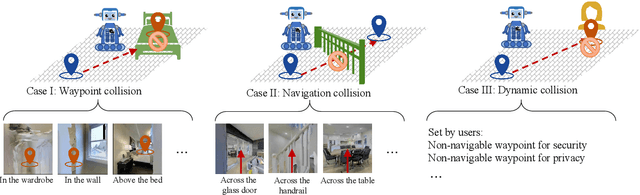
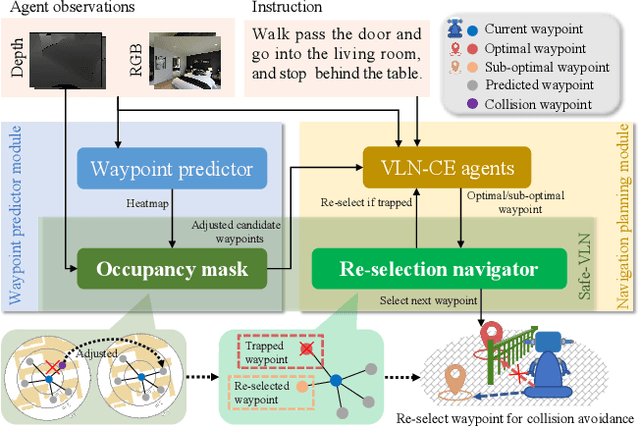

The task of vision-and-language navigation in continuous environments (VLN-CE) aims at training an autonomous agent to perform low-level actions to navigate through 3D continuous surroundings using visual observations and language instructions. The significant potential of VLN-CE for mobile robots has been demonstrated across a large number of studies. However, most existing works in VLN-CE focus primarily on transferring the standard discrete vision-and-language navigation (VLN) methods to continuous environments, overlooking the problem of collisions. Such oversight often results in the agent deviating from the planned path or, in severe instances, the agent being trapped in obstacle areas and failing the navigational task. To address the above-mentioned issues, this paper investigates various collision scenarios within VLN-CE and proposes a classification method to predicate the underlying causes of collisions. Furthermore, a new VLN-CE algorithm, named Safe-VLN, is proposed to bolster collision avoidance capabilities including two key components, i.e., a waypoint predictor and a navigator. In particular, the waypoint predictor leverages a simulated 2D LiDAR occupancy mask to prevent the predicted waypoints from being situated in obstacle-ridden areas. The navigator, on the other hand, employs the strategy of `re-selection after collision' to prevent the robot agent from becoming ensnared in a cycle of perpetual collisions. The proposed Safe-VLN is evaluated on the R2R-CE, the results of which demonstrate an enhanced navigational performance and a statistically significant reduction in collision incidences.