 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBC-GAN: A Generative Adversarial Network for Synthesizing a Batch of Collocated Clothing
Feb 03, 2025



Collocated clothing synthesis using generative networks has become an emerging topic in the field of fashion intelligence, as it has significant potential economic value to increase revenue in the fashion industry. In previous studies, several works have attempted to synthesize visually-collocated clothing based on a given clothing item using generative adversarial networks (GANs) with promising results. These works, however, can only accomplish the synthesis of one collocated clothing item each time. Nevertheless, users may require different clothing items to meet their multiple choices due to their personal tastes and different dressing scenarios. To address this limitation, we introduce a novel batch clothing generation framework, named BC-GAN, which is able to synthesize multiple visually-collocated clothing images simultaneously. In particular, to further improve the fashion compatibility of synthetic results, BC-GAN proposes a new fashion compatibility discriminator in a contrastive learning perspective by fully exploiting the collocation relationship among all clothing items. Our model was examined in a large-scale dataset with compatible outfits constructed by ourselves. Extensive experiment results confirmed the effectiveness of our proposed BC-GAN in comparison to state-of-the-art methods in terms of diversity, visual authenticity, and fashion compatibility.
GiVE: Guiding Visual Encoder to Perceive Overlooked Information
Oct 26, 2024Multimodal Large Language Models have advanced AI in applications like text-to-video generation and visual question answering. These models rely on visual encoders to convert non-text data into vectors, but current encoders either lack semantic alignment or overlook non-salient objects. We propose the Guiding Visual Encoder to Perceive Overlooked Information (GiVE) approach. GiVE enhances visual representation with an Attention-Guided Adapter (AG-Adapter) module and an Object-focused Visual Semantic Learning module. These incorporate three novel loss terms: Object-focused Image-Text Contrast (OITC) loss, Object-focused Image-Image Contrast (OIIC) loss, and Object-focused Image Discrimination (OID) loss, improving object consideration, retrieval accuracy, and comprehensiveness. Our contributions include dynamic visual focus adjustment, novel loss functions to enhance object retrieval, and the Multi-Object Instruction (MOInst) dataset. Experiments show our approach achieves state-of-the-art performance.
Edge-guided inverse design of digital metamaterials for ultra-high-capacity on-chip multi-dimensional interconnect
Oct 10, 2024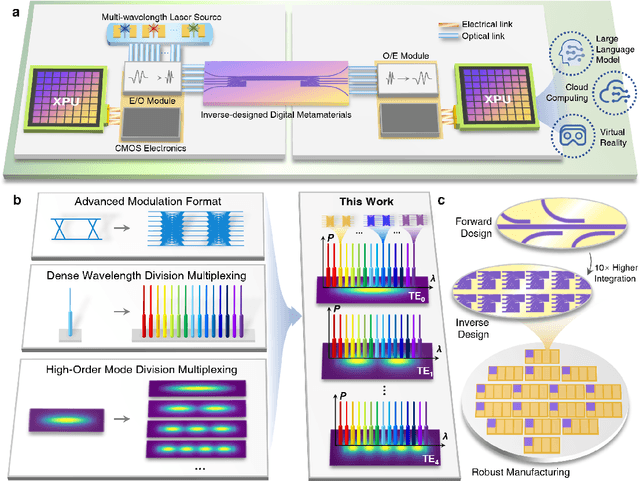
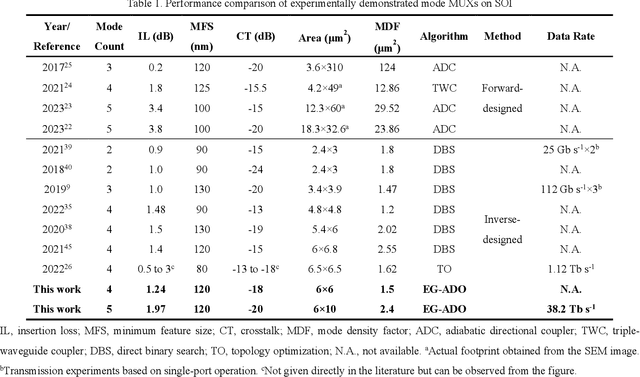
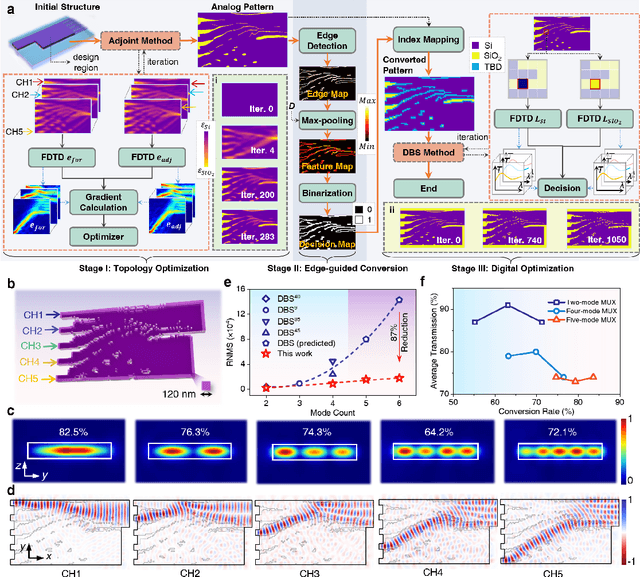
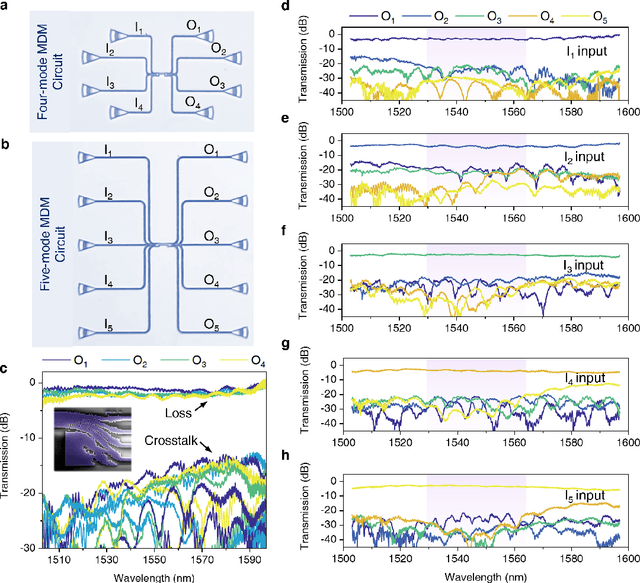
The escalating demands of compute-intensive applications, including artificial intelligence, urgently necessitate the adoption of sophisticated optical on-chip interconnect technologies to overcome critical bottlenecks in scaling future computing systems. This transition requires leveraging the inherent parallelism of wavelength and mode dimensions of light, complemented by high-order modulation formats, to significantly enhance data throughput. Here we experimentally demonstrate a novel synergy of these three dimensions, achieving multi-tens-of-terabits-per-second on-chip interconnects using ultra-broadband, multi-mode digital metamaterials. Employing a highly efficient edge-guided analog-and-digital optimization method, we inversely design foundry-compatible, robust, and multi-port digital metamaterials with an 8xhigher computational efficiency. Using a packaged five-mode multiplexing chip, we demonstrate a single-wavelength interconnect capacity of 1.62 Tbit s-1 and a record-setting multi-dimensional interconnect capacity of 38.2 Tbit s-1 across 5 modes and 88 wavelength channels. A theoretical analysis suggests that further system optimization can enable on-chip interconnects to reach sub-petabit-per-second data transmission rates. This study highlights the transformative potential of optical interconnect technologies to surmount the constraints of electronic links, thus setting the stage for next-generation datacenter and optical compute interconnects.
Vision Reimagined: AI-Powered Breakthroughs in WiFi Indoor Imaging
Jan 09, 2024Indoor imaging is a critical task for robotics and internet-of-things. WiFi as an omnipresent signal is a promising candidate for carrying out passive imaging and synchronizing the up-to-date information to all connected devices. This is the first research work to consider WiFi indoor imaging as a multi-modal image generation task that converts the measured WiFi power into a high-resolution indoor image. Our proposed WiFi-GEN network achieves a shape reconstruction accuracy that is 275% of that achieved by physical model-based inversion methods. Additionally, the Frechet Inception Distance score has been significantly reduced by 82%. To examine the effectiveness of models for this task, the first large-scale dataset is released containing 80,000 pairs of WiFi signal and imaging target. Our model absorbs challenges for the model-based methods including the non-linearity, ill-posedness and non-certainty into massive parameters of our generative AI network. The network is also designed to best fit measured WiFi signals and the desired imaging output. For reproducibility, we will release the data and code upon acceptance.