 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexTac: Learning Contact-aware Visuotactile Policies via Hand-by-hand Teaching
Jan 29, 2026For contact-intensive tasks, the ability to generate policies that produce comprehensive tactile-aware motions is essential. However, existing data collection and skill learning systems for dexterous manipulation often suffer from low-dimensional tactile information. To address this limitation, we propose DexTac, a visuo-tactile manipulation learning framework based on kinesthetic teaching. DexTac captures multi-dimensional tactile data-including contact force distributions and spatial contact regions-directly from human demonstrations. By integrating these rich tactile modalities into a policy network, the resulting contact-aware agent enables a dexterous hand to autonomously select and maintain optimal contact regions during complex interactions. We evaluate our framework on a challenging unimanual injection task. Experimental results demonstrate that DexTac achieves a 91.67% success rate. Notably, in high-precision scenarios involving small-scale syringes, our approach outperforms force-only baselines by 31.67%. These results underscore that learning multi-dimensional tactile priors from human demonstrations is critical for achieving robust, human-like dexterous manipulation in contact-rich environments.
Purification Before Fusion: Toward Mask-Free Speech Enhancement for Robust Audio-Visual Speech Recognition
Jan 18, 2026Audio-visual speech recognition (AVSR) typically improves recognition accuracy in noisy environments by integrating noise-immune visual cues with audio signals. Nevertheless, high-noise audio inputs are prone to introducing adverse interference into the feature fusion process. To mitigate this, recent AVSR methods often adopt mask-based strategies to filter audio noise during feature interaction and fusion, yet such methods risk discarding semantically relevant information alongside noise. In this work, we propose an end-to-end noise-robust AVSR framework coupled with speech enhancement, eliminating the need for explicit noise mask generation. This framework leverages a Conformer-based bottleneck fusion module to implicitly refine noisy audio features with video assistance. By reducing modality redundancy and enhancing inter-modal interactions, our method preserves speech semantic integrity to achieve robust recognition performance. Experimental evaluations on the public LRS3 benchmark suggest that our method outperforms prior advanced mask-based baselines under noisy conditions.
Causality-Aware Temporal Projection for Video Understanding in Video-LLMs
Jan 05, 2026Recent Video Large Language Models (Video-LLMs) have shown strong multimodal reasoning capabilities, yet remain challenged by video understanding tasks that require consistent temporal ordering and causal coherence. Many parameter-efficient Video-LLMs rely on unconstrained bidirectional projectors to model inter-frame interactions, which can blur temporal ordering by allowing later frames to influence earlier representations, without explicit architectural mechanisms to respect the directional nature of video reasoning. To address this limitation, we propose V-CORE, a parameter-efficient framework that introduces explicit temporal ordering constraints for video understanding. V-CORE consists of two key components: (1) Learnable Spatial Aggregation (LSA), which adaptively selects salient spatial tokens to reduce redundancy, and (2) a Causality-Aware Temporal Projector (CATP), which enforces structured unidirectional information flow via block-causal attention and a terminal dynamic summary token acting as a causal sink. This design preserves intra-frame spatial interactions while ensuring that temporal information is aggregated in a strictly ordered manner. With 4-bit QLoRA and a frozen LLM backbone, V-CORE can be trained efficiently on a single consumer GPU. Experiments show that V-CORE achieves strong performance on the challenging NExT-QA benchmark, reaching 61.2% accuracy, and remains competitive across MSVD-QA, MSRVTT-QA, and TGIF-QA, with gains concentrated in temporal and causal reasoning subcategories (+3.5% and +5.2% respectively), directly validating the importance of explicit temporal ordering constraints.
Cross-platform Product Matching Based on Entity Alignment of Knowledge Graph with RAEA model
Dec 08, 2025Product matching aims to identify identical or similar products sold on different platforms. By building knowledge graphs (KGs), the product matching problem can be converted to the Entity Alignment (EA) task, which aims to discover the equivalent entities from diverse KGs. The existing EA methods inadequately utilize both attribute triples and relation triples simultaneously, especially the interactions between them. This paper introduces a two-stage pipeline consisting of rough filter and fine filter to match products from eBay and Amazon. For fine filtering, a new framework for Entity Alignment, Relation-aware and Attribute-aware Graph Attention Networks for Entity Alignment (RAEA), is employed. RAEA focuses on the interactions between attribute triples and relation triples, where the entity representation aggregates the alignment signals from attributes and relations with Attribute-aware Entity Encoder and Relation-aware Graph Attention Networks. The experimental results indicate that the RAEA model achieves significant improvements over 12 baselines on EA task in the cross-lingual dataset DBP15K (6.59% on average Hits@1) and delivers competitive results in the monolingual dataset DWY100K. The source code for experiments on DBP15K and DWY100K is available at github (https://github.com/Mockingjay-liu/RAEA-model-for-Entity-Alignment).
* 10 pages, 5 figures, published on World Wide Web
Beyond ReAct: A Planner-Centric Framework for Complex Tool-Augmented LLM Reasoning
Nov 13, 2025Existing tool-augmented large language models (LLMs) encounter significant challenges when processing complex queries. Current frameworks such as ReAct are prone to local optimization traps due to their reliance on incremental decision-making processes. To address these limitations, we propose a novel Planner-centric Plan-Execute paradigm that fundamentally resolves local optimization bottlenecks through architectural innovation. Central to our approach is a novel Planner model that performs global Directed Acyclic Graph (DAG) planning for complex queries, enabling optimized execution beyond conventional tool coordination. We also introduce ComplexTool-Plan, a large-scale benchmark dataset featuring complex queries that demand sophisticated multi-tool composition and coordination capabilities. Additionally, we develop a two-stage training methodology that integrates Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), systematically enhancing the Planner's tool selection accuracy and global planning awareness through structured DAG-based planning. When integrated with a capable executor, our framework achieves state-of-the-art performance on the StableToolBench benchmark for complex user queries, demonstrating superior end-to-end execution capabilities and robust handling of intricate multi-tool workflows.
CAIFormer: A Causal Informed Transformer for Multivariate Time Series Forecasting
May 22, 2025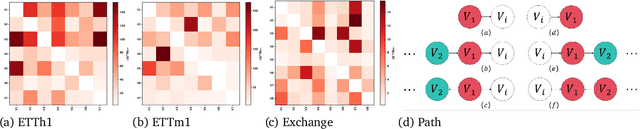

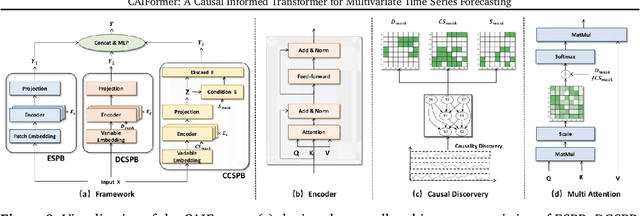

Most existing multivariate time series forecasting methods adopt an all-to-all paradigm that feeds all variable histories into a unified model to predict their future values without distinguishing their individual roles. However, this undifferentiated paradigm makes it difficult to identify variable-specific causal influences and often entangles causally relevant information with spurious correlations. To address this limitation, we propose an all-to-one forecasting paradigm that predicts each target variable separately. Specifically, we first construct a Structural Causal Model from observational data and then, for each target variable, we partition the historical sequence into four sub-segments according to the inferred causal structure: endogenous, direct causal, collider causal, and spurious correlation. The prediction relies solely on the first three causally relevant sub-segments, while the spurious correlation sub-segment is excluded. Furthermore, we propose Causal Informed Transformer (CAIFormer), a novel forecasting model comprising three components: Endogenous Sub-segment Prediction Block, Direct Causal Sub-segment Prediction Block, and Collider Causal Sub-segment Prediction Block, which process the endogenous, direct causal, and collider causal sub-segments, respectively. Their outputs are then combined to produce the final prediction. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of the CAIFormer.
SLOT: Sample-specific Language Model Optimization at Test-time
May 18, 2025We propose SLOT (Sample-specific Language Model Optimization at Test-time), a novel and parameter-efficient test-time inference approach that enhances a language model's ability to more accurately respond to individual prompts. Existing Large Language Models (LLMs) often struggle with complex instructions, leading to poor performances on those not well represented among general samples. To address this, SLOT conducts few optimization steps at test-time to update a light-weight sample-specific parameter vector. It is added to the final hidden layer before the output head, and enables efficient adaptation by caching the last layer features during per-sample optimization. By minimizing the cross-entropy loss on the input prompt only, SLOT helps the model better aligned with and follow each given instruction. In experiments, we demonstrate that our method outperforms the compared models across multiple benchmarks and LLMs. For example, Qwen2.5-7B with SLOT achieves an accuracy gain of 8.6% on GSM8K from 57.54% to 66.19%, while DeepSeek-R1-Distill-Llama-70B with SLOT achieves a SOTA accuracy of 68.69% on GPQA among 70B-level models. Our code is available at https://github.com/maple-research-lab/SLOT.
GoalFlow: Goal-Driven Flow Matching for Multimodal Trajectories Generation in End-to-End Autonomous Driving
Mar 07, 2025We propose GoalFlow, an end-to-end autonomous driving method for generating high-quality multimodal trajectories. In autonomous driving scenarios, there is rarely a single suitable trajectory. Recent methods have increasingly focused on modeling multimodal trajectory distributions. However, they suffer from trajectory selection complexity and reduced trajectory quality due to high trajectory divergence and inconsistencies between guidance and scene information. To address these issues, we introduce GoalFlow, a novel method that effectively constrains the generative process to produce high-quality, multimodal trajectories. To resolve the trajectory divergence problem inherent in diffusion-based methods, GoalFlow constrains the generated trajectories by introducing a goal point. GoalFlow establishes a novel scoring mechanism that selects the most appropriate goal point from the candidate points based on scene information. Furthermore, GoalFlow employs an efficient generative method, Flow Matching, to generate multimodal trajectories, and incorporates a refined scoring mechanism to select the optimal trajectory from the candidates. Our experimental results, validated on the Navsim\cite{Dauner2024_navsim}, demonstrate that GoalFlow achieves state-of-the-art performance, delivering robust multimodal trajectories for autonomous driving. GoalFlow achieved PDMS of 90.3, significantly surpassing other methods. Compared with other diffusion-policy-based methods, our approach requires only a single denoising step to obtain excellent performance. The code is available at https://github.com/YvanYin/GoalFlow.
Don't Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Mar 05, 2025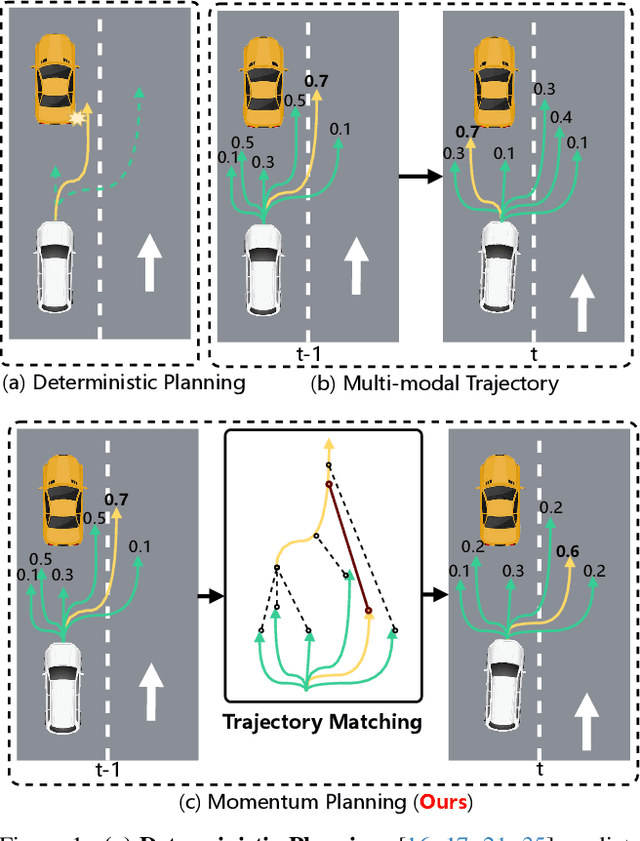


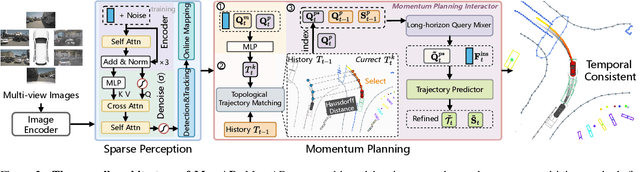
End-to-end autonomous driving frameworks enable seamless integration of perception and planning but often rely on one-shot trajectory prediction, which may lead to unstable control and vulnerability to occlusions in single-frame perception. To address this, we propose the Momentum-Aware Driving (MomAD) framework, which introduces trajectory momentum and perception momentum to stabilize and refine trajectory predictions. MomAD comprises two core components: (1) Topological Trajectory Matching (TTM) employs Hausdorff Distance to select the optimal planning query that aligns with prior paths to ensure coherence;(2) Momentum Planning Interactor (MPI) cross-attends the selected planning query with historical queries to expand static and dynamic perception files. This enriched query, in turn, helps regenerate long-horizon trajectory and reduce collision risks. To mitigate noise arising from dynamic environments and detection errors, we introduce robust instance denoising during training, enabling the planning model to focus on critical signals and improve its robustness. We also propose a novel Trajectory Prediction Consistency (TPC) metric to quantitatively assess planning stability. Experiments on the nuScenes dataset demonstrate that MomAD achieves superior long-term consistency (>=3s) compared to SOTA methods. Moreover, evaluations on the curated Turning-nuScenes shows that MomAD reduces the collision rate by 26% and improves TPC by 0.97m (33.45%) over a 6s prediction horizon, while closedloop on Bench2Drive demonstrates an up to 16.3% improvement in success rate.
AVE Speech Dataset: A Comprehensive Benchmark for Multi-Modal Speech Recognition Integrating Audio, Visual, and Electromyographic Signals
Jan 28, 2025



The global aging population faces considerable challenges, particularly in communication, due to the prevalence of hearing and speech impairments. To address these, we introduce the AVE speech dataset, a comprehensive multi-modal benchmark for speech recognition tasks. The dataset includes a 100-sentence Mandarin Chinese corpus with audio signals, lip-region video recordings, and six-channel electromyography (EMG) data, collected from 100 participants. Each subject read the entire corpus ten times, with each sentence averaging approximately two seconds in duration, resulting in over 55 hours of multi-modal speech data per modality. Experiments demonstrate that combining these modalities significantly improves recognition performance, particularly in cross-subject and high-noise environments. To our knowledge, this is the first publicly available sentence-level dataset integrating these three modalities for large-scale Mandarin speech recognition. We expect this dataset to drive advancements in both acoustic and non-acoustic speech recognition research, enhancing cross-modal learning and human-machine interaction.