 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVILTA: A VLM-in-the-Loop Adversary for Enhancing Driving Policy Robustness
Jan 19, 2026The safe deployment of autonomous driving (AD) systems is fundamentally hindered by the long-tail problem, where rare yet critical driving scenarios are severely underrepresented in real-world data. Existing solutions including safety-critical scenario generation and closed-loop learning often rely on rule-based heuristics, resampling methods and generative models learned from offline datasets, limiting their ability to produce diverse and novel challenges. While recent works leverage Vision Language Models (VLMs) to produce scene descriptions that guide a separate, downstream model in generating hazardous trajectories for agents, such two-stage framework constrains the generative potential of VLMs, as the diversity of the final trajectories is ultimately limited by the generalization ceiling of the downstream algorithm. To overcome these limitations, we introduce VILTA (VLM-In-the-Loop Trajectory Adversary), a novel framework that integrates a VLM into the closed-loop training of AD agents. Unlike prior works, VILTA actively participates in the training loop by comprehending the dynamic driving environment and strategically generating challenging scenarios through direct, fine-grained editing of surrounding agents' future trajectories. This direct-editing approach fully leverages the VLM's powerful generalization capabilities to create a diverse curriculum of plausible yet challenging scenarios that extend beyond the scope of traditional methods. We demonstrate that our approach substantially enhances the safety and robustness of the resulting AD policy, particularly in its ability to navigate critical long-tail events.
DVGT: Driving Visual Geometry Transformer
Dec 18, 2025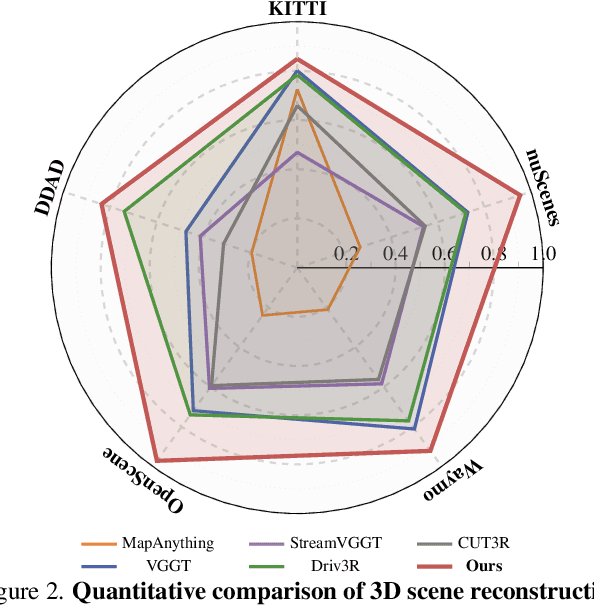
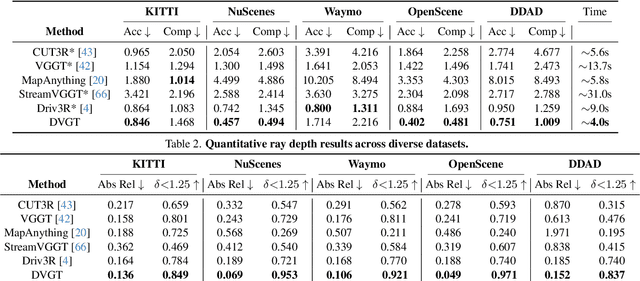
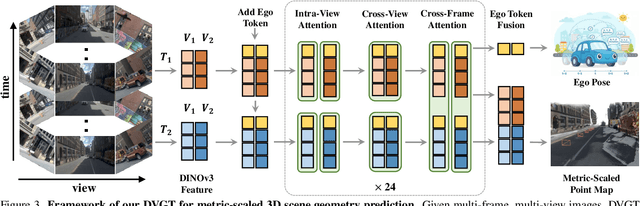
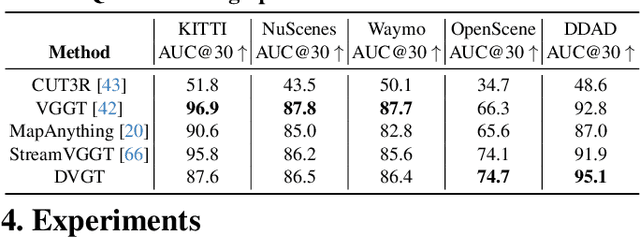
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
DGFusion: Dual-guided Fusion for Robust Multi-Modal 3D Object Detection
Nov 13, 2025As a critical task in autonomous driving perception systems, 3D object detection is used to identify and track key objects, such as vehicles and pedestrians. However, detecting distant, small, or occluded objects (hard instances) remains a challenge, which directly compromises the safety of autonomous driving systems. We observe that existing multi-modal 3D object detection methods often follow a single-guided paradigm, failing to account for the differences in information density of hard instances between modalities. In this work, we propose DGFusion, based on the Dual-guided paradigm, which fully inherits the advantages of the Point-guide-Image paradigm and integrates the Image-guide-Point paradigm to address the limitations of the single paradigms. The core of DGFusion, the Difficulty-aware Instance Pair Matcher (DIPM), performs instance-level feature matching based on difficulty to generate easy and hard instance pairs, while the Dual-guided Modules exploit the advantages of both pair types to enable effective multi-modal feature fusion. Experimental results demonstrate that our DGFusion outperforms the baseline methods, with respective improvements of +1.0\% mAP, +0.8\% NDS, and +1.3\% average recall on nuScenes. Extensive experiments demonstrate consistent robustness gains for hard instance detection across ego-distance, size, visibility, and small-scale training scenarios.
FPC-VLA: A Vision-Language-Action Framework with a Supervisor for Failure Prediction and Correction
Sep 04, 2025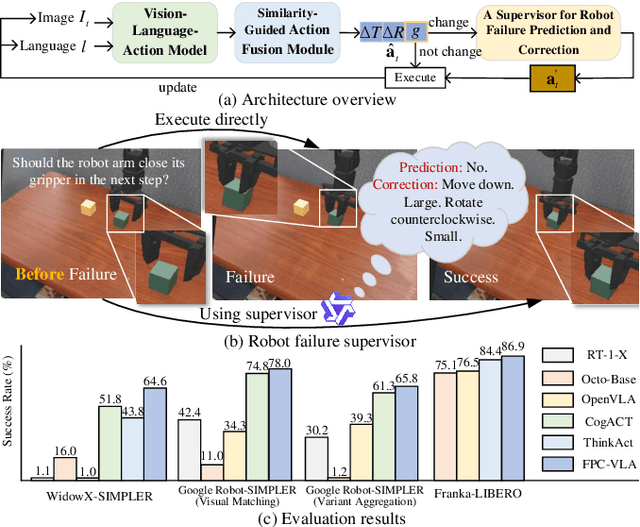
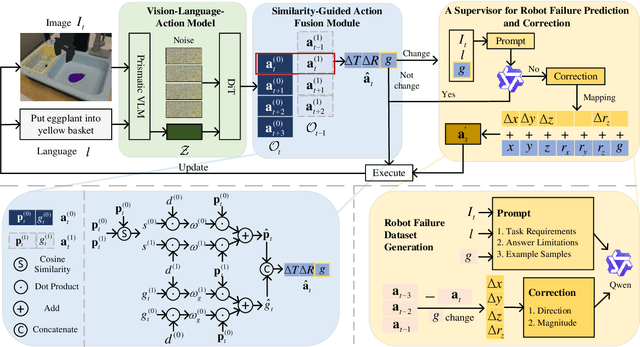


Robotic manipulation is a fundamental component of automation. However, traditional perception-planning pipelines often fall short in open-ended tasks due to limited flexibility, while the architecture of a single end-to-end Vision-Language-Action (VLA) offers promising capabilities but lacks crucial mechanisms for anticipating and recovering from failure. To address these challenges, we propose FPC-VLA, a dual-model framework that integrates VLA with a supervisor for failure prediction and correction. The supervisor evaluates action viability through vision-language queries and generates corrective strategies when risks arise, trained efficiently without manual labeling. A similarity-guided fusion module further refines actions by leveraging past predictions. Evaluation results on multiple simulation platforms (SIMPLER and LIBERO) and robot embodiments (WidowX, Google Robot, Franka) show that FPC-VLA outperforms state-of-the-art models in both zero-shot and fine-tuned settings. By activating the supervisor only at keyframes, our approach significantly increases task success rates with minimal impact on execution time. Successful real-world deployments on diverse, long-horizon tasks confirm FPC-VLA's strong generalization and practical utility for building more reliable autonomous systems.
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Jun 09, 2025We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
Don't Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Mar 05, 2025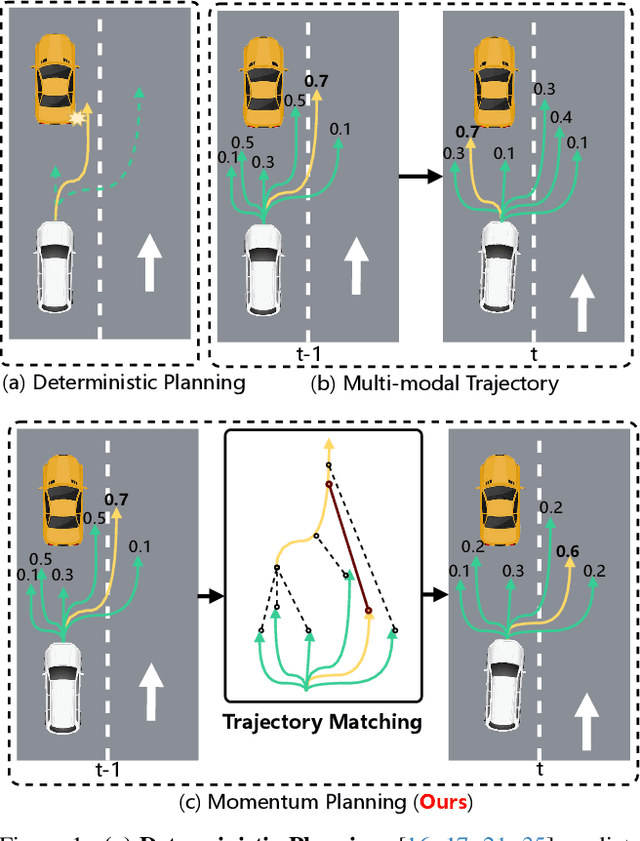


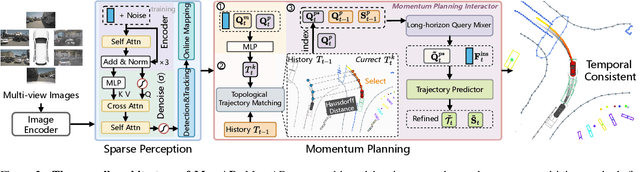
End-to-end autonomous driving frameworks enable seamless integration of perception and planning but often rely on one-shot trajectory prediction, which may lead to unstable control and vulnerability to occlusions in single-frame perception. To address this, we propose the Momentum-Aware Driving (MomAD) framework, which introduces trajectory momentum and perception momentum to stabilize and refine trajectory predictions. MomAD comprises two core components: (1) Topological Trajectory Matching (TTM) employs Hausdorff Distance to select the optimal planning query that aligns with prior paths to ensure coherence;(2) Momentum Planning Interactor (MPI) cross-attends the selected planning query with historical queries to expand static and dynamic perception files. This enriched query, in turn, helps regenerate long-horizon trajectory and reduce collision risks. To mitigate noise arising from dynamic environments and detection errors, we introduce robust instance denoising during training, enabling the planning model to focus on critical signals and improve its robustness. We also propose a novel Trajectory Prediction Consistency (TPC) metric to quantitatively assess planning stability. Experiments on the nuScenes dataset demonstrate that MomAD achieves superior long-term consistency (>=3s) compared to SOTA methods. Moreover, evaluations on the curated Turning-nuScenes shows that MomAD reduces the collision rate by 26% and improves TPC by 0.97m (33.45%) over a 6s prediction horizon, while closedloop on Bench2Drive demonstrates an up to 16.3% improvement in success rate.
TiGDistill-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning Distillation
Dec 30, 2024



Accurate multi-view 3D object detection is essential for applications such as autonomous driving. Researchers have consistently aimed to leverage LiDAR's precise spatial information to enhance camera-based detectors through methods like depth supervision and bird-eye-view (BEV) feature distillation. However, existing approaches often face challenges due to the inherent differences between LiDAR and camera data representations. In this paper, we introduce the TiGDistill-BEV, a novel approach that effectively bridges this gap by leveraging the strengths of both sensors. Our method distills knowledge from diverse modalities(e.g., LiDAR) as the teacher model to a camera-based student detector, utilizing the Target Inner-Geometry learning scheme to enhance camera-based BEV detectors through both depth and BEV features by leveraging diverse modalities. Specially, we propose two key modules: an inner-depth supervision module to learn the low-level relative depth relations within objects which equips detectors with a deeper understanding of object-level spatial structures, and an inner-feature BEV distillation module to transfer high-level semantics of different key points within foreground targets. To further alleviate the domain gap, we incorporate both inter-channel and inter-keypoint distillation to model feature similarity. Extensive experiments on the nuScenes benchmark demonstrate that TiGDistill-BEV significantly boosts camera-based only detectors achieving a state-of-the-art with 62.8% NDS and surpassing previous methods by a significant margin. The codes is available at: https://github.com/Public-BOTs/TiGDistill-BEV.git.
GaussianPretrain: A Simple Unified 3D Gaussian Representation for Visual Pre-training in Autonomous Driving
Nov 19, 2024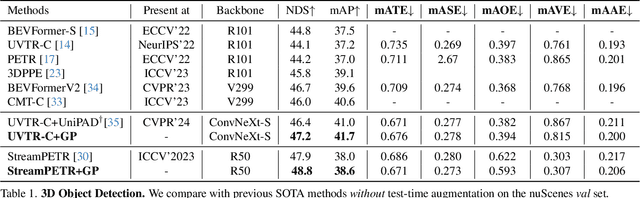
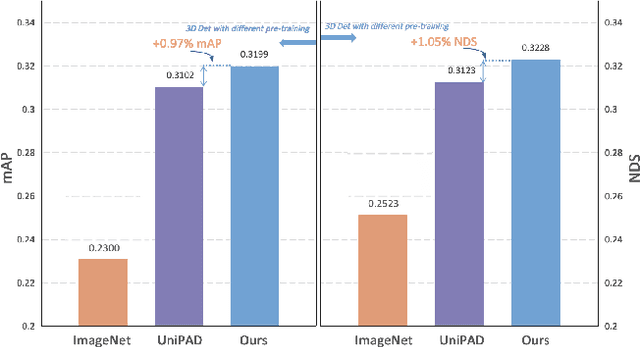
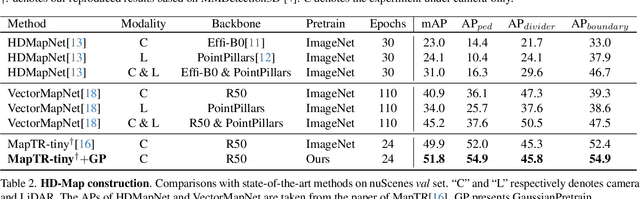
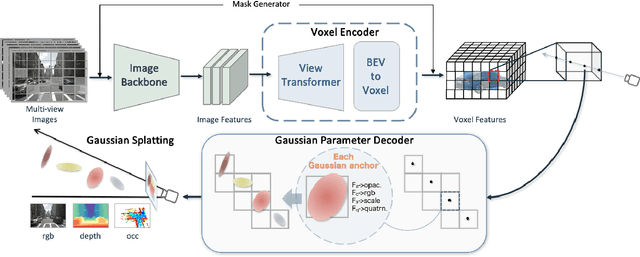
Self-supervised learning has made substantial strides in image processing, while visual pre-training for autonomous driving is still in its infancy. Existing methods often focus on learning geometric scene information while neglecting texture or treating both aspects separately, hindering comprehensive scene understanding. In this context, we are excited to introduce GaussianPretrain, a novel pre-training paradigm that achieves a holistic understanding of the scene by uniformly integrating geometric and texture representations. Conceptualizing 3D Gaussian anchors as volumetric LiDAR points, our method learns a deepened understanding of scenes to enhance pre-training performance with detailed spatial structure and texture, achieving that 40.6% faster than NeRF-based method UniPAD with 70% GPU memory only. We demonstrate the effectiveness of GaussianPretrain across multiple 3D perception tasks, showing significant performance improvements, such as a 7.05% increase in NDS for 3D object detection, boosts mAP by 1.9% in HD map construction and 0.8% improvement on Occupancy prediction. These significant gains highlight GaussianPretrain's theoretical innovation and strong practical potential, promoting visual pre-training development for autonomous driving. Source code will be available at https://github.com/Public-BOTs/GaussianPretrain
GraphBEV: Towards Robust BEV Feature Alignment for Multi-Modal 3D Object Detection
Mar 18, 2024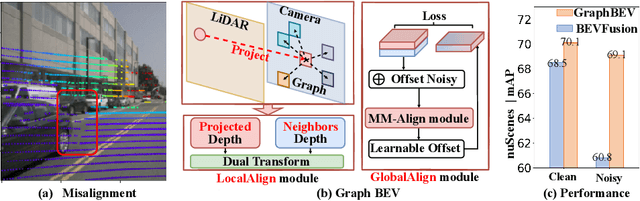
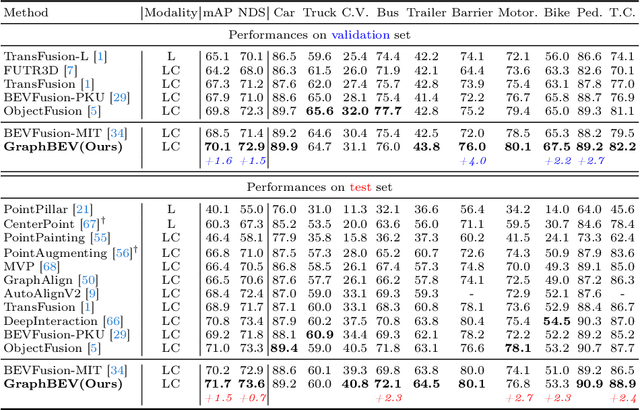
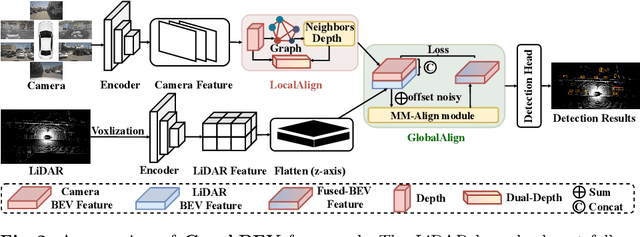
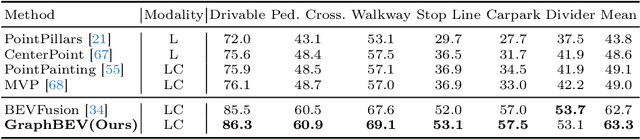
Integrating LiDAR and camera information into Bird's-Eye-View (BEV) representation has emerged as a crucial aspect of 3D object detection in autonomous driving. However, existing methods are susceptible to the inaccurate calibration relationship between LiDAR and the camera sensor. Such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a robust fusion framework called Graph BEV. Addressing errors caused by inaccurate point cloud projection, we introduce a Local Align module that employs neighbor-aware depth features via Graph matching. Additionally, we propose a Global Align module to rectify the misalignment between LiDAR and camera BEV features. Our Graph BEV framework achieves state-of-the-art performance, with an mAP of 70.1\%, surpassing BEV Fusion by 1.6\% on the nuscenes validation set. Importantly, our Graph BEV outperforms BEV Fusion by 8.3\% under conditions with misalignment noise.
RoboFusion: Towards Robust Multi-Modal 3D obiect Detection via SAM
Jan 08, 2024



Multi-modal 3D object detectors are dedicated to exploring secure and reliable perception systems for autonomous driving (AD). However, while achieving state-of-the-art (SOTA) performance on clean benchmark datasets, they tend to overlook the complexity and harsh conditions of real-world environments. Meanwhile, with the emergence of visual foundation models (VFMs), opportunities and challenges are presented for improving the robustness and generalization of multi-modal 3D object detection in autonomous driving. Therefore, we propose RoboFusion, a robust framework that leverages VFMs like SAM to tackle out-of-distribution (OOD) noise scenarios. We first adapt the original SAM for autonomous driving scenarios named SAM-AD. To align SAM or SAM-AD with multi-modal methods, we then introduce AD-FPN for upsampling the image features extracted by SAM. We employ wavelet decomposition to denoise the depth-guided images for further noise reduction and weather interference. Lastly, we employ self-attention mechanisms to adaptively reweight the fused features, enhancing informative features while suppressing excess noise. In summary, our RoboFusion gradually reduces noise by leveraging the generalization and robustness of VFMs, thereby enhancing the resilience of multi-modal 3D object detection. Consequently, our RoboFusion achieves state-of-the-art performance in noisy scenarios, as demonstrated by the KITTI-C and nuScenes-C benchmarks.