 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiGDistill-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning Distillation
Dec 30, 2024



Accurate multi-view 3D object detection is essential for applications such as autonomous driving. Researchers have consistently aimed to leverage LiDAR's precise spatial information to enhance camera-based detectors through methods like depth supervision and bird-eye-view (BEV) feature distillation. However, existing approaches often face challenges due to the inherent differences between LiDAR and camera data representations. In this paper, we introduce the TiGDistill-BEV, a novel approach that effectively bridges this gap by leveraging the strengths of both sensors. Our method distills knowledge from diverse modalities(e.g., LiDAR) as the teacher model to a camera-based student detector, utilizing the Target Inner-Geometry learning scheme to enhance camera-based BEV detectors through both depth and BEV features by leveraging diverse modalities. Specially, we propose two key modules: an inner-depth supervision module to learn the low-level relative depth relations within objects which equips detectors with a deeper understanding of object-level spatial structures, and an inner-feature BEV distillation module to transfer high-level semantics of different key points within foreground targets. To further alleviate the domain gap, we incorporate both inter-channel and inter-keypoint distillation to model feature similarity. Extensive experiments on the nuScenes benchmark demonstrate that TiGDistill-BEV significantly boosts camera-based only detectors achieving a state-of-the-art with 62.8% NDS and surpassing previous methods by a significant margin. The codes is available at: https://github.com/Public-BOTs/TiGDistill-BEV.git.
PathInsight: Instruction Tuning of Multimodal Datasets and Models for Intelligence Assisted Diagnosis in Histopathology
Aug 13, 2024



Pathological diagnosis remains the definitive standard for identifying tumors. The rise of multimodal large models has simplified the process of integrating image analysis with textual descriptions. Despite this advancement, the substantial costs associated with training and deploying these complex multimodal models, together with a scarcity of high-quality training datasets, create a significant divide between cutting-edge technology and its application in the clinical setting. We had meticulously compiled a dataset of approximately 45,000 cases, covering over 6 different tasks, including the classification of organ tissues, generating pathology report descriptions, and addressing pathology-related questions and answers. We have fine-tuned multimodal large models, specifically LLaVA, Qwen-VL, InternLM, with this dataset to enhance instruction-based performance. We conducted a qualitative assessment of the capabilities of the base model and the fine-tuned model in performing image captioning and classification tasks on the specific dataset. The evaluation results demonstrate that the fine-tuned model exhibits proficiency in addressing typical pathological questions. We hope that by making both our models and datasets publicly available, they can be valuable to the medical and research communities.
SCAAT: Improving Neural Network Interpretability via Saliency Constrained Adaptive Adversarial Training
Nov 10, 2023



Deep Neural Networks (DNNs) are expected to provide explanation for users to understand their black-box predictions. Saliency map is a common form of explanation illustrating the heatmap of feature attributions, but it suffers from noise in distinguishing important features. In this paper, we propose a model-agnostic learning method called Saliency Constrained Adaptive Adversarial Training (SCAAT) to improve the quality of such DNN interpretability. By constructing adversarial samples under the guidance of saliency map, SCAAT effectively eliminates most noise and makes saliency maps sparser and more faithful without any modification to the model architecture. We apply SCAAT to multiple DNNs and evaluate the quality of the generated saliency maps on various natural and pathological image datasets. Evaluations on different domains and metrics show that SCAAT significantly improves the interpretability of DNNs by providing more faithful saliency maps without sacrificing their predictive power.
Improving Vision-and-Language Reasoning via Spatial Relations Modeling
Nov 09, 2023Visual commonsense reasoning (VCR) is a challenging multi-modal task, which requires high-level cognition and commonsense reasoning ability about the real world. In recent years, large-scale pre-training approaches have been developed and promoted the state-of-the-art performance of VCR. However, the existing approaches almost employ the BERT-like objectives to learn multi-modal representations. These objectives motivated from the text-domain are insufficient for the excavation on the complex scenario of visual modality. Most importantly, the spatial distribution of the visual objects is basically neglected. To address the above issue, we propose to construct the spatial relation graph based on the given visual scenario. Further, we design two pre-training tasks named object position regression (OPR) and spatial relation classification (SRC) to learn to reconstruct the spatial relation graph respectively. Quantitative analysis suggests that the proposed method can guide the representations to maintain more spatial context and facilitate the attention on the essential visual regions for reasoning. We achieve the state-of-the-art results on VCR and two other vision-and-language reasoning tasks VQA, and NLVR.
Assessing and Enhancing Robustness of Deep Learning Models with Corruption Emulation in Digital Pathology
Oct 31, 2023



Deep learning in digital pathology brings intelligence and automation as substantial enhancements to pathological analysis, the gold standard of clinical diagnosis. However, multiple steps from tissue preparation to slide imaging introduce various image corruptions, making it difficult for deep neural network (DNN) models to achieve stable diagnostic results for clinical use. In order to assess and further enhance the robustness of the models, we analyze the physical causes of the full-stack corruptions throughout the pathological life-cycle and propose an Omni-Corruption Emulation (OmniCE) method to reproduce 21 types of corruptions quantified with 5-level severity. We then construct three OmniCE-corrupted benchmark datasets at both patch level and slide level and assess the robustness of popular DNNs in classification and segmentation tasks. Further, we explore to use the OmniCE-corrupted datasets as augmentation data for training and experiments to verify that the generalization ability of the models has been significantly enhanced.
What a Whole Slide Image Can Tell? Subtype-guided Masked Transformer for Pathological Image Captioning
Oct 31, 2023



Pathological captioning of Whole Slide Images (WSIs), though is essential in computer-aided pathological diagnosis, has rarely been studied due to the limitations in datasets and model training efficacy. In this paper, we propose a new paradigm Subtype-guided Masked Transformer (SGMT) for pathological captioning based on Transformers, which treats a WSI as a sequence of sparse patches and generates an overall caption sentence from the sequence. An accompanying subtype prediction is introduced into SGMT to guide the training process and enhance the captioning accuracy. We also present an Asymmetric Masked Mechansim approach to tackle the large size constraint of pathological image captioning, where the numbers of sequencing patches in SGMT are sampled differently in the training and inferring phases, respectively. Experiments on the PatchGastricADC22 dataset demonstrate that our approach effectively adapts to the task with a transformer-based model and achieves superior performance than traditional RNN-based methods. Our codes are to be made available for further research and development.
RenderOcc: Vision-Centric 3D Occupancy Prediction with 2D Rendering Supervision
Sep 18, 2023



3D occupancy prediction holds significant promise in the fields of robot perception and autonomous driving, which quantifies 3D scenes into grid cells with semantic labels. Recent works mainly utilize complete occupancy labels in 3D voxel space for supervision. However, the expensive annotation process and sometimes ambiguous labels have severely constrained the usability and scalability of 3D occupancy models. To address this, we present RenderOcc, a novel paradigm for training 3D occupancy models only using 2D labels. Specifically, we extract a NeRF-style 3D volume representation from multi-view images, and employ volume rendering techniques to establish 2D renderings, thus enabling direct 3D supervision from 2D semantics and depth labels. Additionally, we introduce an Auxiliary Ray method to tackle the issue of sparse viewpoints in autonomous driving scenarios, which leverages sequential frames to construct comprehensive 2D rendering for each object. To our best knowledge, RenderOcc is the first attempt to train multi-view 3D occupancy models only using 2D labels, reducing the dependence on costly 3D occupancy annotations. Extensive experiments demonstrate that RenderOcc achieves comparable performance to models fully supervised with 3D labels, underscoring the significance of this approach in real-world applications.
UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Jun 15, 2023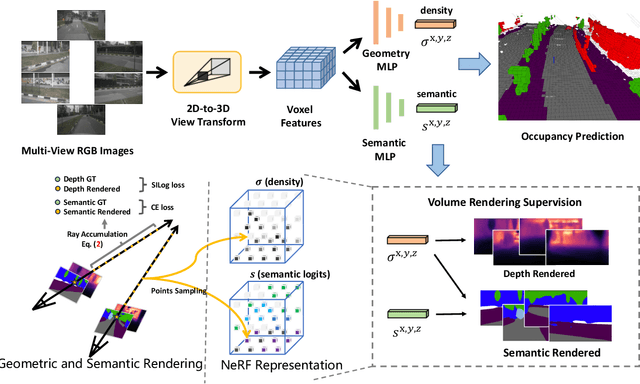
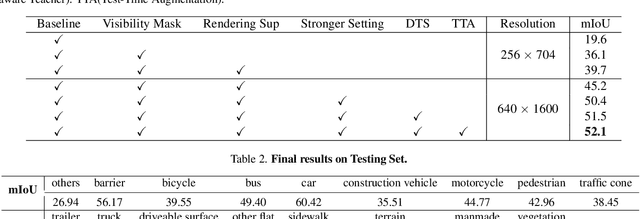
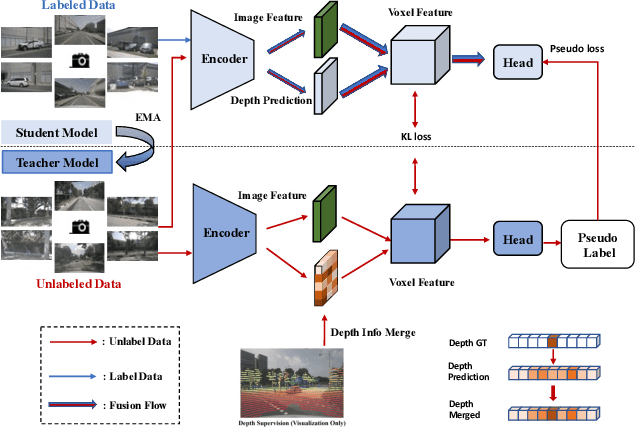

In this technical report, we present our solution, named UniOCC, for the Vision-Centric 3D occupancy prediction track in the nuScenes Open Dataset Challenge at CVPR 2023. Existing methods for occupancy prediction primarily focus on optimizing projected features on 3D volume space using 3D occupancy labels. However, the generation process of these labels is complex and expensive (relying on 3D semantic annotations), and limited by voxel resolution, they cannot provide fine-grained spatial semantics. To address this limitation, we propose a novel Unifying Occupancy (UniOcc) prediction method, explicitly imposing spatial geometry constraint and complementing fine-grained semantic supervision through volume ray rendering. Our method significantly enhances model performance and demonstrates promising potential in reducing human annotation costs. Given the laborious nature of annotating 3D occupancy, we further introduce a Depth-aware Teacher Student (DTS) framework to enhance prediction accuracy using unlabeled data. Our solution achieves 51.27\% mIoU on the official leaderboard with single model, placing 3rd in this challenge.
TiG-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning
Dec 28, 2022



To achieve accurate and low-cost 3D object detection, existing methods propose to benefit camera-based multi-view detectors with spatial cues provided by the LiDAR modality, e.g., dense depth supervision and bird-eye-view (BEV) feature distillation. However, they directly conduct point-to-point mimicking from LiDAR to camera, which neglects the inner-geometry of foreground targets and suffers from the modal gap between 2D-3D features. In this paper, we propose the learning scheme of Target Inner-Geometry from the LiDAR modality into camera-based BEV detectors for both dense depth and BEV features, termed as TiG-BEV. First, we introduce an inner-depth supervision module to learn the low-level relative depth relations between different foreground pixels. This enables the camera-based detector to better understand the object-wise spatial structures. Second, we design an inner-feature BEV distillation module to imitate the high-level semantics of different keypoints within foreground targets. To further alleviate the BEV feature gap between two modalities, we adopt both inter-channel and inter-keypoint distillation for feature-similarity modeling. With our target inner-geometry distillation, TiG-BEV can effectively boost BEVDepth by +2.3% NDS and +2.4% mAP, along with BEVDet by +9.1% NDS and +10.3% mAP on nuScenes val set. Code will be available at https://github.com/ADLab3Ds/TiG-BEV.