 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Mar 03, 2025


Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H\&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H\&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
A Multi-Modal Deep Learning Framework for Pan-Cancer Prognosis
Jan 13, 2025Prognostic task is of great importance as it closely related to the survival analysis of patients, the optimization of treatment plans and the allocation of resources. The existing prognostic models have shown promising results on specific datasets, but there are limitations in two aspects. On the one hand, they merely explore certain types of modal data, such as patient histopathology WSI and gene expression analysis. On the other hand, they adopt the per-cancer-per-model paradigm, which means the trained models can only predict the prognostic effect of a single type of cancer, resulting in weak generalization ability. In this paper, a deep-learning based model, named UMPSNet, is proposed. Specifically, to comprehensively understand the condition of patients, in addition to constructing encoders for histopathology images and genomic expression profiles respectively, UMPSNet further integrates four types of important meta data (demographic information, cancer type information, treatment protocols, and diagnosis results) into text templates, and then introduces a text encoder to extract textual features. In addition, the optimal transport OT-based attention mechanism is utilized to align and fuse features of different modalities. Furthermore, a guided soft mixture of experts (GMoE) mechanism is introduced to effectively address the issue of distribution differences among multiple cancer datasets. By incorporating the multi-modality of patient data and joint training, UMPSNet outperforms all SOTA approaches, and moreover, it demonstrates the effectiveness and generalization ability of the proposed learning paradigm of a single model for multiple cancer types. The code of UMPSNet is available at https://github.com/binging512/UMPSNet.
Now and Future of Artificial Intelligence-based Signet Ring Cell Diagnosis: A Survey
Nov 16, 2023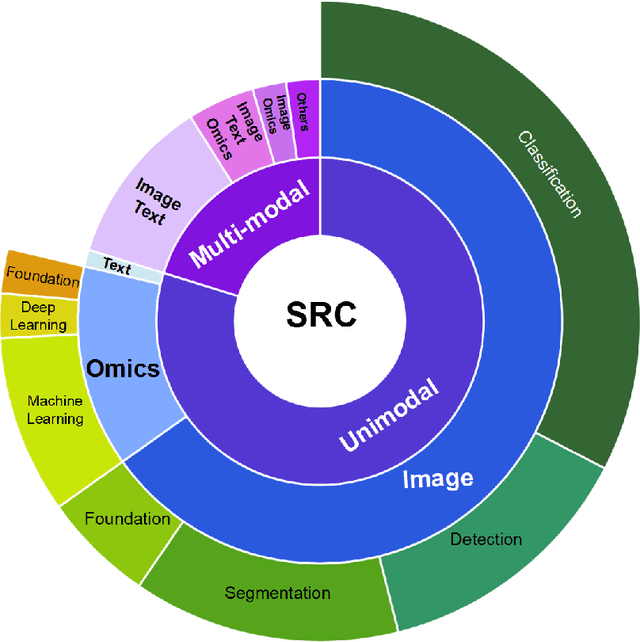
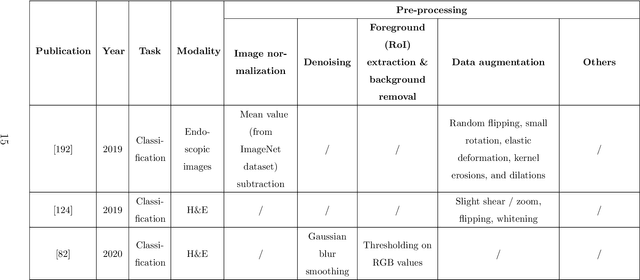
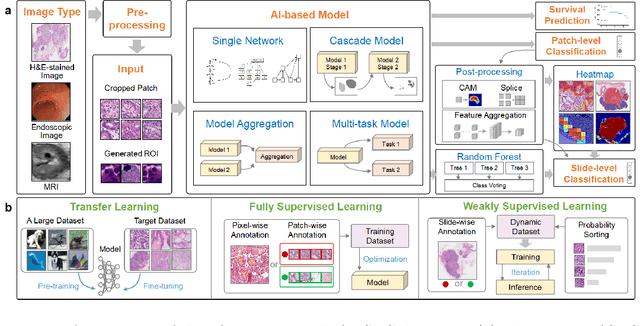
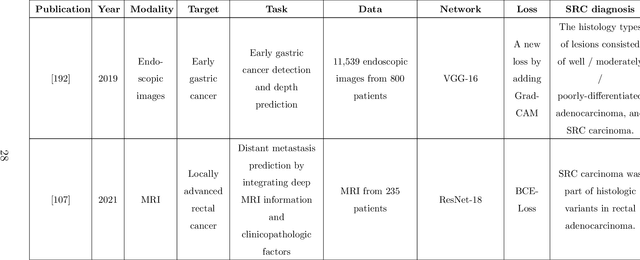
Since signet ring cells (SRCs) are associated with high peripheral metastasis rate and dismal survival, they play an important role in determining surgical approaches and prognosis, while they are easily missed by even experienced pathologists. Although automatic diagnosis SRCs based on deep learning has received increasing attention to assist pathologists in improving the diagnostic efficiency and accuracy, the existing works have not been systematically overviewed, which hindered the evaluation of the gap between algorithms and clinical applications. In this paper, we provide a survey on SRC analysis driven by deep learning from 2008 to August 2023. Specifically, the biological characteristics of SRCs and the challenges of automatic identification are systemically summarized. Then, the representative algorithms are analyzed and compared via dividing them into classification, detection, and segmentation. Finally, for comprehensive consideration to the performance of existing methods and the requirements for clinical assistance, we discuss the open issues and future trends of SRC analysis. The retrospect research will help researchers in the related fields, particularly for who without medical science background not only to clearly find the outline of SRC analysis, but also gain the prospect of intelligent diagnosis, resulting in accelerating the practice and application of intelligent algorithms.
Assessing and Enhancing Robustness of Deep Learning Models with Corruption Emulation in Digital Pathology
Oct 31, 2023



Deep learning in digital pathology brings intelligence and automation as substantial enhancements to pathological analysis, the gold standard of clinical diagnosis. However, multiple steps from tissue preparation to slide imaging introduce various image corruptions, making it difficult for deep neural network (DNN) models to achieve stable diagnostic results for clinical use. In order to assess and further enhance the robustness of the models, we analyze the physical causes of the full-stack corruptions throughout the pathological life-cycle and propose an Omni-Corruption Emulation (OmniCE) method to reproduce 21 types of corruptions quantified with 5-level severity. We then construct three OmniCE-corrupted benchmark datasets at both patch level and slide level and assess the robustness of popular DNNs in classification and segmentation tasks. Further, we explore to use the OmniCE-corrupted datasets as augmentation data for training and experiments to verify that the generalization ability of the models has been significantly enhanced.