 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathGLS: Evaluating Pathology Vision-Language Models without Ground Truth through Multi-Dimensional Consistency
Mar 17, 2026Vision-Language Models (VLMs) offer significant potential in computational pathology by enabling interpretable image analysis, automated reporting, and scalable decision support. However, their widespread clinical adoption remains limited due to the absence of reliable, automated evaluation metrics capable of identifying subtle failures such as hallucinations. To address this gap, we propose PathGLS, a novel reference-free evaluation framework that assesses pathology VLMs across three dimensions: Grounding (fine-grained visual-text alignment), Logic (entailment graph consistency using Natural Language Inference), and Stability (output variance under adversarial visual-semantic perturbations). PathGLS supports both patch-level and whole-slide image (WSI)-level analysis, yielding a comprehensive trust score. Experiments on Quilt-1M, TCGA, REG2025, PathMMU and TCGA-Sarcoma datasets demonstrate the superiority of PathGLS. Specifically, on the Quilt-1M dataset, PathGLS reveals a steep sensitivity drop of 40.2% for hallucinated reports compared to only 2.1% for BERTScore. Moreover, validation against expert-defined clinical error hierarchies reveals that PathGLS achieves a strong Spearman's rank correlation of $ρ=0.71$ ($p < 0.0001$), significantly outperforming Large Language Model (LLM)-based approaches (Gemini 3.0 Pro: $ρ=0.39$, $p < 0.0001$). These results establish PathGLS as a robust reference-free metric. By directly quantifying hallucination rates and domain shift robustness, it serves as a reliable criterion for benchmarking VLMs on private clinical datasets and informing safe deployment. Code can be found at: https://github.com/My13ad/PathGLS
Robust LLM-based Audio-Visual Speech Recognition with Sparse Modality Alignment and Visual Unit-Guided Refinement
Mar 04, 2026Audio-Visual Speech Recognition (AVSR) integrates acoustic and visual information to enhance robustness in adverse acoustic conditions. Recent advances in Large Language Models (LLMs) have yielded competitive automatic speech recognition performance and shown effectiveness for AVSR. However, prior approaches project audio and visual features independently or apply shallow fusion, limiting cross-modal alignment and complementary exchange while increasing the LLM's computational load. To address this, we propose AVUR-LLM, an LLM-based Audio-Visual Speech Recognition via Sparse Modality Alignment and Visual Unit-Guided Refinement. Experiments on LRS3 demonstrate state-of-the-art results for AVSR. Under additive-noise conditions at 0 dB SNR, it achieves 37% relative improvement over the baseline system.
FingerSplat: Contactless Fingerprint 3D Reconstruction and Generation based on 3D Gaussian Splatting
Sep 19, 2025Researchers have conducted many pioneer researches on contactless fingerprints, yet the performance of contactless fingerprint recognition still lags behind contact-based methods primary due to the insufficient contactless fingerprint data with pose variations and lack of the usage of implicit 3D fingerprint representations. In this paper, we introduce a novel contactless fingerprint 3D registration, reconstruction and generation framework by integrating 3D Gaussian Splatting, with the goal of offering a new paradigm for contactless fingerprint recognition that integrates 3D fingerprint reconstruction and generation. To our knowledge, this is the first work to apply 3D Gaussian Splatting to the field of fingerprint recognition, and the first to achieve effective 3D registration and complete reconstruction of contactless fingerprints with sparse input images and without requiring camera parameters information. Experiments on 3D fingerprint registration, reconstruction, and generation prove that our method can accurately align and reconstruct 3D fingerprints from 2D images, and sequentially generates high-quality contactless fingerprints from 3D model, thus increasing the performances for contactless fingerprint recognition.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
Multi-Channel Sequence-to-Sequence Neural Diarization: Experimental Results for The MISP 2025 Challenge
May 22, 2025This paper describes the speaker diarization system developed for the Multimodal Information-Based Speech Processing (MISP) 2025 Challenge. First, we utilize the Sequence-to-Sequence Neural Diarization (S2SND) framework to generate initial predictions using single-channel audio. Then, we extend the original S2SND framework to create a new version, Multi-Channel Sequence-to-Sequence Neural Diarization (MC-S2SND), which refines the initial results using multi-channel audio. The final system achieves a diarization error rate (DER) of 8.09% on the evaluation set of the competition database, ranking first place in the speaker diarization task of the MISP 2025 Challenge.
Beyond Time: Cross-Dimensional Frequency Supervision for Time Series Forecasting
May 16, 2025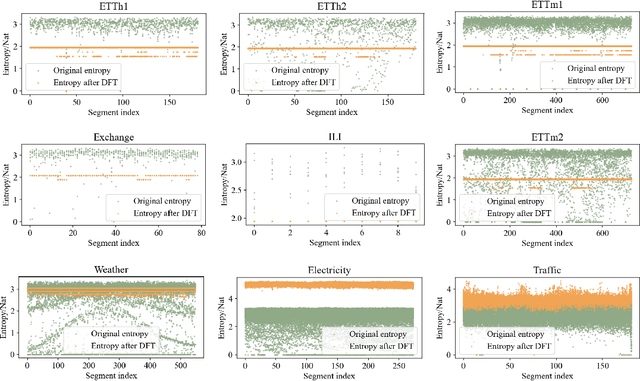
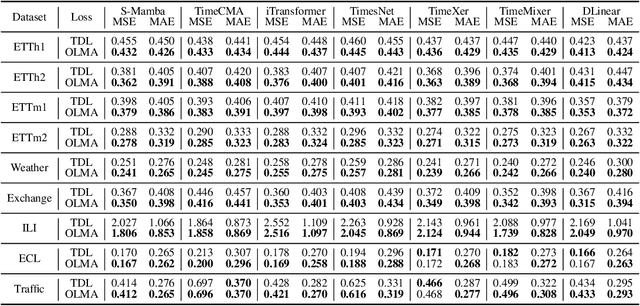
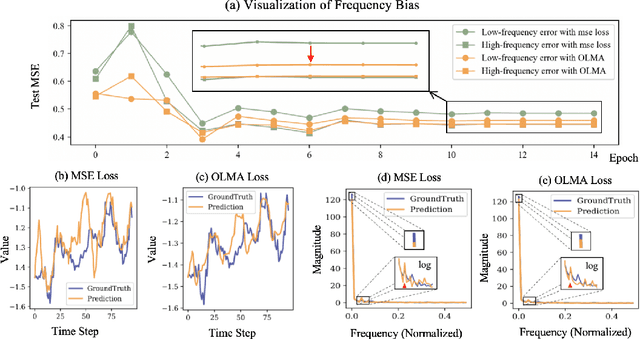
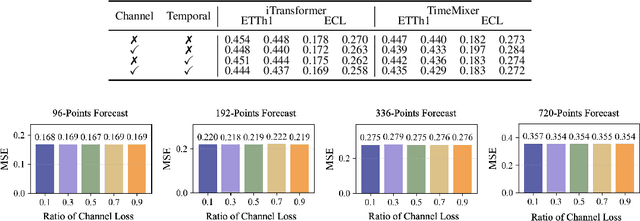
Time series forecasting plays a crucial role in various fields, and the methods based on frequency domain analysis have become an important branch. However, most existing studies focus on the design of elaborate model architectures and are often tailored for limited datasets, still lacking universality. Besides, the assumption of independent and identically distributed (IID) data also contradicts the strong correlation of the time domain labels. To address these issues, abandoning time domain supervision, we propose a purely frequency domain supervision approach named cross-dimensional frequency (X-Freq) loss. Specifically, based on a statistical phenomenon, we first prove that the information entropy of the time series is higher than its spectral entropy, which implies higher certainty in frequency domain and thus can provide better supervision. Secondly, the Fourier Transform and the Wavelet Transform are applied to the time dimension and the channel dimension of the time series respectively, to capture the long-term and short-term frequency variations as well as the spatial configuration features. Thirdly, the loss between predictions and targets is uniformly computed in the frequency domain. Moreover, we plug-and-play incorporate X-Freq into multiple advanced forecasting models and compare on 14 real-world datasets. The experimental results demonstrate that, without making any modification to the original architectures or hyperparameters, X-Freq can improve the forecasting performance by an average of 3.3% on long-term forecasting datasets and 27.7% on short-term ones, showcasing superior generality and practicality. The code will be released publicly.
CPAny: Couple With Any Encoder to Refer Multi-Object Tracking
Mar 10, 2025Referring Multi-Object Tracking (RMOT) aims to localize target trajectories specified by natural language expressions in videos. Existing RMOT methods mainly follow two paradigms, namely, one-stage strategies and two-stage ones. The former jointly trains tracking with referring but suffers from substantial computational overhead. Although the latter improves computational efficiency, its CLIP-inspired dual-tower architecture restricts compatibility with other visual/text backbones and is not future-proof. To overcome these limitations, we propose CPAny, a novel encoder-decoder framework for two-stage RMOT, which introduces two core components: (1) a Contextual Visual Semantic Abstractor (CVSA) performs context-aware aggregation on visual backbone features and projects them into a unified semantic space; (2) a Parallel Semantic Summarizer (PSS) decodes the visual and linguistic features at the semantic level in parallel and generates referring scores. By replacing the inherent feature alignment of encoders with a self-constructed unified semantic space, CPAny achieves flexible compatibility with arbitrary emerging visual / text encoders. Meanwhile, CPAny aggregates contextual information by encoding only once and processes multiple expressions in parallel, significantly reducing computational redundancy. Extensive experiments on the Refer-KITTI and Refer-KITTI-V2 datasets show that CPAny outperforms SOTA methods across diverse encoder combinations, with a particular 7.77\% HOTA improvement on Refer-KITTI-V2. Code will be available soon.
Data-Efficient Generalization for Zero-shot Composed Image Retrieval
Mar 07, 2025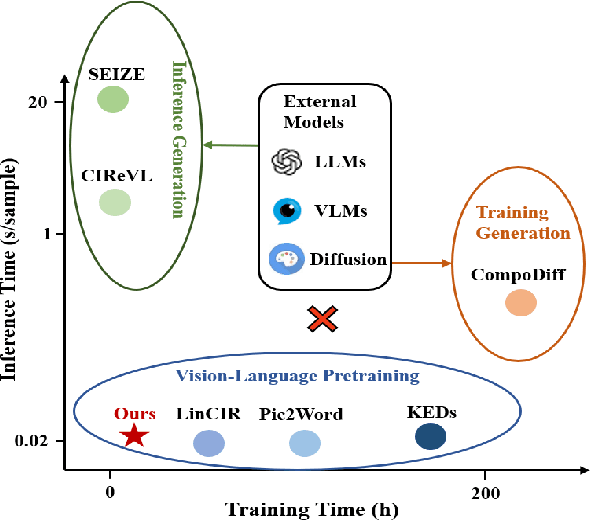
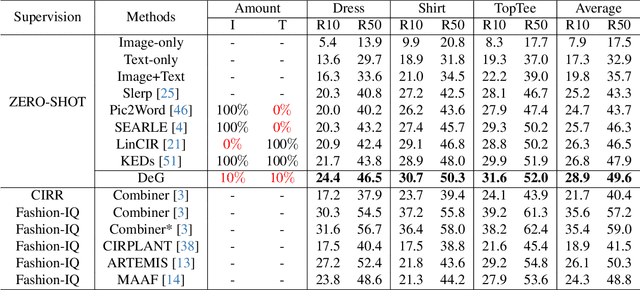
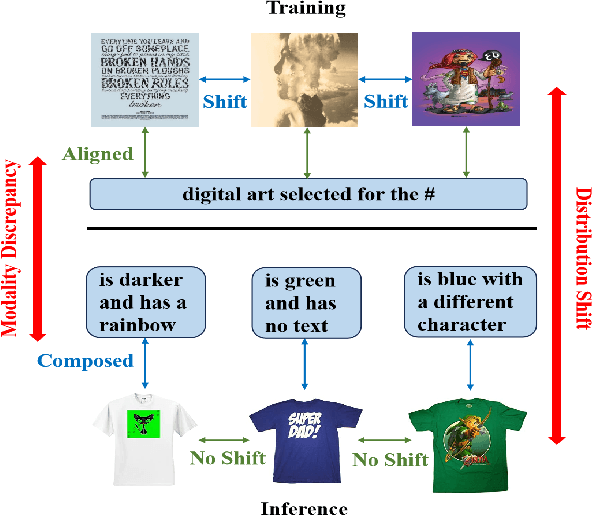
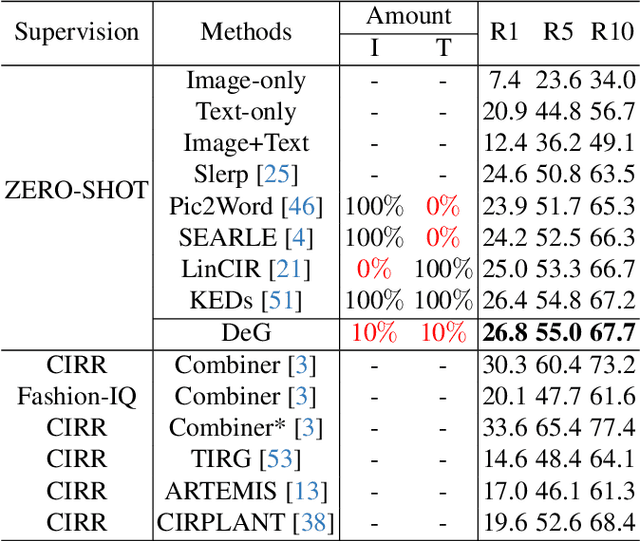
Zero-shot Composed Image Retrieval (ZS-CIR) aims to retrieve the target image based on a reference image and a text description without requiring in-distribution triplets for training. One prevalent approach follows the vision-language pretraining paradigm that employs a mapping network to transfer the image embedding to a pseudo-word token in the text embedding space. However, this approach tends to impede network generalization due to modality discrepancy and distribution shift between training and inference. To this end, we propose a Data-efficient Generalization (DeG) framework, including two novel designs, namely, Textual Supplement (TS) module and Semantic-Set (S-Set). The TS module exploits compositional textual semantics during training, enhancing the pseudo-word token with more linguistic semantics and thus mitigating the modality discrepancy effectively. The S-Set exploits the zero-shot capability of pretrained Vision-Language Models (VLMs), alleviating the distribution shift and mitigating the overfitting issue from the redundancy of the large-scale image-text data. Extensive experiments over four ZS-CIR benchmarks show that DeG outperforms the state-of-the-art (SOTA) methods with much less training data, and saves substantial training and inference time for practical usage.
ICFNet: Integrated Cross-modal Fusion Network for Survival Prediction
Jan 06, 2025



Survival prediction is a crucial task in the medical field and is essential for optimizing treatment options and resource allocation. However, current methods often rely on limited data modalities, resulting in suboptimal performance. In this paper, we propose an Integrated Cross-modal Fusion Network (ICFNet) that integrates histopathology whole slide images, genomic expression profiles, patient demographics, and treatment protocols. Specifically, three types of encoders, a residual orthogonal decomposition module and a unification fusion module are employed to merge multi-modal features to enhance prediction accuracy. Additionally, a balanced negative log-likelihood loss function is designed to ensure fair training across different patients. Extensive experiments demonstrate that our ICFNet outperforms state-of-the-art algorithms on five public TCGA datasets, including BLCA, BRCA, GBMLGG, LUAD, and UCEC, and shows its potential to support clinical decision-making and advance precision medicine. The codes are available at: https://github.com/binging512/ICFNet.
Filter or Compensate: Towards Invariant Representation from Distribution Shift for Anomaly Detection
Dec 13, 2024Recent Anomaly Detection (AD) methods have achieved great success with In-Distribution (ID) data. However, real-world data often exhibits distribution shift, causing huge performance decay on traditional AD methods. From this perspective, few previous work has explored AD with distribution shift, and the distribution-invariant normality learning has been proposed based on the Reverse Distillation (RD) framework. However, we observe the misalignment issue between the teacher and the student network that causes detection failure, thereby propose FiCo, Filter or Compensate, to address the distribution shift issue in AD. FiCo firstly compensates the distribution-specific information to reduce the misalignment between the teacher and student network via the Distribution-Specific Compensation (DiSCo) module, and secondly filters all abnormal information to capture distribution-invariant normality with the Distribution-Invariant Filter (DiIFi) module. Extensive experiments on three different AD benchmarks demonstrate the effectiveness of FiCo, which outperforms all existing state-of-the-art (SOTA) methods, and even achieves better results on the ID scenario compared with RD-based methods. Our code is available at https://github.com/znchen666/FiCo.