 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMET: Concept Space Dissection of the Modality Gap in Audio-Text Multimodal Contrastive Embeddings
May 28, 2026Contrastive Language-Audio Pretraining (CLAP) models are widely used for audio understanding and support modality-agnostic condition swapping in many zero-shot applications. However, their performance is heavily affected by the modality gap between audio and text embeddings. Existing explanations mainly attribute this gap to the cone effect, treating it as a shift between mean embeddings, yet correcting the mean alone yields only limited improvements. Alternative hypotheses, such as information imbalance and dimensionality collapse, have also been proposed, but they remain insufficiently verified and have not been thoroughly studied in the audio domain. Meanwhile, several works attempt to decompose multimodal contrastive embeddings into interpretable concepts, but none explicitly analyze the modality gap from the perspective of concept decomposition. In this work, we introduce COMET (Concept space Organization and Modality gap Explanation with PLS-SVD Transformation), a novel partial least squares singular value decomposition (PLS-SVD) framework for CLAP that unveils a broader perspective of the modality gap. Our framework reveals that only a small, interpretable subset of axes, which captures shared concepts, contributes substantially to similarity computation, and that the mean component represents only partially the modality gap. Building on this insight, we propose a simple spectral truncation method that mitigates the modality gap in a training-free manner. The method enables zero-shot audio captioning with condition swapping to approach fully supervised performance, without requiring large auxiliary memory banks or expensive computation. At the same time, it achieves substantial embedding dimensionality reduction while preserving strong performance on retrieval and audio captioning tasks.
TriDP-PTM: a three-stage distortion-perception tradeoff guides the pre-training model for radar cardiac sensing
May 25, 2026Cardiovascular diseases (CVDs) remain a leading cause of death globally, necessitating continuous, accurate non-invasive cardiac monitoring. While non-contact radar-based approaches show great promise, they often employ a single "distortion-driven" or "perception-driven" paradigm, frequently facing a trade-off between "low distortion but weak semantic information" and "high perceptual fidelity but poor interpretability." To address this, we propose a Three-stage Distortion-Perception Pre-Training Model (TriDP-PTM), a radar-based multi-scale fusion dual-path framework that systematically compares the "direct radar-to-task" path against an "indirect radar-to-ECG-to-task" path. By integrating an ECG generator with a feature discriminator to form a composite loss function, our approach effectively incorporates medical priors - such as ECG morphology and rhythm - into downstream tasks. Through empirical analysis, we reveal that this trade-off manifests in three distinct phases (Positive-Sum, Coopetitive, and Negative-Sum), showing optimal downstream clinical accuracy typically emerges in the coopetitive stage. Extensive experiments on a dataset involving 30 subjects across 5 physiological states reveal that the indirect path consistently outperforms the direct path in diverse tasks, achieving 0.80 mean IoU in waveform segmentation, 98.3% average classification accuracy across four tasks, and a 56% MAE reduction in blood pressure regression compared to the strongest baselines. These findings validate our framework and indicate that, within the indirect radar-to-ECG pathway, appropriately weighting distortion and perception losses to operate in the coopetitive regime is critical for achieving both clinically interpretable ECG morphology and strong downstream accuracy in non-contact cardiac monitoring.
Filter or Compensate: Towards Invariant Representation from Distribution Shift for Anomaly Detection
Dec 13, 2024Recent Anomaly Detection (AD) methods have achieved great success with In-Distribution (ID) data. However, real-world data often exhibits distribution shift, causing huge performance decay on traditional AD methods. From this perspective, few previous work has explored AD with distribution shift, and the distribution-invariant normality learning has been proposed based on the Reverse Distillation (RD) framework. However, we observe the misalignment issue between the teacher and the student network that causes detection failure, thereby propose FiCo, Filter or Compensate, to address the distribution shift issue in AD. FiCo firstly compensates the distribution-specific information to reduce the misalignment between the teacher and student network via the Distribution-Specific Compensation (DiSCo) module, and secondly filters all abnormal information to capture distribution-invariant normality with the Distribution-Invariant Filter (DiIFi) module. Extensive experiments on three different AD benchmarks demonstrate the effectiveness of FiCo, which outperforms all existing state-of-the-art (SOTA) methods, and even achieves better results on the ID scenario compared with RD-based methods. Our code is available at https://github.com/znchen666/FiCo.
Fleximo: Towards Flexible Text-to-Human Motion Video Generation
Nov 29, 2024
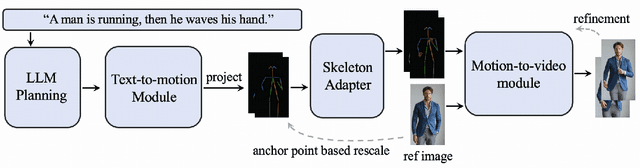


Current methods for generating human motion videos rely on extracting pose sequences from reference videos, which restricts flexibility and control. Additionally, due to the limitations of pose detection techniques, the extracted pose sequences can sometimes be inaccurate, leading to low-quality video outputs. We introduce a novel task aimed at generating human motion videos solely from reference images and natural language. This approach offers greater flexibility and ease of use, as text is more accessible than the desired guidance videos. However, training an end-to-end model for this task requires millions of high-quality text and human motion video pairs, which are challenging to obtain. To address this, we propose a new framework called Fleximo, which leverages large-scale pre-trained text-to-3D motion models. This approach is not straightforward, as the text-generated skeletons may not consistently match the scale of the reference image and may lack detailed information. To overcome these challenges, we introduce an anchor point based rescale method and design a skeleton adapter to fill in missing details and bridge the gap between text-to-motion and motion-to-video generation. We also propose a video refinement process to further enhance video quality. A large language model (LLM) is employed to decompose natural language into discrete motion sequences, enabling the generation of motion videos of any desired length. To assess the performance of Fleximo, we introduce a new benchmark called MotionBench, which includes 400 videos across 20 identities and 20 motions. We also propose a new metric, MotionScore, to evaluate the accuracy of motion following. Both qualitative and quantitative results demonstrate that our method outperforms existing text-conditioned image-to-video generation methods. All code and model weights will be made publicly available.
Poisson Ordinal Network for Gleason Group Estimation Using Bi-Parametric MRI
Jul 08, 2024



The Gleason groups serve as the primary histological grading system for prostate cancer, providing crucial insights into the cancer's potential for growth and metastasis. In clinical practice, pathologists determine the Gleason groups based on specimens obtained from ultrasound-guided biopsies. In this study, we investigate the feasibility of directly estimating the Gleason groups from MRI scans to reduce otherwise required biopsies. We identify two characteristics of this task, ordinality and the resulting dependent yet unknown variances between Gleason groups. In addition to the inter- / intra- observer variability in a multi-step Gleason scoring process based on the interpretation of Gleason patterns, our MR-based prediction is also subject to specimen sampling variance and, to a lesser degree, varying MR imaging protocols. To address this challenge, we propose a novel Poisson ordinal network (PON). PONs model the prediction using a Poisson distribution and leverages Poisson encoding and Poisson focal loss to capture a learnable dependency between ordinal classes (here, Gleason groups), rather than relying solely on the numerical ground-truth (e.g. Gleason Groups 1-5 or Gleason Scores 6-10). To improve this modelling efficacy, PONs also employ contrastive learning with a memory bank to regularise intra-class variance, decoupling the memory requirement of contrast learning from the batch size. Experimental results based on the images labelled by saturation biopsies from 265 prior-biopsy-blind patients, across two tasks demonstrate the superiority and effectiveness of our proposed method.
Camera-Invariant Meta-Learning Network for Single-Camera-Training Person Re-identification
Jun 21, 2024Single-camera-training person re-identification (SCT re-ID) aims to train a re-ID model using SCT datasets where each person appears in only one camera. The main challenge of SCT re-ID is to learn camera-invariant feature representations without cross-camera same-person (CCSP) data as supervision. Previous methods address it by assuming that the most similar person should be found in another camera. However, this assumption is not guaranteed to be correct. In this paper, we propose a Camera-Invariant Meta-Learning Network (CIMN) for SCT re-ID. CIMN assumes that the camera-invariant feature representations should be robust to camera changes. To this end, we split the training data into meta-train set and meta-test set based on camera IDs and perform a cross-camera simulation via meta-learning strategy, aiming to enforce the representations learned from the meta-train set to be robust to the meta-test set. With the cross-camera simulation, CIMN can learn camera-invariant and identity-discriminative representations even there are no CCSP data. However, this simulation also causes the separation of the meta-train set and the meta-test set, which ignores some beneficial relations between them. Thus, we introduce three losses: meta triplet loss, meta classification loss, and meta camera alignment loss, to leverage the ignored relations. The experiment results demonstrate that our method achieves comparable performance with and without CCSP data, and outperforms the state-of-the-art methods on SCT re-ID benchmarks. In addition, it is also effective in improving the domain generalization ability of the model.
PracticalDG: Perturbation Distillation on Vision-Language Models for Hybrid Domain Generalization
Apr 13, 2024



Domain Generalization (DG) aims to resolve distribution shifts between source and target domains, and current DG methods are default to the setting that data from source and target domains share identical categories. Nevertheless, there exists unseen classes from target domains in practical scenarios. To address this issue, Open Set Domain Generalization (OSDG) has emerged and several methods have been exclusively proposed. However, most existing methods adopt complex architectures with slight improvement compared with DG methods. Recently, vision-language models (VLMs) have been introduced in DG following the fine-tuning paradigm, but consume huge training overhead with large vision models. Therefore, in this paper, we innovate to transfer knowledge from VLMs to lightweight vision models and improve the robustness by introducing Perturbation Distillation (PD) from three perspectives, including Score, Class and Instance (SCI), named SCI-PD. Moreover, previous methods are oriented by the benchmarks with identical and fixed splits, ignoring the divergence between source domains. These methods are revealed to suffer from sharp performance decay with our proposed new benchmark Hybrid Domain Generalization (HDG) and a novel metric $H^{2}$-CV, which construct various splits to comprehensively assess the robustness of algorithms. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms on multiple datasets, especially improving the robustness when confronting data scarcity.
EviPrompt: A Training-Free Evidential Prompt Generation Method for Segment Anything Model in Medical Images
Nov 10, 2023



Medical image segmentation has immense clinical applicability but remains a challenge despite advancements in deep learning. The Segment Anything Model (SAM) exhibits potential in this field, yet the requirement for expertise intervention and the domain gap between natural and medical images poses significant obstacles. This paper introduces a novel training-free evidential prompt generation method named EviPrompt to overcome these issues. The proposed method, built on the inherent similarities within medical images, requires only a single reference image-annotation pair, making it a training-free solution that significantly reduces the need for extensive labeling and computational resources. First, to automatically generate prompts for SAM in medical images, we introduce an evidential method based on uncertainty estimation without the interaction of clinical experts. Then, we incorporate the human prior into the prompts, which is vital for alleviating the domain gap between natural and medical images and enhancing the applicability and usefulness of SAM in medical scenarios. EviPrompt represents an efficient and robust approach to medical image segmentation, with evaluations across a broad range of tasks and modalities confirming its efficacy.
Incorporating Pre-training Data Matters in Unsupervised Domain Adaptation
Aug 06, 2023Unsupervised domain adaptation(UDA) and Source-free UDA(SFUDA) methods formulate the problem involving two domains: source and target. They typically employ a standard training approach that begins with models pre-trained on large-scale datasets e.g., ImageNet, while rarely discussing its effect. Recognizing this gap, we investigate the following research questions: (1) What is the correlation among ImageNet, the source, and the target domain? (2) How does pre-training on ImageNet influence the target risk? To answer the first question, we empirically observed an interesting Spontaneous Pulling (SP) Effect in fine-tuning where the discrepancies between any two of the three domains (ImageNet, Source, Target) decrease but at the cost of the impaired semantic structure of the pre-train domain. For the second question, we put forward a theory to explain SP and quantify that the target risk is bound by gradient disparities among the three domains. Our observations reveal a key limitation of existing methods: it hinders the adaptation performance if the semantic cluster structure of the pre-train dataset (i.e.ImageNet) is impaired. To address it, we incorporate ImageNet as the third domain and redefine the UDA/SFUDA as a three-player game. Specifically, inspired by the theory and empirical findings, we present a novel framework termed TriDA which additionally preserves the semantic structure of the pre-train dataset during fine-tuning. Experimental results demonstrate that it achieves state-of-the-art performance across various UDA and SFUDA benchmarks.
Causality-based Dual-Contrastive Learning Framework for Domain Generalization
Jan 22, 2023Domain Generalization (DG) is essentially a sub-branch of out-of-distribution generalization, which trains models from multiple source domains and generalizes to unseen target domains. Recently, some domain generalization algorithms have emerged, but most of them were designed with non-transferable complex architecture. Additionally, contrastive learning has become a promising solution for simplicity and efficiency in DG. However, existing contrastive learning neglected domain shifts that caused severe model confusions. In this paper, we propose a Dual-Contrastive Learning (DCL) module on feature and prototype contrast. Moreover, we design a novel Causal Fusion Attention (CFA) module to fuse diverse views of a single image to attain prototype. Furthermore, we introduce a Similarity-based Hard-pair Mining (SHM) strategy to leverage information on diversity shift. Extensive experiments show that our method outperforms state-of-the-art algorithms on three DG datasets. The proposed algorithm can also serve as a plug-and-play module without usage of domain labels.